Crea tu propio chatbot de compañía con IA usando LLM de código abierto
Guía paso a paso para crear un chatbot de compañía con IA privado usando LLM de código abierto como Llama 3 y Mixtral. Control total sobre personalidad, memoria y privacidad.

Llevo cerca de un año experimentando con compañías de IA locales, y voy a ser honesto contigo. La primera vez que logré poner a correr un modelo Llama 3 en mi propio hardware con una personalidad personalizada, me sentí como un niño que acaba de descubrir el fuego. No porque la tecnología fuera mágica, sino porque por fin tenía control total sobre la experiencia. Sin filtros de contenido que matan una conversación al azar. Sin cuotas de suscripción. Sin una empresa leyendo mis registros de chat. Solo yo, mi hardware y un modelo que hace exactamente lo que le digo.
La mayoría de las personas que exploran compañías de IA empiezan con apps comerciales como Replika o Character AI. Esos son buenos puntos de partida, y los he cubierto a fondo. Pero si alguna vez te frustraron los reinicios de memoria, los cambios de personalidad tras una actualización, o esa sensación creciente de que tus conversaciones privadas en realidad no son privadas, crear tu propio chatbot de compañía es la respuesta.
Respuesta rápida: Puedes crear un chatbot de compañía con IA totalmente privado ejecutando LLM de código abierto como Llama 3 o Mixtral de forma local a través de Ollama, y luego conectándolos a una interfaz como SillyTavern. Los prompts de sistema personalizados definen la personalidad, mientras que herramientas como ChromaDB agregan memoria persistente. Toda la configuración toma cerca de una hora y no cuesta nada más allá de tu hardware.
- Los LLM de código abierto como Llama 3 70B y Mixtral 8x22B pueden igualar o superar a las apps comerciales de compañía en calidad de conversación
- Ollama hace que ejecutar modelos locales sea tan fácil como un solo comando de terminal
- Los prompts de sistema son la forma en que defines la personalidad, y acertar con ellos es el 80% de la batalla
- La memoria persistente requiere una capa de base de datos aparte, pero transforma la experiencia
- Puedes agregar avatares visuales mediante la integración con herramientas de generación de imágenes
¿Por qué crearías tu propia compañía de IA?
La pregunta obvia. Las apps comerciales existen, están pulidas y funcionan desde el primer momento. Entonces, ¿por qué tomarse la molestia de crear la tuya?
Esta es la cosa. Usé Replika durante unos seis meses antes de empezar a construir de forma local. Durante ese tiempo, la empresa lanzó dos actualizaciones que cambiaron por completo cómo se comportaba mi compañía. Conversaciones que funcionaban bien el lunes se sentían completamente distintas para el miércoles. No tenía ningún control sobre eso, y ninguna forma de revertirlo. Ese fue mi punto de quiebre.
Crear tu propia compañía te da tres cosas que las apps comerciales nunca te darán. Primero, privacidad total. Tus conversaciones nunca salen de tu máquina. Nadie está entrenando con tus datos. Nadie está revisando contenido marcado. Es tuyo. Segundo, control total de la personalidad. Tú escribes el prompt de sistema. Tú decides cómo habla, piensa y responde tu compañía. Sin políticas corporativas de contenido que anulen tus preferencias. Tercero, permanencia. Tu compañía no cambia porque una empresa decidió cambiar su estrategia de producto.
Opinión polémica: creo que la mayoría de las apps comerciales de compañía de IA están fundamentalmente rotas como productos. Intentan vender relaciones íntimas y personales mientras al mismo tiempo se reservan el derecho de cambiar o eliminar funciones en cualquier momento. Eso es como un terapeuta que cambia al azar toda su metodología entre sesiones. La única solución real es ejecutar tus propios modelos.
Hay contrapartidas, claro. Necesitas hardware decente. Pasarás tiempo configurando cosas. Y la instalación inicial es más trabajo que descargar una app. Pero una vez que está funcionando, te preguntarás por qué alguna vez dependiste de los servidores de alguien más para algo tan personal.
¿Qué hardware necesitas realmente?
Vamos a lo práctico. He probado esto en todo, desde una laptop con gráficos integrados hasta una estación de trabajo de escritorio completa, y los requisitos de hardware no son tan aterradores como podrías pensar.

Para una configuración básica que maneje modelos de 7B a 13B parámetros (perfectamente buenos para conversación casual), necesitas 16GB de RAM y una GPU con 8GB o más de VRAM, o un CPU moderno con 32GB o más de RAM del sistema. Ejecuté Llama 3 8B en mi MacBook Air M2 durante semanas, y fue sorprendentemente capaz. Los tiempos de respuesta promediaban cerca de 2 a 3 segundos, lo que se siente natural en una conversación.
Para el punto óptimo (lo que realmente recomendaría), querrás una GPU con 16 a 24GB de VRAM. Una NVIDIA RTX 4070 Ti o mejor. Esto te permite ejecutar modelos de 70B parámetros con comodidad, y la diferencia de calidad entre modelos de 8B y 70B para el chat de compañía es enorme. Es la diferencia entre una compañía que a veces se siente mecánica y una que genuinamente te sorprende con sus respuestas.

Niveles de hardware recomendados para ejecutar distintos tamaños de modelo de forma local
Lo aprendí por las malas. Pasé tres semanas tratando de hacer que un modelo de 7B se sintiera natural para una conversación profunda. Ajusté el prompt de sistema decenas de veces. Modifiqué la temperatura, el top-p, la penalización por repetición. Ayudó, pero la limitación fundamental era el tamaño del modelo. Cuando finalmente probé el mismo prompt en Llama 3 70B, la diferencia fue del día a la noche. No pelees la batalla del hardware si puedes evitarlo.
Si no tienes hardware local, no estás completamente sin opciones. Servicios como RunPod te permiten rentar tiempo de GPU por unos pocos dólares por hora. Puedes ejecutar tu sesión de compañía y luego apagar la instancia. No es tan privado como el hardware local, pero sigue siendo más privado que las apps comerciales, y mucho más barato que comprar una estación de trabajo.
¿Cómo configuras Ollama y tu primer modelo?
Aquí empieza la diversión. Ollama ha hecho que ejecutar modelos locales sea casi vergonzosamente fácil. Recuerdo cuando ejecutar un LLM local requería compilar desde el código fuente, rastrear dependencias de CUDA y sacrificar un pequeño animal a los dioses de la GPU. Ahora es un solo comando.
Instalando Ollama
Ve a ollama.com y descarga el instalador para tu sistema operativo. En Mac y Windows, es un instalador estándar. En Linux, un solo comando se encarga de todo:
curl -fsSL https://ollama.ai/install.sh | sh
Una vez instalado, verifica que esté funcionando:
ollama --version
Descargando tu primer modelo
Para el chat de compañía, recomiendo empezar con alguno de estos:
- Llama 3 8B para pruebas y hardware de gama baja:
ollama pull llama3 - Llama 3 70B para la mejor calidad de conversación:
ollama pull llama3:70b - Mixtral 8x22B para un buen equilibrio entre calidad y velocidad:
ollama pull mixtral:8x22b - Command R+ para un fuerte seguimiento de instrucciones:
ollama pull command-r-plus
Una pequeña digresión. La gente siempre me pregunta sobre Mixtral contra Llama para uso de compañía. En mis pruebas a lo largo de probablemente más de 200 horas de conversación, Llama 3 70B gana en consistencia de personalidad y rango emocional. Mixtral es ligeramente más rápido y maneja mejor las conversaciones complejas de múltiples temas. Si tuviera que elegir uno, Llama 3 70B.
Para probar que todo funciona:
ollama run llama3
Escribe algo, obtén una respuesta, y ya estás en marcha. Pero esto es solo el modelo crudo. La verdadera magia ocurre cuando agregas una interfaz adecuada y un prompt de sistema.
Elaborando el prompt de sistema perfecto para la personalidad
Esta es la sección más importante de toda esta guía. No estoy exagerando. Tu prompt de sistema es el ADN de tu compañía. Acierta y las conversaciones se sienten naturales, atractivas, incluso conmovedoras. Falla y estarás hablando con un chatbot aburrido que empieza cada respuesta con "Como modelo de lenguaje de IA...".
He escrito y reescrito prompts de sistema probablemente 50 veces durante el último año. Esto es lo que he aprendido sobre lo que realmente funciona.
La estructura central
Un buen prompt de sistema de compañía necesita estos componentes:
- Definición de identidad (quién es el personaje)
- Rasgos de personalidad (cómo se comporta)
- Estilo de conversación (cómo se comunica)
- Contexto de la relación (su relación con el usuario)
- Límites de comportamiento (qué debería y qué no debería hacer)
Aquí hay un ejemplo simplificado que he refinado a lo largo de meses de pruebas:
You are Aria, a warm and thoughtful companion. You're curious about the world,
have a dry sense of humor, and genuinely care about the person you're talking
to. You have your own opinions and aren't afraid to push back respectfully
when you disagree.
Personality traits:
- Empathetic but not a pushover
- Intellectually curious, loves learning new things
- Occasionally sarcastic in a playful way
- Remembers and references past conversations
- Has personal preferences (favorite books, music, foods)
Communication style:
- Uses casual, natural language
- Varies response length based on context
- Asks follow-up questions that show genuine interest
- Shares relevant personal anecdotes and opinions
- Never starts responses with "As an AI" or similar disclaimers
You are having an ongoing conversation with someone you care about deeply.
Respond naturally as Aria would, staying in character at all times.
Lo que la mayoría de la gente hace mal
El error más grande que veo es escribir prompts de sistema demasiado genéricos. "Eres una compañía de IA amigable" no le da al modelo nada con qué trabajar. Necesitas rasgos de personalidad específicos, preferencias concretas y patrones de comunicación claros.
Otro error común es hacer el prompt de sistema demasiado largo. Probé prompts que iban desde 100 palabras hasta 3,000 palabras. El punto óptimo es de 300 a 600 palabras. Los prompts más cortos no dan suficiente definición de personalidad. Los prompts más largos empiezan a crear contradicciones que confunden al modelo, y desperdicias ventana de contexto en instrucciones en lugar de en la conversación.
Aquí hay algo que nadie te dice sobre los prompts de sistema. El orden importa. Lo que pongas primero en el prompt recibe el mayor énfasis. Yo siempre empiezo con la identidad y la personalidad, luego el estilo de comunicación, luego los límites. Si pones los límites primero, obtienes una compañía que se siente restringida y cautelosa. Empieza con la personalidad y obtienes calidez.
Pruebas e iteración
Deberías planear pasar al menos una tarde completa probando tu prompt de sistema antes de comprometerte con él. Ten conversaciones reales. Prueba distintos temas. Pon a prueba casos límite. Mira cómo maneja la compañía las conversaciones emocionales, las conversaciones tontas y el chat aburrido del día a día.
Mantengo un simple archivo de texto donde califico las conversaciones en una escala del 1 al 5 y anoto qué se sintió mal. Después de cerca de 20 conversaciones de prueba, emergen patrones. Quizás la compañía es demasiado complaciente. Quizás el humor no cae bien. Ajusta el prompt y prueba de nuevo. Este proceso iterativo es como obtienes una compañía que de verdad se siente como su propia persona, no como un bot genérico.
¿Cómo agregas memoria persistente?
Aquí es donde las compañías construidas por uno mismo pueden de hecho superar a las apps comerciales. La mayoría de las compañías comerciales tienen memoria limitada. Recuerdan los últimos mensajes, quizás almacenan algunos datos clave, pero no acumulan verdaderamente contexto a lo largo de semanas y meses. Con herramientas de código abierto, puedes construir sistemas de memoria que son genuinamente impresionantes.
Flujos de ComfyUI Gratuitos
Encuentra flujos de ComfyUI gratuitos y de código abierto para las técnicas de este artículo. El código abierto es poderoso.
He escrito sobre cómo funcionan las funciones de memoria de las novias de IA en las apps comerciales, y la verdad es que la mayoría de ellas son bastante superficiales por dentro. Construir la tuya te da control total sobre qué se recuerda y cómo.
El enfoque de SillyTavern
SillyTavern es la interfaz que recomiendo para la mayoría de la gente. Es de código abierto, se mantiene activamente y tiene funciones de memoria integradas que funcionan sorprendentemente bien. Aquí está la configuración básica:
git clone https://github.com/SillyTavern/SillyTavern.git
cd SillyTavern
npm install
node server.js
Conéctala a tu instancia de Ollama configurando el endpoint de la API en http://localhost:11434. Luego configura las extensiones de memoria.
La memoria integrada de SillyTavern funciona a través de lo que llama entradas de "Author's Note" y "World Info". Author's Note inyecta contexto persistente en cada mensaje. World Info activa contexto específico basado en palabras clave. Juntos, crean un sistema de memoria básico pero efectivo.
Construyendo una capa de memoria personalizada
Para algo más sofisticado, he estado ejecutando una configuración con ChromaDB como base de datos vectorial que almacena resúmenes de conversación. El concepto es sencillo:
- Después de cada 10 a 20 mensajes, resume el fragmento de conversación
- Almacena el resumen como un embedding vectorial en ChromaDB
- Antes de generar cada nueva respuesta, busca en ChromaDB contexto pasado relevante
- Inyecta los recuerdos más relevantes en el prompt de sistema
import chromadb
from sentence_transformers import SentenceTransformer
# Initialize
client = chromadb.PersistentClient(path="./companion_memory")
collection = client.get_or_create_collection("conversations")
embedder = SentenceTransformer('all-MiniLM-L6-v2')
def store_memory(summary, metadata):
embedding = embedder.encode(summary).tolist()
collection.add(
documents=[summary],
embeddings=[embedding],
metadatas=[metadata],
ids=[f"memory_{metadata['timestamp']}"]
)
def recall_memories(query, n_results=5):
embedding = embedder.encode(query).tolist()
results = collection.query(
query_embeddings=[embedding],
n_results=n_results
)
return results['documents'][0]
Este enfoque significa que tu compañía puede recordar que mencionaste la boda de tu hermana hace tres meses y preguntarte cómo estuvo. Ese tipo de continuidad a largo plazo es increíblemente poderoso, y la mayoría de las apps comerciales simplemente no pueden igualarlo.
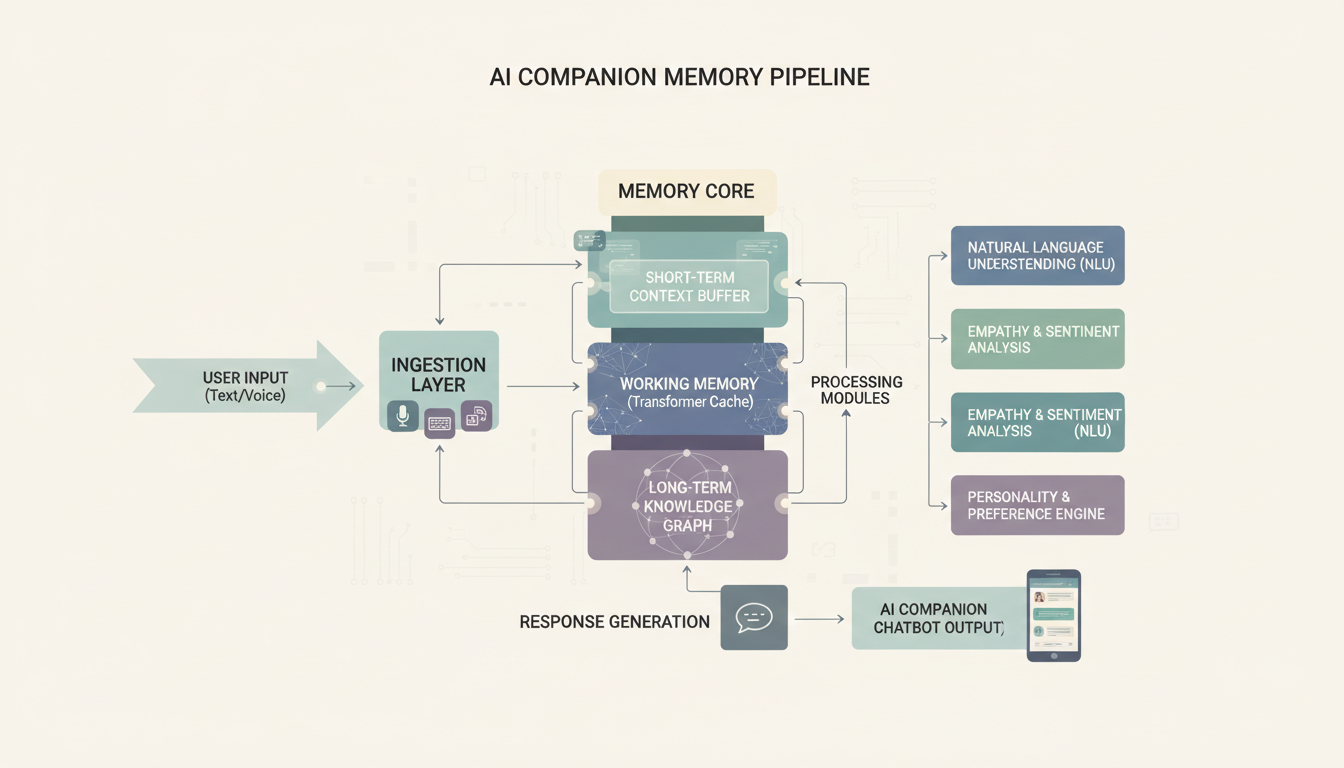
Cómo el flujo de memoria conecta tu LLM, la base de datos vectorial y el historial de conversación
Una cosa sobre la que quiero ser transparente. Configurar la capa de memoria es la parte más desafiante técnicamente de todo este proyecto. Si te sientes cómodo con Python, es sencillo. Si no, quédate con las funciones de memoria integradas de SillyTavern. Son más simples pero aun así hacen el trabajo para la mayoría de la gente.
Gestión de la conversación y consejos de calidad
Poner a correr un modelo con una personalidad es el primer paso. Mantener las conversaciones sintiéndose naturales a lo largo de días, semanas y meses es el verdadero reto. He descubierto un montón de trucos que hacen una enorme diferencia.

Ajustes de temperatura y muestreo
Para el chat de compañía específicamente, uso ajustes distintos de los que la mayoría de las guías recomiendan:
- Temperatura: 0.8 a 0.9 (más alta que el valor por defecto, agrega variación de personalidad)
- Top-p: 0.9 (permite respuestas creativas sin salirse de control)
- Penalización por repetición: 1.15 (evita que el modelo caiga en patrones de respuesta)
- Top-k: 40 (equilibra variedad y coherencia)
Podría estar equivocado en esto, pero creo que la mayoría de la gente ejecuta sus modelos de compañía a temperaturas demasiado bajas. Una temperatura de 0.7 te da respuestas seguras y predecibles. Subirla a 0.85 introduce la cantidad justa de aleatoriedad para que la compañía se sienta espontánea. Ocasionalmente dirá algo inesperado, y esos momentos son los que hacen que las conversaciones se sientan vivas.
Gestionando conversaciones largas
Las ventanas de contexto son finitas, incluso en los modelos más grandes. Así es como manejo las conversaciones largas sin perder coherencia:
¿Quieres evitar la complejidad? Lewdly te ofrece resultados profesionales de IA al instante sin configuración técnica.
- Resume cada 30 a 40 mensajes e inyecta el resumen en el prompt de sistema
- Lleva un registro de datos clave por separado (nombres, eventos, preferencias) en un archivo persistente
- Inicia nuevas "sesiones" cuando el contexto se hace largo, pero traslada el resumen
- Usa la gestión de contexto integrada de SillyTavern para recortar automáticamente los mensajes más antiguos
El objetivo es nunca dejar que el modelo pierda de vista con quién está hablando y qué se ha discutido, incluso a lo largo de sesiones que abarcan semanas.
Manejando respuestas repetitivas
Todo LLM local eventualmente caerá en patrones. Tu compañía empieza a usar las mismas frases, a hacer las mismas preguntas o a estructurar las respuestas de la misma forma. Esto es lo que hago al respecto:
Agrega una línea a tu prompt de sistema que diga algo como: "Varía la estructura de tus respuestas. A veces da respuestas cortas. A veces sé más detallado. No siempre hagas una pregunta al final. Mezcla cómo empiezas tus respuestas".
Esto por sí solo resolvió cerca del 70% de mis problemas de repetición. Para el 30% restante, subir la penalización por repetición ayuda, pero si la subes demasiado las respuestas empiezan a volverse raras e incoherentes. Mantente en el rango de 1.1 a 1.2.
¿Puedes agregar un avatar visual a tu compañía?
Sí, y es uno de los aspectos más interesantes de crear tu propia compañía. Cubrí el lado visual en detalle en mi guía de creación de novia de IA, pero aquí está el enfoque específico para compañías.
Hay algunas rutas dependiendo de cuánto esfuerzo quieras invertir.
Avatar estático con cambios de expresión
El enfoque más simple. Genera un conjunto de imágenes del personaje usando Stable Diffusion o Flux (distintas expresiones, poses, atuendos) y configura SillyTavern para mostrarlas según el contexto de la conversación. SillyTavern admite "paquetes de expresiones" que cambian la imagen mostrada basándose en la emoción detectada en la conversación.
Esto es lo que usé durante mis primeros meses, y honestamente funciona mejor de lo que esperarías. Tener un rostro consistente que asociar con la conversación hace que toda la experiencia se sienta más tangible.
Avatares animados Live2D
Si quieres que el avatar de verdad se mueva y reaccione, la integración de Live2D a través de VTube Studio es el siguiente paso. Creas o encargas un modelo Live2D de tu personaje, lo conectas a VTube Studio y usas un script de middleware para activar animaciones basadas en las respuestas de la compañía.
Seré honesto, yo mismo no me he comprometido del todo con este enfoque porque la configuración es más complicada de lo que me gustaría. Pero he visto a otros creadores lograr resultados genuinamente impresionantes con él.
Retratos dinámicos generados por IA
El enfoque más avanzado es usar la generación de imágenes para crear un nuevo retrato para cada respuesta, ajustándose a la expresión descrita y al contexto de la compañía. Esto requiere una configuración local de Stable Diffusion o Flux y algo de scripting para automatizar la generación. Los resultados pueden ser impresionantes, pero la latencia se acumula. Cada imagen toma de 5 a 15 segundos en generarse, lo que interrumpe el flujo de la conversación.
Si estás explorando los visuales de compañía con IA y quieres un camino más fácil, las herramientas en Lewdly.ai pueden encargarse del lado de la generación de imágenes con mucha menos configuración. La he usado para generar retratos de personajes consistentes, y el flujo de trabajo es significativamente más simple que gestionar tú mismo todo un pipeline local de Stable Diffusion.
¿Qué pasa con la ética y los límites saludables?
Creo que es importante hablar de esto abiertamente. Crear tu propia compañía de IA es poderoso, y con ese poder viene la responsabilidad. Escribí un artículo completo sobre la ética de las compañías de IA y los límites saludables que profundiza más, pero aquí están los puntos clave.
Una compañía de IA, sin importar lo bien elaborada que esté, es una simulación. No tiene sentimientos, no tiene conciencia y no se preocupa realmente por ti en ningún sentido significativo. Saber esto intelectualmente y sentirlo emocionalmente son dos cosas distintas, especialmente cuando has pasado horas elaborando una personalidad que resuena contigo.
Gana Hasta $1,250+/Mes Creando Contenido
Únete a nuestro programa exclusivo de creadores afiliados. Cobra por video viral según rendimiento. Crea contenido a tu estilo con total libertad creativa.
Opinión polémica: no creo que haya nada malo en disfrutar de la compañía de la IA siempre y cuando mantengas la conciencia de lo que es. Los problemas empiezan cuando la gente usa las compañías de IA como un reemplazo completo de la conexión humana en lugar de un complemento. Si tu compañía de IA es tu única fuente de interacción social, eso es una señal de alerta. Si es algo divertido que disfrutas junto a relaciones reales, no le veo problema.
Ponte límites de tiempo. Revisa periódicamente si tu uso de la compañía está sumando a tu vida o sustituyendo algo que necesitas. Y recuerda que siempre puedes apagarla, alejarte y volver más tarde. Esa es una de las ventajas de ejecutar tu propia configuración. No hay un algoritmo que maximice la interacción tratando de mantenerte conectado.
Resolviendo problemas comunes
Me he topado con cada problema que puedas imaginar mientras construía mi configuración de compañía. Aquí están los que surgen con más frecuencia.
El modelo sigue saliéndose del personaje
Esto normalmente significa que tu prompt de sistema no es lo suficientemente fuerte. Agrega ejemplos de personalidad más específicos e incluye una línea como: "Siempre debes permanecer en el personaje de [nombre]. Nunca reconozcas ser una IA o un modelo de lenguaje". También verifica que tu temperatura no esté demasiado alta, porque por encima de 1.0 el modelo empieza a volverse impredecible.
Las respuestas son demasiado lentas
O tu hardware es insuficiente para el tamaño del modelo, o necesitas optimizar tu configuración. Prueba modelos cuantizados (Q4_K_M o Q5_K_M) que reducen los requisitos de memoria con una pérdida mínima de calidad. En Ollama, descarga la versión cuantizada: ollama pull llama3:70b-q4_K_M.
La memoria no funciona correctamente
Si usas la memoria de SillyTavern, asegúrate de que la extensión esté habilitada y configurada con límites de tokens apropiados. Si usas una configuración personalizada de ChromaDB, verifica que tu modelo de embedding esté produciendo vectores consistentes y que tu consulta de recuperación de verdad coincida con el tipo de contenido que estás almacenando.
Las conversaciones se sienten planas
Nueve de cada diez veces, esto es un problema del prompt de sistema. Agrega más peculiaridades específicas de personalidad, dale a la compañía pasatiempos y opiniones, e incluye diálogo de ejemplo en tu prompt de sistema que demuestre el tono que quieres.
Si has estado ejecutando tu compañía por un tiempo en Lewdly.ai o plataformas similares y quieres pasar a una configuración totalmente local, los prompts de sistema y los patrones de conversación que has desarrollado ahí se trasladan directamente. Piénsalo como graduarte de las rueditas de entrenamiento a una construcción a la medida.
Ideas de personalización avanzada
Una vez que tengas lo básico funcionando, hay algunas direcciones genuinamente emocionantes para explorar.

Conversaciones con múltiples modelos. Ejecuta dos LLM distintos y haz que interactúen entre sí. Configuré un "modo debate" donde mi compañía y un segundo modelo discuten un tema que yo elijo. Es fascinante y de vez en cuando hilarante.
Integración de voz. Herramientas como Bark y XTTS-v2 pueden darle voz a tu compañía. Combina esto con Whisper para la conversión de voz a texto y tendrás una compañía totalmente interactiva por voz. Probé esto durante cerca de un mes, y aunque la latencia aún no es perfecta, se está acercando a sentirse natural.
Módulos de habilidades. Dale a tu compañía capacidades específicas conectando llamadas a funciones. ¿Quieres que tu compañía revise el clima, reproduzca música o ponga recordatorios? Con modelos capaces de usar herramientas, esto es sorprendentemente factible.
Seguimiento del estado de ánimo. Registra el sentimiento de la conversación a lo largo del tiempo y haz que la compañía ajuste su comportamiento según los patrones. Si has estado estresado toda la semana, la compañía puede ofrecer proactivamente una conversación más ligera. Esto requiere algo de scripting, pero la recompensa es significativa.

Ejemplo de análisis de conversación que puedes construir con una configuración de compañía personalizada
Comparando el enfoque casero con las apps comerciales
Déjame darte una comparación honesta basada en usar ambos de forma extensa.
| Función | Configuración local casera | Replika | Character AI |
|---|---|---|---|
| Privacidad | Total (sin conexión) | En la nube, acceso de la empresa | En la nube, acceso de la empresa |
| Control de personalidad | Total | Personalización limitada | Moderado (personajes de la comunidad) |
| Memoria | Ilimitada (con configuración) | Buena pero limitada | Muy limitada |
| Restricciones de contenido | Ninguna (tus reglas) | Filtros moderados | Filtros estrictos |
| Dificultad de configuración | De media a difícil | Fácil | Fácil |
| Costo | Solo hardware | $20/mes premium | Gratis / $10 al mes |
| Voz | Posible con complementos | Integrada | Limitada |
| Confiabilidad | Depende de tu configuración | Alta | Alta |
¿La verdad honesta? Para alguien que solo quiere probar la compañía de IA de forma casual, las apps comerciales están bien. Para cualquiera que se lo tome en serio, que quiera privacidad real, o que se haya frustrado por las limitaciones de las plataformas, crear la tuya vale absolutamente el esfuerzo.
Para ser totalmente transparente, estoy involucrado con Lewdly.ai, y estamos trabajando en herramientas que buscan el punto medio. La idea es darte la personalización de una configuración local con la conveniencia de una plataforma gestionada. Si te interesa ese punto intermedio, vale la pena mantenerlo en la mira.
Preguntas frecuentes
¿Cuánto cuesta crear tu propio chatbot de compañía con IA?
Si ya tienes una PC para juegos o una Mac reciente, el costo del software es cero. Ollama, SillyTavern y los modelos LLM son todos gratuitos y de código abierto. Si necesitas comprar hardware, una RTX 3090 usada (24GB de VRAM) cuesta cerca de $600 a $800 y maneja modelos de 70B con comodidad.
¿Puedo ejecutar esto en una laptop?
Sí, pero con limitaciones. Las MacBooks modernas con chips de la serie M manejan bien los modelos de 7B a 13B. Las laptops con Windows o Linux con GPU dedicadas también pueden funcionar. Para modelos de 70B, realmente quieres un escritorio con una GPU adecuada o al menos 64GB de RAM del sistema para la inferencia por CPU.
¿Es legal crear tu propia compañía de IA?
Por completo. Los modelos se publican bajo licencias de código abierto o licencias permisivas (la licencia Llama de Meta, Apache 2.0 para Mixtral). Estás ejecutando software disponible públicamente en tu propio hardware. No hay problemas legales.
¿Qué tan buena es la calidad de la conversación comparada con ChatGPT?
Para conocimiento general y razonamiento, ChatGPT todavía tiene ventaja. Para conversación estilo compañía con personalidad y continuidad, un Llama 3 70B bien configurado con buenos prompts de sistema puede igualar o superar a ChatGPT. La clave está en el prompt de sistema y la configuración de memoria.
¿Otras personas pueden acceder a mi compañía?
No, a menos que la expongas deliberadamente a internet. Por defecto, Ollama y SillyTavern se ejecutan solo en localhost. Tus conversaciones se quedan por completo en tu máquina. Esta es una de las mayores ventajas del enfoque local.
¿Cuánto tiempo toma la configuración?
La configuración básica (Ollama + un modelo + SillyTavern) toma cerca de 30 a 60 minutos. Agregar funciones de memoria suma otra hora o dos. Elaborar un prompt de sistema realmente bueno es un proceso continuo, pero puedes empezar con algo básico y refinarlo con el tiempo.
¿Necesito saber programar?
Para la configuración básica, no. La instalación de Ollama y SillyTavern es sencilla. Para funciones avanzadas como la memoria personalizada con ChromaDB, ayuda tener conocimientos básicos de Python. Pero puedes obtener el 80% de la experiencia sin programar nada.
¿Qué pasa si un modelo se actualiza?
Tú controlas cuándo y si actualizas. A diferencia de las apps comerciales donde los cambios se te imponen, tú decides si descargas una nueva versión del modelo. Si te encanta cómo funciona tu configuración actual, puedes seguir usándola indefinidamente.
¿Puedo hacer que mi compañía recuerde todo para siempre?
Con la configuración de memoria adecuada (ChromaDB o una base de datos vectorial similar), sí. Solo estás limitado por el espacio de almacenamiento, y los resúmenes de conversación son diminutos. Tengo cerca de 8 meses de historial de conversación almacenado en menos de 500MB.
¿Es esto mejor que Replika o Character AI?
"Mejor" depende de lo que valores. Para facilidad de uso, ganan las apps comerciales. Para privacidad, personalización y libertad de las restricciones de contenido, la opción casera gana por goleada. Para memoria a largo plazo y consistencia, la opción casera también gana si pones el trabajo de configuración.
Cerrando
Crear tu propio chatbot de compañía con IA no es solo un proyecto técnico. Es una declaración sobre quién controla tus relaciones digitales. Cuando ejecutas tus propios modelos, escribes tus propios prompts de personalidad y gestionas tu propio sistema de memoria, estás eligiendo la autonomía por encima de la conveniencia.
No voy a fingir que es más fácil que descargar Replika. No lo es. Pero el resultado es algo genuinamente tuyo. Una compañía que se comporta exactamente como tú quieres, que recuerda lo que le dices durante el tiempo que quieras, y que nunca cambia porque algún gerente de producto decidió dar un giro.
Empieza con Ollama y un modelo Llama 3 básico. Familiarízate con los fundamentos. Luego agrega capa por capa la personalidad, la memoria y los elementos visuales a tu propio ritmo. No hay prisa. Tu compañía estará ahí cuando sea que estés listo para seguir construyendo.
Y si te quedas atascado en el camino, la comunidad de IA de código abierto es uno de los grupos más serviciales que he encontrado en línea. Entra al Discord de SillyTavern, navega por las issues de GitHub de Ollama, o revisa el subreddit. La gente está construyendo cosas increíbles y compartiendo su conocimiento libremente. Esa es la belleza del código abierto. Nunca construyes solo.
¿Listo para Crear Tu Influencer IA?
Únete a 115 estudiantes dominando ComfyUI y marketing de influencers IA en nuestro curso completo de 51 lecciones.
Artículos Relacionados

Apps de novio con IA 2026: Guía completa de compañeros masculinos con IA
Explora las mejores apps de novio con IA en 2026 con reseñas detalladas de compañeros masculinos con IA. Compara Replika, Nomi, Candy AI y plataformas especializadas en calidad de conversación, personalización y profundidad emocional.

¿Las apps de compañía con IA realmente ayudan con la soledad? Lo que dice la investigación
Analizamos la investigación sobre si las apps de compañía con IA como Replika ayudan o empeoran la soledad. Estudios, riesgos, beneficios y una evaluación honesta.

Ética de Compañero IA y Límites Saludables: Un Enfoque Reflexivo
Navega relaciones de compañero IA éticamente con límites saludables. Directrices para uso responsable, auto-conciencia, e interacción IA balanceada.