最高のAIワイフ生成ツール2026年版: 完全に一貫性のあるアニメキャラクターを作成する
2026年最高のAIワイフ生成ツールの完全ガイド。AnimagineXL、NovelAI、Pony Diffusion、FLUX animeのLoRA、IPAdapterワークフローを使用して、一貫性のあるアニメキャラクターを作成する方法を学びます。

2年以上にわたってAIでアニメキャラクターを生成してきましたが、2026年の風景は私が始めた当初の姿とは全く異なっていることを確実に言えます。2024年初頭は、アニメチェックポイントを起動して「1girl, blue hair, school uniform」とタイプして、出力したものがあなたの頭の中にあるものをかすかに反映していることを祈るだけでした。一貫性は全くありませんでした。10枚の画像を生成すると、髪の色を共有しているだけの10人の全く異なるキャラクターが出てきました。それは本当に不満でしたし、正直に言うと、AI アニメアートを完全に諦めそうになっていました。
しかし、私はそれを続けました。そして、そうして良かったと思っています。一貫性のあるワイフキャラクターを作成するための今のツールは、本当に印象的です。ビジュアルノベルを構築している場合、ウェブコミックを作成している場合、キャラクターアカウントを運営している場合、または単に数十の画像全体でOCを同じに見えるようにしたい場合でも、実際に機能する本当の解決策があります。私はそれら全てを徹底的にテストしており、このガイドは数百時間の実験の結果です。
簡潔な回答: 2026年の一貫性のあるアニメキャラクターのための最高のAIワイフ生成ツールは、一般的なアニメアートはAnimagineXL 4.0、最大の柔軟性はAnimagineXL 4.0、最大の柔軟性はFLUXとアニメLoRA(特にIllustriousXLベースのもの)で、最も簡単にすぐに使える体験はNovelAI V4です。複数の画像全体で真のキャラクター一貫性を得るには、これらのベースジェネレータをIPAdapter forアニメと組み合わせるか、キャラクター固有のLoRAを訓練する必要があります。Pony Diffusion V7は、その許容的な訓練データでNSFWコンテンツの最良のオプションのままです。
- AnimagineXL 4.0は最もクリーンなアニメアートを生成し、優れたタグ理解がありますが、複数画像の一貫性にはIPAdapterまたはLoRAが必要です
- FLUX anime LoRAは2026年初頭時点でSDXLチェックポイントを品質と柔軟性で上回りました
- NovelAI V4は最高のターンキー体験を提供しますが、ローカル生成オプションなしでそのエコシステムにロックインされます
- Pony Diffusion V7はその広い訓練データとタグシステムでNSFWアニメコンテンツで主導しています
- アニメ固有の参照画像を備えたIPAdapterはLoRA訓練なしで一貫性への最速の道です
- キャラクターLoRAを訓練するのに30分から60分かかりますが、長期プロジェクトのために最も信頼できる結果を提供します
- Lewdly.aiワークフローはパイプラインに組み込まれたキャラクター一貫性ノードを使用してアニメ生成を処理できます
AIアニメ生成が初めてなら、私のAI アニメ生成ガイドは基本をカバーしています。この記事はこの一貫性の問題について深く掘り下げています。これは大ほどの人々が立ち往生する場所です。
アニメAIアートで、キャラクター一貫性はなぜこんなに難しいのか
ツールに進む前に、この問題が最初の場所になぜ存在するのかを理解するのに役立ちます。これは単なるソフトウェアの問題ではありません。これらのモデルがどのように機能するかの中心にある根本的な緊張があり、それはアニメの一貫性を特に複雑にします。
拡散モデルは数百万の画像から学習します。モデルが「青い髪」というタグを見るとき、その色合い、髪型、顔の形、目のデザインが微妙に異なる青い髪を持つ数千の異なるキャラクターを見ました。ですから、プロンプトで「青い髪」を求めるとき、モデルは本質的にその学習した分布からランダムに選んでいます。すべての生成は新しいサイコロの目であり、モデルは「最後に生成した特定のキャラクター」の概念を持つことはできません。
この問題は実は写真現実的なコンテンツよりもアニメの方が悪いです。現実的な顔では、モデルは実在する人間の解剖学の構造に頼ることができ、それは出力空間を大幅に制約します。しかし、アニメのキャラクターデザインはその性質上、非常に多様です。目の形は小さな点から顔の半分を占める巨大なお皿まで変わることができます。髪は創造的な方法で物理法則に逆らうことができます。身体の割合は芸術的なスタイル全体で劇的に異なります。モデルは放浪する部屋がはるかに多く、そしてそれはそうします。
2024年に最初に一貫したOCを作成しようとしたことを覚えています。週末全体を、同じキャラクターのはずのアニメ画像を生成することに費やしました。最後に、200枚ほどの画像を得て、同じ人物を描いているように見える1つのペアもありませんでした。同じタグ、同じシード、同じモデル。毎回完全に異なるキャラクター。その時が、プロンプティングだけではこの問題を解決しないということに気づいた時です。

一貫性の問題の可視化: 同じプロンプト、同じモデル、複数の生成全体で野生の異なる結果。
どのAIワイフ生成ツールが最も良いベースの品質を生成するか
最初に基礎から始めましょう。一貫性について心配する前に、まず最初にアニメアートの高品質を生成するジェネレータが必要です。2026年3月に利用可能なすべての主要なオプションをテストしました。

AnimagineXL 4.0
AnimagineXLはそれなりの理由で大流行しています。2026年1月にドロップされた4.0リリースは3.1よりも大きな飛躍であり、手のレンダリングの改善、より一貫した解剖学、そしてbooru スタイルタグの理解の大幅な改善があります。ComfyUIやAutomatic1111をローカルで実行している場合、これはおそらく今はあなたのGo-To チェックポイントです。
Animagineについて私が愛するのはタグの理解です。danbooru タグをそれに投げることができ、それは正確に何を意味するのかを知っています。「1girl, long hair, blue eyes, serafuku, pleated skirt, rooftop, wind」は正確にそれを与えます。推測なし。モデルはアニメアートコミュニティのタギング規則をそれほど深く内在化しており、アニメイメージボードを閲覧したことがあれば、プロンプティングは直感的に感じられます。
欠点は?AnimagineはまだSDXLベースなので、FLUXベースのソリューションと比べて年を取り始めています。全体的な結果はいい感じですが、素晴らしくはなく、複数のキャラクターを持つ複雑なシーンは定期的に崩れ落ちます。単一のキャラクターのポートレートと半身ショットは、しかし、それは優れたままです。
FLUX Anime LoRA (IllustriousXL派生)
ここが私の熱い意見です。良いアニメLoRAを備えたFLUXは、今度は専用のアニメチェックポイントより良いです。私は一部の人々を怒らせることを知っており、私は比較を実行し、結果は自分たちのために話します。
IllustriousXLプロジェクトは、2025年後半にアニメに焦点を当てたFLUXのLoRAsの全体的なエコシステムを生み出し、品質は2026年に登り続けました。NTR Mix FLUX、Hassaku FLUX、そして様々なコミュニティファインチューンのようなモデルは、SDXLがすることができるものより鋭い、より結果的な、そして風情のあるアニメアートを生成します。基礎となるFLUXアーキテクチャは、構成、照明、そして解剖学的な詳細をSDXLより基本的なレベルで処理し、そしてそれの利点はアニメ出力に直接変換します。
トレードオフはスピードとVRAMです。FLUXはSDXLより空腹で、ローカルで実行することはより大きなGPUを必要とします。3060以下の場合は、量子化されたモデルと長い生成時間に見ることになります。しかし、4070以上をお持ちの場合は、FLUXアニメが今マジックが起こっているところです。
NovelAI V4
NovelAIは誰もが別の道を進むことで、ライセンスされた、キュレーションされたアニメデータから傷のあるモデルを訓練することによって別のパスを取りました。V4リリースは本当に印象的です。アート品質は一貫して高い、スタイルの多様性は素晴らしく、タグシステムが美しく機能します。ローカルセットアップを微調整したくないときの迅速なキャラクターの概念に対して、私は使用しました。
象の部屋はNovelAIが閉鎖されたエコシステムであるということです。あなたはモデルをダウンロードできません。ローカルで実行できません。ComfyUIワークフローに統合することができません。彼らのウェブインターフェイスやAPI経由で生成することです、期間。一部の人にとって、それはディールブレーカーです。他の人たちのために、彼ら自分自身の前提をいじくり回さずに素晴らしいアニメアートを望む人のために、それはちょうど彼らが望むものです。
価格設定は、プレミアムティアで月額約25ドルで、ほとんどの個人プロジェクトのための十分な生成を与えます。あなたが高容量の仕事をしている場合、それは急速に追加されます。これはLewdly.aiでのローカルソリューションがバッチ生成のために特に多くの金銭的意味を作り始めるところです。
Pony Diffusion V7
Ponyはそのニッチをカットアウトし、どこにも行っていません。V7リリースはPonyが最高である洗練もの:多目的なアニメアート、許容的な訓練データ、NSFWコンテンツから尻込みしません。タグシステムは、他のモデルが一致できない方法で品質レベルを見える独自のスコアベースの品質プロンプト(「score_9, score_8_up, score_7_up」)を使用します。
正直に言う、私は最初にPonyを「NSFW モデル」として却下し、深刻に取りませんでした。それは間違いでした。SFWキャラクターデザイン作業の場合、Pony V7は、多くのアーティストが優先する独特のスタイルで本当に素晴らしい結果を生成します。キャラクターデザインの多様性は素晴らしく、モデルは私のテストでAnimagineより複雑な衣装とアクセサリーを処理します。
どのようにしてキャラクター一貫性を実現するか
これはゴムが道路に満たすところです。素晴らしいベースジェネレータを持つことはステップ1ですが、同じキャラクターが複数の画像全体に認識可能に表示されるようにするための追加の技術が必要です。2026年に実際に機能するアプローチを最も簡単なものから最も信頼できるものまでランク付けしました。
方法1: アニメ用IPAdapter
IPAdapterは一貫性を得る最速の方法であり、トレーニングなし。あなたは1つ以上のキャラクターの参照画像をフィードし、それはジェネレーションをガイドして視覚的な類似性を維持します。過去1年で出現したアニメ固有のIPAdapterモデルはこのユースケースのための汎用のものより大幅に優れています。
ここが私が通常ComfyUIでそれを設定する方法です。IPAdapterプラスのカスタムノードパック、アニメ固有のIPAdapterモデル(私はアニメファインチューニングでIP-Adapter-FaceID-Plus-V2を推奨)、および高品質の参照画像の良いセットが必要です。
ワークフローは以下のようになります:
- あなたのキャラクターの3〜5つの高品質な参照画像を生成または作成します
- それらをIPAdapter参照ノードにバッチとして読み込みます
- ウェイトを0.7〜0.85に設定します(高すぎると参照をコピーするだけで、低すぎるとそれを無視します)
- それをメインジェネレーションパイプラインに接続します
- ベースモデルとしてあなたの通常のアニメチェックポイントまたはLoRAを使用します
強さ設定は大ほどの人々が台無しにするところです。私は「IPAdapterはアニメに対して機能しない」と言う人からのフォーラムの投稿を多く見てきており、毎回、彼らはウェイトを1.0にクランクしており、これは参照画像のぼやけたコピーを生み出します。あなたはモデルが参照に奴隷化されるのではなく、それに啓発されたいです。0.7と0.85の間は、数か月のテストの後で私が見つけた甘い場所です。
IPAdapterがアニメの仕事について本当に愛することは、それが大幅にポーズを変えた場合でも、キャラクターの「感じ」を保存することです。私はコミックプロジェクトのために開発していたキャラクターで広範囲にテストしました。同じ参照画像ですが、立っている、座っている、走る、寝ているのでプロンプト化。キャラクターはそれら全てで認識可能であり続けました。同じではありませんでした。正確な髪のスタイリングと目の詳細にはまだ小さな変動がありました。しかし認識可能に同じキャラクターで、それは重要なことです。
アニメを越えて一貫性の技術についてより深いダイブをしたい場合は、IPAdapterおよび他の方法をより詳しくカバーする私のAIキャラクター一貫性ガイドをチェックアウトしてください。
方法2: キャラクターLoRA訓練
長期のプロジェクトのための防弾一貫性が必要な場合、キャラクター固有のLoRAを訓練することは金標準です。他は何も近づいてきません信頼性のために。この時点で私は数十のキャラクターLoRAを訓練しており、プロセスは過去1年で劇的に簡単になっています。
ここがあなたが必要なものです:
- あなたのキャラクターの10〜20の高品質な画像(あなたはPhotoshopまたはClip Studioで洗練されたAI生成されたものを使用できます)
- LoRA訓練ツール(私はkohya_ssまたはLewdly.aiのビルトイン訓練器を使用します)
- 4080または同等のGPU時間の約30〜60分
- 最初の試みのための忍耐(一度設定を学ぶと、それは速くなります)
アニメキャラクターのトレーニングプロセスは実際に現実的な顔よりも単純です。アニメのキャラクターはより独特な視覚的マーカーを持ちます(具体的な目の形、髪のデザイン、アクセサリー) LoRAはすぐに拾います。私は通常1500〜2500ステップの学習率1e-4で訓練し、結果は通常2000ステップが十分です。
無料のComfyUIワークフロー
この記事のテクニックに関する無料のオープンソースComfyUIワークフローを見つけてください。 オープンソースは強力です。
ここで私が難しい方法を学んだ重要なヒント。あなたの訓練画像は異なる角度から複数の照明条件でキャラクターを示す必要があります。あなたが正面を向くポートレートでのみ訓練した場合、LoRAは正面を向くポートレートのためだけに機能します。私は最初の3つのLoRA試みでこの間違いをし、側面ビューショットで私のキャラクターが完全に異なるのはなぜ見分けることができません。あなたの訓練データに少なくとも3〜4つの異なる角度を含めてください。
十分に訓練されたキャラクターLoRAの美しさは、それが異なるベースモデル全体で機能することです。あなたはAnimagine、Pony、または偶数ある種のFLUXセットアップ(アダプタレイヤー付き)で同じLoRAを使用できます。あなたのキャラクターは関係なくどのアート風のジェネレーションされているかのために一貫したままです。それは異なる美学を実験しながらキャラクター化を維持したいクリエーターのためにとても力強いです。
LoRA訓練プロセスの完全なウォークスルーのために、スクリーンショット付きのステップバイステップの指示を持つ私のAIの一貫した キャラクター生成ガイドを参照してください。
方法3: シードロック化とプロンプトエンジニアリング
これは最も単純なアプローチですが、最も信頼できるのではなく、それはそれが無料で追加の設定を必要としないので覆う価値があります。あるアイデアは率直です: あなたのプロンプトで非常に詳細なキャラクターの説明を使用し、シードをロックして変動を減らします。
「anime girl, blue hair」のような裸のプロンプトは野生の異なる結果を与えます。しかし、「1girl, long straight blue hair reaching waist, large emerald green eyes, small nose, thin eyebrows, heart-shaped face, fair skin, wearing white sailor uniform with blue collar and red ribbon, hair clip on left side」のような詳細なプロンプトは十分な出力スペースを制約して、結果をより一貫した結果を得ます。
シードロック化(生成全体で同じシード数を使用)でこれを組み合わせ、そしてあなたはシンプルなポーズ変更のための驚くほど一貫した結果を得ることができます。主要な構成の変更は生き残りません、しかし表現シートまたはマイナーな角度の変動のようなもの、それはうまく十分に機能できます。
私は迅速なプロトタイピング越えた何かのための一貫性のために主要な方法として勧めません。それは非常にもろいです。あなたのプロンプトの1つの単語を変更して、全体のキャラクターは移行します。しかし、それは迅速なプロトタイピングのための道具箱にすべきなあると言う便利な技術です。
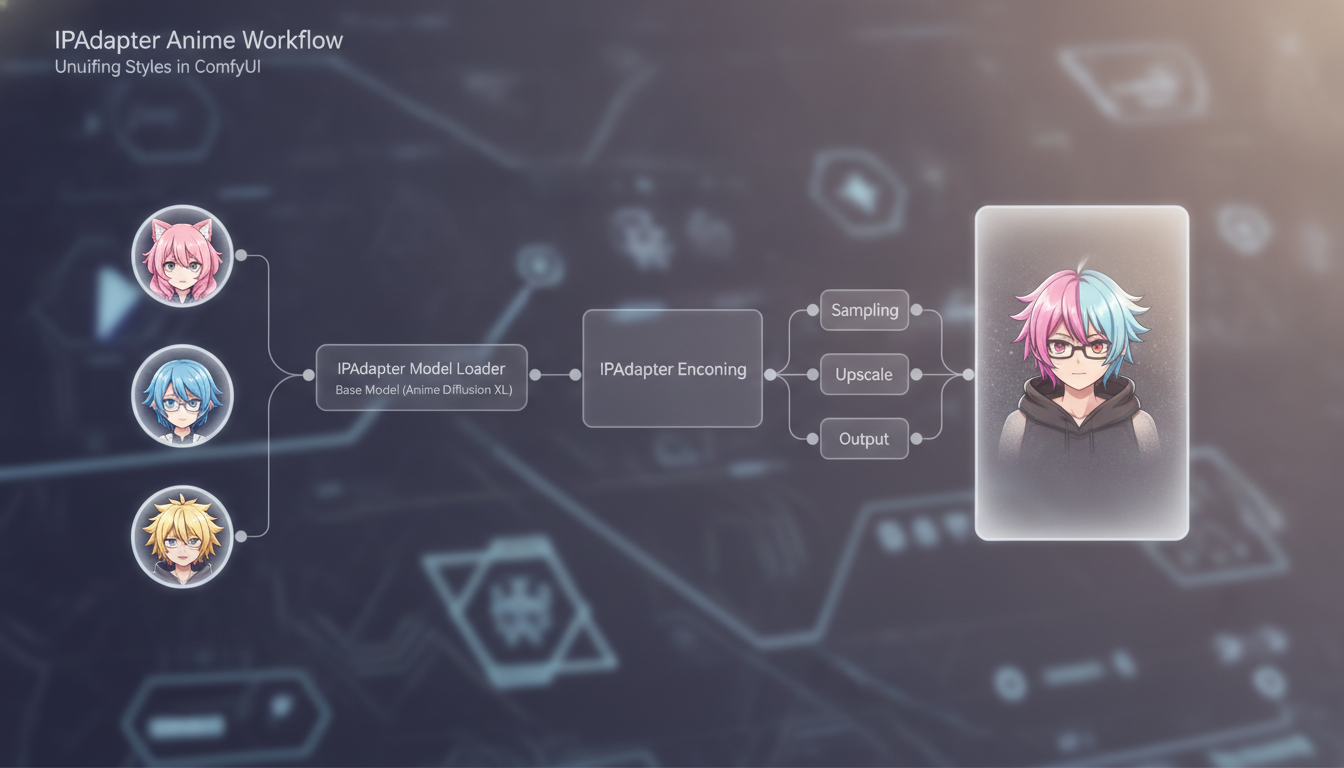
アニメキャラクター一貫性のためのIPAdapterワークフロー: 左側の参照画像、右側の一貫した出力。
2026年の最も良い無料ワイフジェネレータは何か
バジェットは重要であり、誰もがNovelAIに支払うか、ローカル生成のためのビッグなGPUに投資したいわけではありません。良いニュースは、フリーオプションが素晴らしく良くなっています。ゼロの予算で始める場合の推奨事項は、ここです。
Pixai.art はアニメ生成のための最強の無料プラットフォームの1つであり続けます。彼らは無料層で毎日のクレジットとモデル選択を提供し、ほとんどのポピュラーなアニメチェックポイントを含みます。一貫性ツールは無料層で限られていますが、ベースの生成品質は優れています。私は地元のリグを設定する前に約3か月間排他的にPixaiを使用し、個人プロジェクトで十分以上でした。
Google Colab ノートブックは別の無料オプションの場合は技術セットアップの少しを気にしません。複数のコミュニティメンバーは、Google の無料GPU層でAnimagineXL、Pony、そして偶数ある種のFLUXモデルを実行できるようにする更新されたColabのノートブックを維持します。セッションは時間制限され、あなたは数時間後に切断されます、しかし、バースト生成セッションは素晴らしく機能します。
CivitAI のオンラインジェネレータ も著しく改善しました。彼らはこのガイドで私が述べたほとんどのモデルをサポートし、毎日の無料のクレジットを提供します。ピーク時間中のキューの時間は痛い可能性があります、しかし、品質の場合は、あなたはあなたの生成を得る場合、ローカルに匹敵しています。
正直な推奨事項は何か。あなたが深刻なアニメのキャラクター作成について、最終的にローカルセットアップに投資します。クレジット、キューズ、またはコンテンツフィルターなしでのジェネレーションの自由は、先払い費用の価値があります。Lewdly.aiを通じてワークフローを実行することは、独自のハードウェアが必要なくたクラウドGPUアクセスを与え、無料層とローカルリグの構築の間の堅いミドルグラウンドです。
あなたのキャラクターのための正しいアート風をどのように選択するか
アート風は多くの初心者をトリップアップします。彼らは20の異なるスタイルで素晴らしいアニメアートを見て、それらのすべての中で同時に機能させるにはキャラクターを行おうとします。それは始めから矛盾からのレシピです。
複雑さをスキップしたいですか? Lewdly は、技術的なセットアップなしでプロフェッショナルなAI結果を即座に提供します。

ここが私の2番目のホット意見です: 何か他のことの前に1つの主要なスタイルを選んで、少なくともあなたの最初の50〜100キャラクター画像のための結果に固執します。あなたは固いリファレンスセットがあるとき後で分岐できますが、日1から野生の異なる美学全体で一貫性を維持しようとするのは、フラストレーション自分自身を設定しています。
AIの生成で出会うメジャーなアニメアート風カテゴリーです:
- モダンアニメ(Makoto Shinkai-influenced): クリーン線、活気のある色、詳細な背景、リアルな照明。AnimagineXLは素晴らしくこれを扱います。
- 古典的なアニメ(90年代/2000年代美学): より単純なシェーディング、より鋭い眼、より様式化された割合。Pony Diffusionは正しいプロンプティングで優れています。
- 光ノベルイラストスタイル: ソフト着色、夢心地の照明、キャラクター美の強調。NovelAI V4はこれを一貫して釘付けにします。
- マンガパネルスタイル: 黒と白または制限された色、強力なアートワーク、ドラマチックな構成。FLUXは特定のマンガLoRA付きは現在のリーダーです。
- Chibi/超変形: 誇張された割合、簡略化された特性、かわいい美学。最もモデルは正しいタグで良くこれを処理します。
私は私の主要なキャラクタープロジェクトのためのモダンアニメスタイルに定住しました, そのため、シーンの最も広い範囲で最良の結果を与えました。背景の品質はストーリーテリングのために多くのマターと、Shinkai-influenced モダン風は電流AI モデルのあらゆる他のアニメ美学より環境を処理します。
1つの実用的なヒント: あなたの「ゴールデン」の生成を保存します。それでも完全にあなたのキャラクターの見方をキャプチャする出力をいつ得たら、参照フォルダーで別に保存します。20〜30のこれらのゴールデン画像の後で、あなたはIPAdapterまたはLoRA訓練のためにインクレディブルな参照セットを持つでしょう。私は私が機能する各キャラクターのために専用のフォルダーを保つ、そして無限のリジェネレーション時間を私を保存してきました。
完全なキャラクターシートワークフローの構築
ゼロから一貫性のあるキャラクターを作成するための私の実際のワークフローをあなたを通すか歩きましょう。これは過去1年の間に私が洗練したプロセスであり、私が述べたジェネレータのいずれでも信頼できるに機能します。
フェーズ1: キャラクターデザイン(1〜2時間)
粗いコンセプトの生成で始まります。好みのジェネレータで詳細なテキストプロンプトを使用してデザインを異なるに探検してください。一貫性についてまだ心配しないでください。50〜100の画像を生成し、髪型、目の色、衣装、およびアクセサリーを変動させます。あなたが望むアイデアをキャプチャしている5〜10画像を桜ピックします。
私は通常のためこのフェーズのAnimagineXLで始まります, なぜなら、タグの理解は迅速に反復を可能にします。1か2つのタグをバッチを実行し、バッチの間でいじることは、デザイン好きのに組み集まるまで、8つのイメージのバッチを実行します。
フェーズ2: リファレンスセット作成(2〜3時間)
あなたの桜ピックされた画像を取得し、それらの洗練。私はClip Studio Paintを使用して、解剖学的な問題を修正し、色を標準化し、すべての参照画像全体でキャラクター詳細マッチを確保します。あなたが欲しいのは、以下を表示する15〜20のクリーン参照画像です:
- 正面の顔、3/4ビュー、およびプロフィール
- フルボディの前面と背面
- 3〜4つの異なる表情
- 2〜3つの異なる衣装
- 少なくとも1つのアクションポーズ
このリファレンスセットは、続く全て後ろの基礎です。ここで時間を支出するのは、指数関数的に多くの時間を後に節約します。私はこれを十分にストレスできません。私は以前このフェーズを急いだし、ダウンストリーム内の日数の一貫性がない出力で払いました。
フェーズ3: 一貫性メソッドセットアップ(30分〜2時間)
あなたのプロジェクト範囲に基づいて一貫性のアプローチを選択します:
コンテンツ制作で月$1,250以上稼ぐ
独占クリエイターアフィリエイトプログラムに参加。バイラル動画のパフォーマンスに応じて報酬。自分のスタイルで完全な創造的自由を持ってコンテンツを作成。
- クイックプロジェクト(20画像以下): あなたのリファレンスセットを持つIPAdapter。速度のセットアップ、適切な一貫性。
- 中程度のプロジェクト(20〜100画像): キャラクターLoRAを訓練します。セットアップするのに長いかかりますが、すぐに配当を支払います。
- 長期プロジェクト(100+画像): LoRA AND IPAdapterを組み合わせます。ベルトとサスペンダーのアプローチ。これは私が任意の深刻なプロジェクトのための実施しています。
フェーズ4: 製造生成
一貫性パイプラインセットアップで、あなたは製造画像を生成し始めることができます。私は通常16〜32画像のバッチで生成し、最高のものをオフにチェリピックし、そして後続のバッチのための追加のIPAdapter参照として使用しています。これは、一貫性の時間改善のある円形の肯定的フィードバックループを作成します。
全体のプロセスはLewdly.aiのプリビルトワークフローとして利用可能であり、あなたは技術的な配管ではなく創意的な決定に焦点を充当できるように、ComfyUIノード設定を処理します。
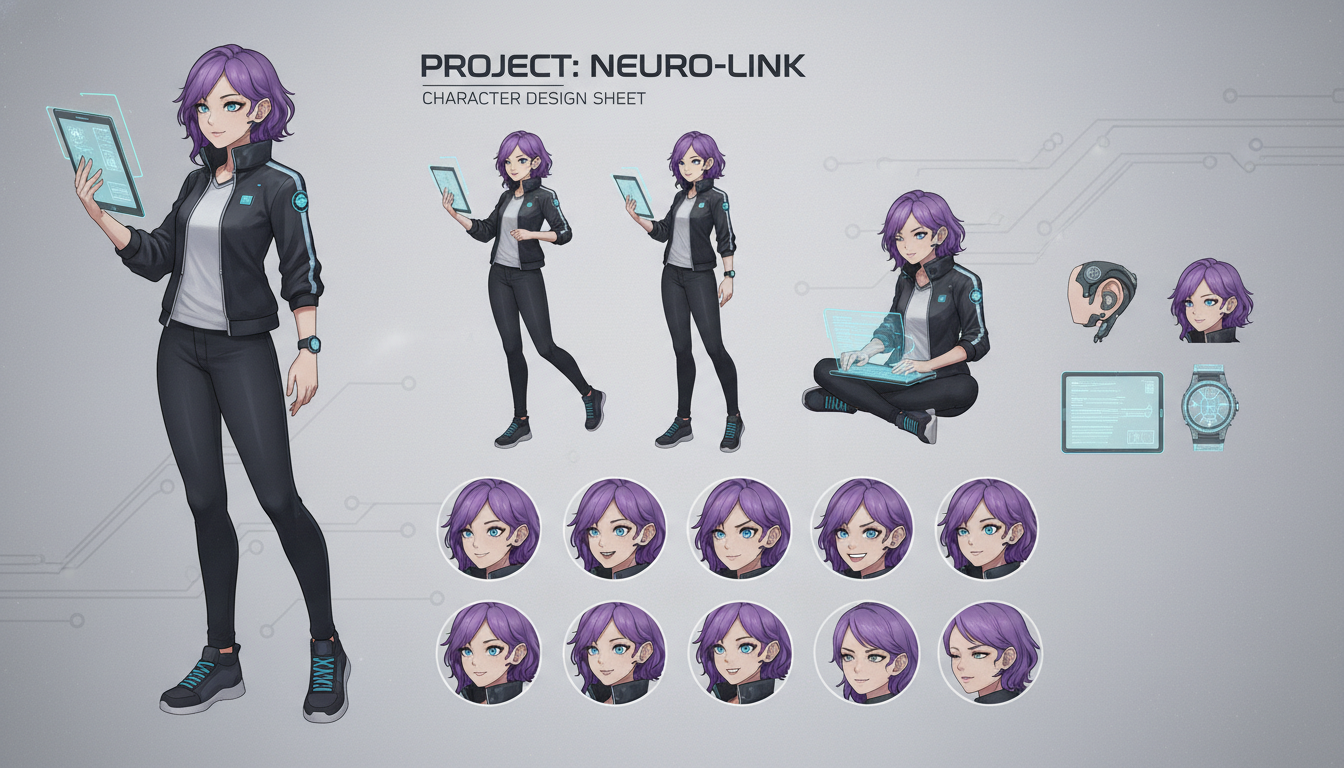
LoRA plus IPAdapterメソッドを使用して生成された修了キャラクターシートで、ポーズと表情全体で一貫したデザインを示しています。
アニメキャラクター一貫性のための高度なヒント
基本を持つ持つ持つとき、ここは一貫性を次のレベルに取る高度な技術です。
ControlNet ポーズガイダンス
ControlNet OpenPoseを一貫性メソッドと共に使用することは、化身のなしで正確なキャラクターのポーズング制御を与えます。私はポーズ参照(DesignDollのような3Dポーズングツールまたはアニメスクリーンショット)のライブラリーを作成し、IPAdapterまたはLoRAがキャラクター化を処理しながら構成をガイドするにはそれらを使用します。
ポーズの場合ControlNetプラス化身のための合成は非常に強力です。あなたは本質的に、モデルに「この具体的なポーズでこの具体的なキャラクターを引く」と言う、そして両方のシステムを見劣りしたときに、結果は、人間のアーティストが生成されるものに驚くほど近いです。
ADetailerを持つ顔詳細
偶数、最も良い一貫性メソッドは時々参照からわずかに浮動する顔を生成します。ADetailer(After Detailer)は、2番目のパスを検出された顔で具体的に実行し、より高い忠実度で再生成します。アニメキャラクターのために、私はアニメの顔の検出モデルを使用し、ベース画像よりも高い解像度で顔を再生成する設定します。
この単一の技術は私のキャラクター一貫性を30〜40%改善したと思います。最初の生成は本体、ポーズ、および構成権を得ます、そして次にADetailerは顔をあなたの参照により近く一致するよう洗浄します。それはイメージごとに約5秒を生成時間に追加し、あなたが得る改善のための何もありません。
色パレットロック化
1つの細かい一貫性の問題を人々が見落とす色浮遊です。あなたのキャラクターのブルーの髪は、異なる生成全体で濃紺、紺、そして紺の間に移動できます。これを修正するには、私はキャラクター参照と共に色参照画像を使用します。私のキャラクターの髪、眼、皮膚、およびアウトフィット色のための正確な16進値を示す単純な色パレットサッチを作成し、IPAdapter参照バッチに含みます。
それは単純に聞きます, なぜなら、それが、しかし、それは顕著な違いを作成し、特に長い生成セッション全体で浮遊が蓄積する傾向がある場合です。
避けるべき一般的な誤り
私は本を本当に誤りをすべてしてきたので、あなたはする必要がありません。ここはアニメAIコミュニティで最も見ている罠です。

プロンプトオーバーロード。 より多いタグはより多くの一貫性を意味しません。約30〜40つのタグの後で、ほとんどのモデルはそれらを無視するか混乱させ始めます。必須の化身特性にあなたのキャラクター記述を保持し、モデルが残りを埋めるようにします。
IPAdapterのための多くの参照画像を使用する。 3〜5つの高品質な参照は毎回20の平凡なアウトパフォーム。モデルは参照を平均し、あなたの参照がお互いに不一貫である場合、出力はぼやけた妥協です。品質オーバー量。
否定的なプロンプトを無視する。 良い否定的なプロンプトはアニメの生成のための戦いの半分です。私はいつも「bad anatomy, extra fingers, mutated hands, poorly drawn face, blurry, low quality, worst quality, normal quality, jpeg artifacts, signature, watermark, username」をベースラインで含みます。それは過度に聞きますが、これらのタグのそれぞれは引っ張られています。
シード試験フェーズをスキップします。 異なるシードは、あなたのプロンプトおよび参照と異なって相互に作用します。私は生成バッチをコミットする前に10〜20のシードを常にテストします。一部のシードはピリオド特定のキャラクター型のより良い結果を一貫して生成し、あなたの「ゴールデンシード」を見つけることは5分のテストの価値があります。
あなたのワークフローを保存しない。 このハーフラント持つ。私はかつて完全な生成設定を得るために夜全体を支出し、200の画像を生成しました, そしてその後、ワークフロー保存なしでComfyUIを閉じました。私は翌日に戻ってきたとき、私は正確にそれらの設定を再作成することができませんでした。今、私は各主要なパラメータ変化の後に保存します。痛みから学びます。
よくある質問
初心者のための最高のAIワイフジェネレータはどれか
NovelAI V4は最も簡単な開始地点です, なぜなら、ゼロの技術的なセットアップが必要です。あなたサインアップ、プロンプトタイプ、そして高品質のアニメアートを得ます。初心者のために技術的なサイドを学びたい人のために、AnimagineXLを通じてLewdly.aiのようなプラットフォームは品質と学習の機会のバランスを提供します。
AIでNSFWアニメキャラクターを作成できるか
はい。Pony Diffusion V7はNSFW アニメコンテンツのための最もポピュラーなオプションです, なぜなら、その訓練データは大人のマテリアルを除外しません。NovelAIは、彼らのプレミアムティアでもNSFW生成をサポートします。大ほどの無料プラットフォームはNSFWコンテンツを制限するので、ローカル生成または有料サービスはあなたの最高の賭けです。
一貫したキャラクターのための参照画像はいくつ必要か
IPAdapterのために、3〜5つの高品質な参照画像が最適です。LoRA訓練のために、あなたの異なるのポーズで異なる角度から見えるキャラクターを見る15〜20画像を目指します。より多くは常により良くはありません。あなたの参照の品質と多様性は、量より問題です。
AnimagineXLはアニメのためにFLUXより良いか
純粋なアニメスタイルの遵守とタグの理解のために、AnimagineXLはまだわずかに先です。しかし、FLUX with アニメLoRAsは、全体的なイメージの品質、構成、および解剖学的な正確さを生成します。2026年のための私の推奨は、FLUXをあなたのプライマリとして使用し、特定のスタイル要件のためにAnimagineXLを保つことです。
キャラクターLoRAを訓練するのにどのくらい時間がかかるか
現代的なGPU(RTX 4080または同等)で、15〜20の訓練画像で2000ステップで基本的なキャラクターLoRA で30〜60分を予想します。RunPodやLewdly.aiのようなサービスを通じたクラウド訓練は約同じ時間を取ります。最初のデータセットの準備は通常の訓練自体より多くの時間を取ります。
異なるアニメアートスタイル全体で同じキャラクターを使用できるか
はい、しかし、それは十分に訓練されたLoRAを要求します。キャラクターLoRAはあなたのキャラクターの必須の視覚的化身をキャプチャし、異なるベースモデルとスタイル全体で適用できます。IPAdapterアロンはクロススタイル一貫性で苦労します, なぜなら、参照画像の視覚的特徴により多くの賭けるからです。
アニメキャラクターはどの解像度で生成するべきか
SDXL ベースのモデル(AnimagineXL、Pony)のために、1024x1024または832x1216(ポートレート)で生成します。FLUXモデルのために、1024x1024は標準ですが、十分なVRAMで1280x1280にプッシュできます。常にモデルのネイティブ解像度で生成し、最良の結果のためにその後にアップスケーリングします。
AI アニメ生成のためにビッグなGPUが必要か
SDXL モデルのために、GPUは8GB VRAMで必要最小限です(RTX 3060 8GB または RTX 4060のような)。FLUX モデルのために、12GB VRAMが推奨されます(RTX 3060 12GB または RTX 4070)。あなたが適切なGPUを持っていない場合、クラウドサービスは先払い投資なしで強力なハードウェアへアクセスを提供します。
私のキャラクターで一貫性のない眼の色を修正する方法
眼の色浮遊は最も一般的な一貫性の問題の1つです。あなたのプロンプトで正確な眼の色を指定してください(例えば、単に「緑の眼」ではなく「エメラルド色の眼」)、あなたのIPAdapter参照に絞込座る顔ショットを含め、そして目の特定の強調で再生成する顔にADetailerを使用することを考えてください。永続的な問題のために、負のプロンプト変動(例えば、あなたのキャラクターが緑の眼を持つ場合、否定的に「青の眼」)にキャラクターの眼の色を追加することは助けることができます。
ワイフジェネレータと規則的なAI画像生成ツールの違いは何か
機能的に、最も「ワイフジェネレータ」は、アニメに焦点を当てたモデルまたはLoRAsを使用した標準的なAI画像生成ツールだけです。WaifuLabsまたは特定のオンラインツールのような専用ワイフジェネレータは、シンプルなインターフェイス層とアニメキャラクター作成のための事前に調整された設定を使用しますが、彼らは通常少ないコントロールと正しいComfyUI設定でより低い品質を提供しますアニメのチェックポイント。
最後に
アニメAI生成のシーンは劇的に成熟し、一貫性のあるワイフキャラクターを作成することはそのために悪夢ではなくなっています。ツールは存在します。技術は証明されます。コミュニティは難しい問題の図をしました。
私のアドバイスは何か。すべてを一度に学習しようとしないでください。1つのジェネレータで始まり、マスターすること、そしてツールキットを拡大します。あなたが完全に新しい場合、クラウドプラットフォームでNovelAIまたはAnimagineXLで開始します。あなたはすでにローカルセットアップを持つ場合、LoRA訓練にジャンプする前にIPAdapterを実験してください。スキルを段階的に構築します。
最も印象的な一貫したアニメキャラクターを生成する創造者は、必ずしもファンシーなハードウェアまたは最も高いツールを持つものではありません。彼らはそれだけで彼らの特定のワークフローを深く理解するのに十分な時間を置いた人々です、正確にどのダイヤルを実装するか知ります。その理解だけの練習から来ます。
私は心から興奮していると思います, コミュニティは2026年に構築しているために。FLUXアニメモデルが改善し続けると、IPAdapterはより良いアニメサポートを得ています, そしてLoRA訓練ツールがより利用可能になっています, 私たちはAI支援アニメキャラクター作成のためのゴールデン年代に入ります。あなたが確認制限があなたはこのスペースに入ることについて、今が時です。
AIインフルエンサーを作成する準備はできましたか?
115人の学生とともに、51レッスンの完全なコースでComfyUIとAIインフルエンサーマーケティングをマスター。
関連記事

AIガールフレンドの写真生成: 本物に見える一貫したキャラクターの作り方
FLUX 2、LoRAトレーニング、IPAdapter、プロンプトエンジニアリングを使って、顔が一貫したフォトリアルなAIガールフレンド写真を生成する方法を学びましょう。完全版2026年ガイドです。

制限のないAI画像生成機:2026年に実際に知る必要があること
制限なしのAI画像生成機に関する正直なガイド。利用可能な内容、法律、クリエイティブワーク向けの責任ある使用。

2026年版 Civitai で検証した最高の NSFW Flux LoRA
同一チェックポイントと同一プロンプトで10種類の Flux NSFW LoRA を検証。アンロックアダプター、解剖学 LoRA、スタイル LoRA を出力品質と副作用でランク付けします。