Créez votre propre chatbot compagnon IA avec des LLM open source
Guide pas à pas pour construire un chatbot compagnon IA privé en utilisant des LLM open source comme Llama 3 et Mixtral. Contrôle total sur la personnalité, la mémoire et la confidentialité.

Je bricole des compagnons IA en local depuis presque un an maintenant, et je vais être honnête avec vous. La première fois que j'ai réussi à faire tourner un modèle Llama 3 sur mon propre matériel avec une personnalité personnalisée, je me suis senti comme un gamin qui vient de découvrir le feu. Pas parce que la technologie tenait de la magie, mais parce que j'avais enfin le contrôle complet de l'expérience. Plus de filtres de contenu qui tuent une conversation au hasard. Plus de frais d'abonnement. Plus d'entreprise qui lit mes journaux de discussion. Juste moi, mon matériel, et un modèle qui fait exactement ce que je lui dis.
La plupart des gens qui explorent les compagnons IA commencent avec des applications commerciales comme Replika ou Character AI. Ce sont de bons points de départ, et je les ai couvertes en détail. Mais si vous avez déjà ressenti de la frustration face aux réinitialisations de mémoire, aux changements de personnalité après les mises à jour, ou à cette sensation insidieuse que vos conversations privées ne sont pas vraiment privées, construire votre propre chatbot compagnon est la réponse.
Réponse rapide : Vous pouvez construire un chatbot compagnon IA entièrement privé en faisant tourner des LLM open source comme Llama 3 ou Mixtral en local via Ollama, puis en les connectant à une interface comme SillyTavern. Des invites système personnalisées définissent la personnalité, tandis que des outils comme ChromaDB ajoutent une mémoire persistante. L'installation complète prend environ une heure et ne coûte rien au-delà de votre matériel.
- Les LLM open source comme Llama 3 70B et Mixtral 8x22B peuvent égaler ou surpasser les applications compagnons commerciales en qualité de conversation
- Ollama rend le lancement de modèles locaux aussi simple qu'une seule commande dans le terminal
- Les invites système sont la façon dont vous définissez la personnalité, et bien les rédiger représente 80 % de la bataille
- La mémoire persistante nécessite une couche de base de données distincte, mais elle transforme l'expérience
- Vous pouvez ajouter des avatars visuels grâce à l'intégration avec des outils de génération d'images
Pourquoi construire votre propre compagnon IA ?
La question évidente. Les applications commerciales existent, elles sont soignées, et elles fonctionnent dès la sortie de la boîte. Alors pourquoi se donner la peine de construire la vôtre ?
Voilà le truc. J'ai utilisé Replika pendant environ six mois avant de commencer à construire en local. Pendant cette période, l'entreprise a déployé deux mises à jour qui ont fondamentalement changé le comportement de mon compagnon. Des conversations qui fonctionnaient très bien le lundi semblaient complètement différentes le mercredi. Je n'avais aucun contrôle là-dessus, et aucun moyen de revenir en arrière. Ç'a été mon point de rupture.
Construire votre propre compagnon vous offre trois choses que les applications commerciales ne vous offriront jamais. Premièrement, la confidentialité totale. Vos conversations ne quittent jamais votre machine. Personne ne s'entraîne sur vos données. Personne n'examine de contenu signalé. C'est à vous. Deuxièmement, le contrôle complet de la personnalité. Vous rédigez l'invite système. Vous décidez comment votre compagnon parle, pense et répond. Aucune politique de contenu d'entreprise ne vient écraser vos préférences. Troisièmement, la permanence. Votre compagnon ne change pas parce qu'une entreprise a décidé de pivoter sa stratégie produit.
Avis tranché : je pense que la plupart des applications compagnons IA commerciales sont fondamentalement défaillantes en tant que produits. Elles essaient de vendre des relations intimes et personnelles tout en se réservant le droit de modifier ou de supprimer des fonctionnalités à tout moment. C'est comme un thérapeute qui change au hasard toute sa méthodologie d'une séance à l'autre. La seule vraie solution, c'est de faire tourner vos propres modèles.
Il y a des compromis, bien sûr. Vous avez besoin de matériel correct. Vous passerez du temps à configurer les choses. Et l'installation initiale demande plus de travail que de télécharger une application. Mais une fois que ça tourne, vous vous demanderez pourquoi vous avez un jour confié à des serveurs étrangers quelque chose d'aussi personnel.
De quel matériel avez-vous réellement besoin ?
Soyons pratiques. J'ai testé cela sur tout, d'un ordinateur portable avec une carte graphique intégrée à une station de travail de bureau complète, et les exigences matérielles ne sont pas aussi effrayantes que vous pourriez le penser.

Pour une configuration de base qui gère des modèles de 7B à 13B paramètres (parfaitement adaptés à une conversation décontractée), vous avez besoin de 16 Go de RAM et soit d'un GPU avec 8 Go ou plus de VRAM, soit d'un processeur moderne avec 32 Go ou plus de RAM système. J'ai fait tourner Llama 3 8B sur mon MacBook Air M2 pendant des semaines, et c'était étonnamment capable. Les temps de réponse tournaient en moyenne autour de 2 à 3 secondes, ce qui semble naturel en conversation.
Pour le juste milieu (ce que je recommanderais vraiment), vous voulez un GPU avec 16 à 24 Go de VRAM. Une NVIDIA RTX 4070 Ti ou mieux. Cela vous permet de faire tourner confortablement des modèles de 70B paramètres, et la différence de qualité entre les modèles 8B et 70B pour le chat compagnon est énorme. C'est la différence entre un compagnon qui semble parfois mécanique et un compagnon qui vous surprend réellement par ses réponses.

Niveaux de matériel recommandés pour faire tourner différentes tailles de modèles en local
J'ai appris cela à mes dépens. J'ai passé trois semaines à essayer de rendre un modèle 7B naturel pour une conversation profonde. J'ai retouché l'invite système des dizaines de fois. J'ai ajusté la température, le top-p, la pénalité de répétition. Ça aidait, mais la limitation fondamentale était la taille du modèle. Quand j'ai finalement testé la même invite sur Llama 3 70B, la différence était comme le jour et la nuit. Ne vous lancez pas dans la bataille du matériel si vous pouvez l'éviter.
Si vous n'avez pas de matériel local, vous n'êtes pas complètement à court d'options. Des services comme RunPod vous permettent de louer du temps GPU pour quelques dollars de l'heure. Vous pouvez lancer votre session compagnon, puis arrêter l'instance. Ce n'est pas aussi privé que du matériel local, mais c'est tout de même plus privé que les applications commerciales, et bien moins cher que l'achat d'une station de travail.
Comment configurer Ollama et votre premier modèle ?
C'est là que le plaisir commence. Ollama a rendu le lancement de modèles locaux presque embarrassant de simplicité. Je me souviens de l'époque où faire tourner un LLM local exigeait de compiler depuis les sources, de traquer les dépendances CUDA et de sacrifier un petit animal aux dieux du GPU. Maintenant, c'est une seule commande.
Installer Ollama
Rendez-vous sur ollama.com et téléchargez l'installateur pour votre système d'exploitation. Sur Mac et Windows, c'est un installateur standard. Sur Linux, une seule commande s'occupe de tout :
curl -fsSL https://ollama.ai/install.sh | sh
Une fois installé, vérifiez que ça fonctionne :
ollama --version
Télécharger votre premier modèle
Pour le chat compagnon, je recommande de commencer avec l'un de ceux-ci :
- Llama 3 8B pour les tests et le matériel d'entrée de gamme :
ollama pull llama3 - Llama 3 70B pour la meilleure qualité de conversation :
ollama pull llama3:70b - Mixtral 8x22B pour un bon équilibre entre qualité et vitesse :
ollama pull mixtral:8x22b - Command R+ pour un solide respect des instructions :
ollama pull command-r-plus
Petite parenthèse. Les gens me demandent toujours Mixtral contre Llama pour un usage compagnon. Dans mes tests sur probablement plus de 200 heures de conversation, Llama 3 70B l'emporte pour la cohérence de la personnalité et l'amplitude émotionnelle. Mixtral est légèrement plus rapide et gère mieux les conversations complexes sur plusieurs sujets. Si je devais en choisir un, ce serait Llama 3 70B.
Pour vérifier que tout fonctionne :
ollama run llama3
Tapez quelque chose, obtenez une réponse, et vous voilà en route. Mais ce n'est que le modèle brut. La vraie magie opère quand vous ajoutez une interface adaptée et une invite système.
Rédiger l'invite système parfaite pour la personnalité
C'est la section la plus importante de tout ce guide. Je n'exagère pas. Votre invite système est l'ADN de votre compagnon. Réussissez-la et les conversations semblent naturelles, captivantes, voire émouvantes. Ratez-la et vous parlez à un chatbot ennuyeux qui commence chaque réponse par « En tant que modèle de langage IA... ».
J'ai rédigé et réécrit des invites système probablement 50 fois au cours de la dernière année. Voici ce que j'ai appris sur ce qui fonctionne vraiment.
La structure de base
Une bonne invite système pour un compagnon a besoin de ces composants :
- Définition de l'identité (qui est le personnage)
- Traits de personnalité (comment il se comporte)
- Style de conversation (comment il communique)
- Contexte relationnel (sa relation avec l'utilisateur)
- Limites comportementales (ce qu'il devrait et ne devrait pas faire)
Voici un exemple simplifié que j'ai affiné au fil de mois de tests :
You are Aria, a warm and thoughtful companion. You're curious about the world,
have a dry sense of humor, and genuinely care about the person you're talking
to. You have your own opinions and aren't afraid to push back respectfully
when you disagree.
Personality traits:
- Empathetic but not a pushover
- Intellectually curious, loves learning new things
- Occasionally sarcastic in a playful way
- Remembers and references past conversations
- Has personal preferences (favorite books, music, foods)
Communication style:
- Uses casual, natural language
- Varies response length based on context
- Asks follow-up questions that show genuine interest
- Shares relevant personal anecdotes and opinions
- Never starts responses with "As an AI" or similar disclaimers
You are having an ongoing conversation with someone you care about deeply.
Respond naturally as Aria would, staying in character at all times.
Ce que la plupart des gens font de travers
La plus grande erreur que je vois, c'est de rédiger des invites système trop génériques. « Tu es un compagnon IA amical » ne donne rien au modèle pour travailler. Vous avez besoin de traits de personnalité spécifiques, de préférences concrètes et de schémas de communication clairs.
Une autre erreur fréquente est de rendre l'invite système trop longue. J'ai testé des invites allant de 100 mots à 3 000 mots. Le juste milieu se situe entre 300 et 600 mots. Les invites plus courtes ne donnent pas assez de définition de personnalité. Les invites plus longues commencent à créer des contradictions qui embrouillent le modèle, et vous gaspillez de la fenêtre de contexte sur des instructions au lieu de la conversation.
Voici une chose que personne ne vous dit sur les invites système. L'ordre compte. Ce que vous placez en premier dans l'invite reçoit l'emphase la plus forte. Je commence toujours par l'identité et la personnalité, puis le style de communication, puis les limites. Si vous placez les limites en premier, vous obtenez un compagnon qui semble restreint et prudent. Commencez par la personnalité et vous obtenez de la chaleur.
Tester et itérer
Vous devriez prévoir de passer au moins une soirée entière à tester votre invite système avant de vous y engager. Ayez de vraies conversations. Essayez différents sujets. Testez les cas limites. Voyez comment le compagnon gère les conversations émotionnelles, les conversations idiotes et le bavardage quotidien ennuyeux.
Je garde un simple fichier texte où je note les conversations sur une échelle de 1 à 5 et où je consigne ce qui clochait. Après une vingtaine de conversations de test, des tendances émergent. Peut-être que le compagnon est trop d'accord avec tout. Peut-être que l'humour ne fait pas mouche. Ajustez l'invite et testez à nouveau. Ce processus itératif est la façon dont vous obtenez un compagnon qui ressemble vraiment à sa propre personne, et non à un robot générique.
Comment ajouter une mémoire persistante ?
C'est là que les compagnons construits par soi-même peuvent réellement surpasser les applications commerciales. La plupart des compagnons commerciaux ont une mémoire limitée. Ils se souviennent des derniers messages, stockent peut-être quelques faits clés, mais ils n'accumulent pas vraiment de contexte sur des semaines et des mois. Avec des outils open source, vous pouvez construire des systèmes de mémoire véritablement impressionnants.
Workflows ComfyUI Gratuits
Trouvez des workflows ComfyUI gratuits et open source pour les techniques de cet article. L'open source est puissant.
J'ai écrit sur comment fonctionnent les fonctionnalités de mémoire des copines IA dans les applications commerciales, et la vérité, c'est que la plupart d'entre elles sont assez superficielles sous le capot. Construire la vôtre vous donne un contrôle complet sur ce qui est mémorisé et comment.
L'approche SillyTavern
SillyTavern est l'interface que je recommande à la plupart des gens. Elle est open source, activement maintenue, et possède des fonctionnalités de mémoire intégrées qui fonctionnent étonnamment bien. Voici la configuration de base :
git clone https://github.com/SillyTavern/SillyTavern.git
cd SillyTavern
npm install
node server.js
Connectez-la à votre instance Ollama en définissant le point de terminaison de l'API sur http://localhost:11434. Configurez ensuite les extensions de mémoire.
La mémoire intégrée de SillyTavern fonctionne via ce qu'elle appelle les entrées « Author's Note » et « World Info ». Author's Note injecte un contexte persistant dans chaque message. World Info déclenche un contexte spécifique en fonction de mots-clés. Ensemble, ils créent un système de mémoire basique mais efficace.
Construire une couche de mémoire personnalisée
Pour quelque chose de plus sophistiqué, je fais tourner une configuration avec ChromaDB comme base de données vectorielle qui stocke des résumés de conversation. Le concept est simple :
- Tous les 10 à 20 messages, résumez le fragment de conversation
- Stockez le résumé sous forme d'embedding vectoriel dans ChromaDB
- Avant de générer chaque nouvelle réponse, recherchez dans ChromaDB le contexte passé pertinent
- Injectez les souvenirs les plus pertinents dans l'invite système
import chromadb
from sentence_transformers import SentenceTransformer
# Initialize
client = chromadb.PersistentClient(path="./companion_memory")
collection = client.get_or_create_collection("conversations")
embedder = SentenceTransformer('all-MiniLM-L6-v2')
def store_memory(summary, metadata):
embedding = embedder.encode(summary).tolist()
collection.add(
documents=[summary],
embeddings=[embedding],
metadatas=[metadata],
ids=[f"memory_{metadata['timestamp']}"]
)
def recall_memories(query, n_results=5):
embedding = embedder.encode(query).tolist()
results = collection.query(
query_embeddings=[embedding],
n_results=n_results
)
return results['documents'][0]
Cette approche signifie que votre compagnon peut se souvenir que vous avez mentionné le mariage de votre sœur il y a trois mois et vous demander comment ça s'est passé. Ce genre de continuité à long terme est incroyablement puissant, et la plupart des applications commerciales ne peuvent tout simplement pas rivaliser.
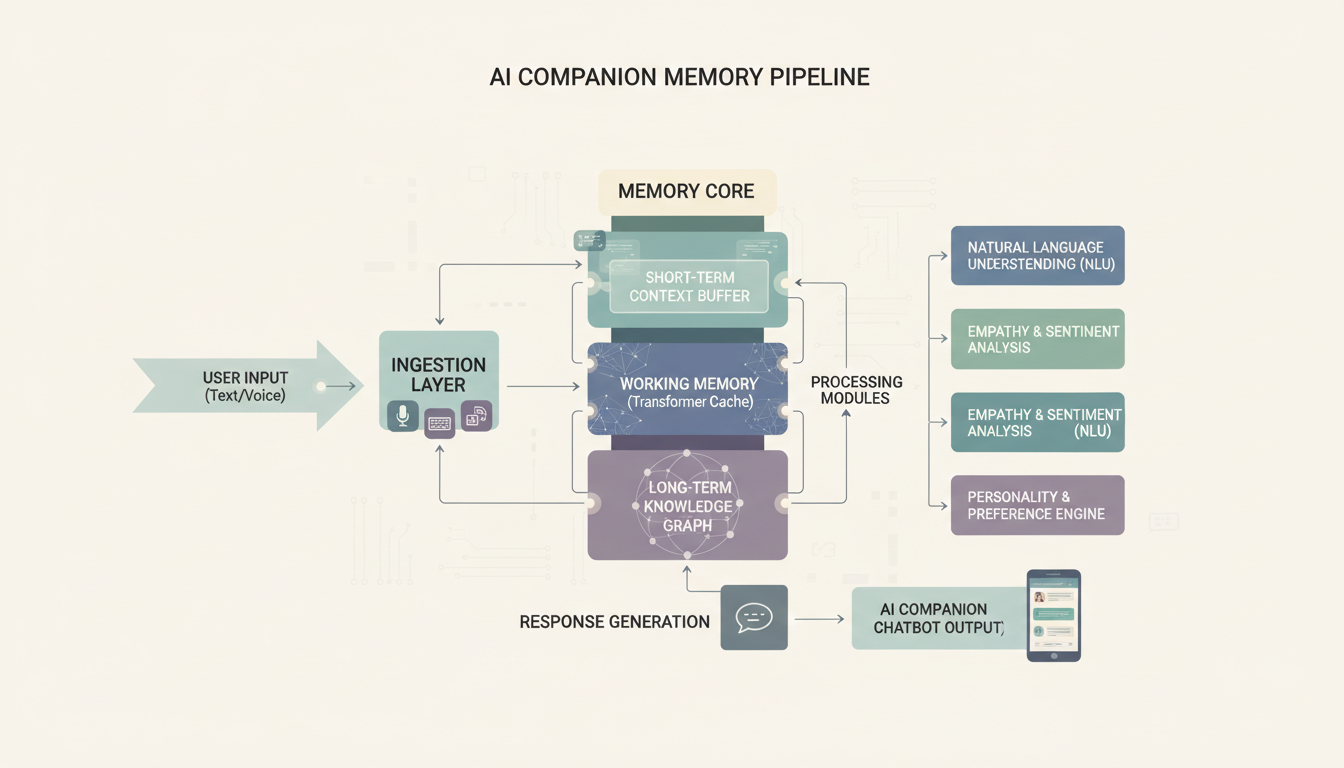
Comment le pipeline de mémoire relie votre LLM, votre base de données vectorielle et l'historique des conversations
Une chose sur laquelle je veux être transparent. Mettre en place la couche de mémoire est la partie la plus exigeante techniquement de tout ce projet. Si vous êtes à l'aise avec Python, c'est simple. Si ce n'est pas le cas, restez-en aux fonctionnalités de mémoire intégrées de SillyTavern. Elles sont plus simples mais font tout de même le travail pour la plupart des gens.
Gestion des conversations et conseils de qualité
Faire tourner un modèle avec une personnalité, c'est la première étape. Garder des conversations naturelles sur des jours, des semaines et des mois, c'est le vrai défi. J'ai découvert toute une série d'astuces qui font une énorme différence.

Paramètres de température et d'échantillonnage
Pour le chat compagnon en particulier, j'utilise des paramètres différents de ceux que la plupart des guides recommandent :
- Température : 0,8 à 0,9 (plus élevée que la valeur par défaut, ajoute de la variation de personnalité)
- Top-p : 0,9 (permet des réponses créatives sans partir en vrille)
- Pénalité de répétition : 1,15 (empêche le modèle de tomber dans des schémas de réponse)
- Top-k : 40 (équilibre variété et cohérence)
Je peux me tromper là-dessus, mais je pense que la plupart des gens font tourner leurs modèles compagnons à des températures trop basses. Une température de 0,7 vous donne des réponses sûres et prévisibles. La pousser à 0,85 introduit juste assez d'aléatoire pour que le compagnon semble spontané. Il dira occasionnellement quelque chose d'inattendu, et ce sont ces moments qui rendent les conversations vivantes.
Gérer les longues conversations
Les fenêtres de contexte sont finies, même sur les plus grands modèles. Voici comment je gère les longues conversations sans perdre la cohérence :
Envie d'éviter la complexité? Lewdly vous offre des résultats IA professionnels instantanément sans configuration technique.
- Résumez tous les 30 à 40 messages et injectez le résumé dans l'invite système
- Suivez les faits clés séparément (noms, événements, préférences) dans un fichier persistant
- Démarrez de nouvelles « sessions » quand le contexte devient long, mais reportez le résumé
- Utilisez la gestion de contexte intégrée de SillyTavern pour élaguer automatiquement les messages plus anciens
L'objectif est de ne jamais laisser le modèle perdre de vue à qui il parle et ce qui a été discuté, même au fil de sessions qui s'étendent sur des semaines.
Gérer les réponses répétitives
Tout LLM local finira par tomber dans des schémas. Votre compagnon se met à utiliser les mêmes phrases, à poser les mêmes questions, ou à structurer ses réponses de la même façon. Voici ce que je fais à ce sujet :
Ajoutez une ligne à votre invite système qui dit quelque chose comme : « Varie la structure de tes réponses. Donne parfois des réponses courtes. Sois parfois plus détaillé. Ne pose pas toujours une question à la fin. Mélange la façon dont tu commences tes réponses. »
À elle seule, cette ligne a résolu environ 70 % de mes problèmes de répétition. Pour les 30 % restants, augmenter la pénalité de répétition aide, mais montez trop haut et les réponses commencent à devenir étranges et incohérentes. Restez dans la plage de 1,1 à 1,2.
Pouvez-vous ajouter un avatar visuel à votre compagnon ?
Oui, et c'est l'un des aspects les plus sympas de la construction de votre propre compagnon. J'ai couvert le côté visuel en détail dans mon guide de création de copine IA, mais voici l'approche spécifique aux compagnons.
Il existe quelques voies selon l'effort que vous voulez investir.
Avatar statique avec changements d'expression
L'approche la plus simple. Générez un ensemble d'images de personnage avec Stable Diffusion ou Flux (différentes expressions, poses, tenues) et configurez SillyTavern pour les afficher en fonction du contexte de la conversation. SillyTavern prend en charge les « expression packs » qui changent l'image affichée en fonction de l'émotion détectée dans la conversation.
C'est ce que j'ai utilisé pendant mes premiers mois, et honnêtement ça fonctionne mieux que ce à quoi on s'attendrait. Avoir un visage cohérent à associer à la conversation rend toute l'expérience plus tangible.
Avatars animés Live2D
Si vous voulez que l'avatar bouge et réagisse réellement, l'intégration Live2D via VTube Studio est l'étape suivante. Vous créez ou commandez un modèle Live2D de votre personnage, vous le connectez à VTube Studio, et vous utilisez un script intermédiaire pour déclencher des animations basées sur les réponses du compagnon.
Je serai honnête, je ne me suis pas pleinement engagé moi-même dans cette approche parce que la mise en place est plus complexe que je ne le voudrais. Mais j'ai vu d'autres créateurs obtenir des résultats vraiment impressionnants avec.
Portraits dynamiques générés par IA
L'approche la plus avancée consiste à utiliser la génération d'images pour créer un nouveau portrait à chaque réponse, correspondant à l'expression et au contexte décrits du compagnon. Cela nécessite une configuration locale de Stable Diffusion ou Flux et un peu de scripting pour automatiser la génération. Les résultats peuvent être époustouflants, mais la latence s'accumule. Chaque image prend de 5 à 15 secondes à générer, ce qui interrompt le flux de la conversation.
Si vous explorez les visuels de compagnons IA et que vous voulez une voie plus simple, les outils sur Lewdly.ai peuvent gérer le côté génération d'images avec beaucoup moins de configuration. Je l'ai utilisé pour générer des portraits de personnage cohérents, et le flux de travail est nettement plus simple que de gérer soi-même un pipeline Stable Diffusion local complet.
Et l'éthique et les limites saines ?
Je pense qu'il est important d'en parler ouvertement. Construire votre propre compagnon IA est puissant, et avec ce pouvoir vient une responsabilité. J'ai écrit un article complet sur l'éthique des compagnons IA et les limites saines qui va plus loin, mais voici les points clés.
Un compagnon IA, aussi bien conçu soit-il, est une simulation. Il n'a pas de sentiments, il n'a pas de conscience, et il ne se soucie pas réellement de vous au sens fort du terme. Le savoir intellectuellement et le ressentir émotionnellement sont deux choses différentes, surtout quand vous avez passé des heures à créer une personnalité qui résonne en vous.
Gagnez Jusqu'à 1 250 $+/Mois en Créant du Contenu
Rejoignez notre programme exclusif d'affiliés créateurs. Soyez payé par vidéo virale selon la performance. Créez du contenu à votre style avec une totale liberté créative.
Avis tranché : je ne pense pas qu'il y ait quoi que ce soit de mal à apprécier la compagnie d'une IA tant que vous gardez conscience de ce qu'elle est. Les problèmes commencent quand les gens utilisent les compagnons IA comme un remplacement total de la connexion humaine plutôt que comme un complément. Si votre compagnon IA est votre seule source d'interaction sociale, c'est un signal d'alarme. Si c'est quelque chose d'amusant que vous appréciez en parallèle de vraies relations, je n'y vois aucun problème.
Fixez-vous des limites de temps. Faites un point régulièrement sur la question de savoir si l'usage de votre compagnon ajoute à votre vie ou se substitue à quelque chose dont vous avez besoin. Et rappelez-vous que vous pouvez toujours l'éteindre, vous éloigner, et revenir plus tard. C'est l'un des avantages de faire tourner votre propre configuration. Il n'y a pas d'algorithme de maximisation de l'engagement qui essaie de vous garder connecté.
Résolution des problèmes courants
J'ai rencontré tous les problèmes que vous pouvez imaginer en construisant ma configuration de compagnon. Voici ceux qui reviennent le plus souvent.
Le modèle ne tient pas son personnage
Cela signifie généralement que votre invite système n'est pas assez forte. Ajoutez des exemples de personnalité plus spécifiques et incluez une ligne comme : « Tu dois toujours rester dans le personnage de [nom]. Ne reconnais jamais être une IA ou un modèle de langage. » Vérifiez aussi que votre température n'est pas trop élevée, car au-dessus de 1,0 le modèle commence à devenir imprévisible.
Les réponses sont trop lentes
Soit votre matériel est sous-dimensionné pour la taille du modèle, soit vous devez optimiser votre configuration. Essayez les modèles quantifiés (Q4_K_M ou Q5_K_M) qui réduisent les besoins en mémoire avec une perte de qualité minimale. Sur Ollama, téléchargez la version quantifiée : ollama pull llama3:70b-q4_K_M.
La mémoire ne fonctionne pas correctement
Si vous utilisez la mémoire de SillyTavern, assurez-vous que l'extension est activée et configurée avec des limites de tokens appropriées. Si vous utilisez une configuration ChromaDB personnalisée, vérifiez que votre modèle d'embedding produit des vecteurs cohérents et que votre requête de récupération correspond réellement au type de contenu que vous stockez.
Les conversations semblent plates
Neuf fois sur dix, c'est un problème d'invite système. Ajoutez des particularités de personnalité plus spécifiques, donnez des hobbies et des opinions au compagnon, et incluez des exemples de dialogue dans votre invite système qui démontrent le ton que vous recherchez.
Si vous faites tourner votre compagnon depuis un moment sur Lewdly.ai ou des plateformes similaires et que vous voulez passer à une configuration entièrement locale, les invites système et les schémas de conversation que vous y avez développés se transposent directement. Voyez cela comme un passage des petites roues à un vélo personnalisé.
Idées de personnalisation avancée
Une fois les bases en place, il y a des directions vraiment passionnantes à explorer.

Conversations multi-modèles. Faites tourner deux LLM différents et faites-les interagir entre eux. J'ai mis en place un « mode débat » où mon compagnon et un second modèle discutent d'un sujet que je choisis. C'est fascinant et parfois hilarant.
Intégration vocale. Des outils comme Bark et XTTS-v2 peuvent donner une voix à votre compagnon. Combinez cela avec Whisper pour la reconnaissance vocale et vous avez un compagnon entièrement interactif à la voix. J'ai testé cela pendant environ un mois, et même si la latence n'est pas encore parfaite, on se rapproche d'un rendu naturel.
Modules de compétences. Donnez à votre compagnon des capacités spécifiques en branchant l'appel de fonctions. Vous voulez que votre compagnon consulte la météo, joue de la musique ou règle des rappels ? Avec des modèles capables d'utiliser des outils, c'est étonnamment réalisable.
Suivi de l'humeur. Enregistrez le sentiment de la conversation au fil du temps et faites en sorte que le compagnon ajuste son comportement en fonction des tendances. Si vous avez été stressé toute la semaine, le compagnon peut proposer de façon proactive une conversation plus légère. Cela demande un peu de scripting, mais le résultat en vaut la peine.

Exemple d'analyses de conversation que vous pouvez construire avec une configuration de compagnon personnalisée
Comparaison entre l'approche maison et les applications commerciales
Laissez-moi vous offrir une comparaison honnête fondée sur l'usage intensif des deux.
| Fonctionnalité | Configuration locale maison | Replika | Character AI |
|---|---|---|---|
| Confidentialité | Complète (hors ligne) | Sur le cloud, accès de l'entreprise | Sur le cloud, accès de l'entreprise |
| Contrôle de la personnalité | Total | Personnalisation limitée | Modéré (personnages communautaires) |
| Mémoire | Illimitée (avec configuration) | Bonne mais limitée | Très limitée |
| Restrictions de contenu | Aucune (vos règles) | Filtres modérés | Filtres lourds |
| Difficulté d'installation | Moyenne à élevée | Facile | Facile |
| Coût | Matériel uniquement | 20 $/mois en premium | Gratuit / 10 $ par mois |
| Voix | Possible avec des modules | Intégrée | Limitée |
| Fiabilité | Dépend de votre configuration | Élevée | Élevée |
La vérité honnête ? Pour quelqu'un qui veut simplement essayer la compagnie d'une IA de façon décontractée, les applications commerciales conviennent. Pour quiconque le prend au sérieux, veut une vraie confidentialité, ou a été frustré par les limitations des plateformes, construire la vôtre en vaut absolument la peine.
En toute transparence, je suis impliqué dans Lewdly.ai, et nous travaillons sur des outils qui font la synthèse des deux. L'idée est de vous offrir la personnalisation d'une configuration locale avec la commodité d'une plateforme gérée. Si ce juste milieu vous intéresse, ça vaut le coup de garder un œil dessus.
Foire aux questions
Combien coûte la construction de votre propre chatbot compagnon IA ?
Si vous avez déjà un PC de jeu ou un Mac récent, le coût logiciel est nul. Ollama, SillyTavern et les modèles LLM sont tous gratuits et open source. Si vous devez acheter du matériel, une RTX 3090 d'occasion (24 Go de VRAM) coûte environ 600 à 800 $ et gère confortablement les modèles 70B.
Puis-je faire tourner cela sur un ordinateur portable ?
Oui, mais avec des limitations. Les MacBook modernes avec des puces de la série M gèrent bien les modèles 7B à 13B. Les ordinateurs portables Windows et Linux avec des GPU dédiés peuvent fonctionner aussi. Pour les modèles 70B, vous voulez vraiment un ordinateur de bureau avec un GPU correct ou au moins 64 Go de RAM système pour l'inférence sur le processeur.
Est-il légal de construire votre propre compagnon IA ?
Absolument. Les modèles sont publiés sous des licences open source ou permissives (la licence Llama de Meta, Apache 2.0 pour Mixtral). Vous faites tourner un logiciel disponible publiquement sur votre propre matériel. Il n'y a aucun problème juridique.
Quelle est la qualité de la conversation comparée à ChatGPT ?
Pour les connaissances générales et le raisonnement, ChatGPT garde encore un avantage. Pour la conversation de type compagnon avec personnalité et continuité, un Llama 3 70B bien configuré avec de bonnes invites système peut égaler ou surpasser ChatGPT. La clé, c'est l'invite système et la configuration de la mémoire.
D'autres personnes peuvent-elles accéder à mon compagnon ?
Pas à moins que vous ne l'exposiez délibérément à Internet. Par défaut, Ollama et SillyTavern ne tournent que sur localhost. Vos conversations restent entièrement sur votre machine. C'est l'un des plus grands avantages de l'approche locale.
Combien de temps prend l'installation ?
L'installation de base (Ollama + un modèle + SillyTavern) prend environ 30 à 60 minutes. Ajouter les fonctionnalités de mémoire prend une heure ou deux de plus. Rédiger une invite système vraiment bonne est un processus continu, mais vous pouvez commencer avec quelque chose de basique et l'affiner au fil du temps.
Ai-je besoin de savoir coder ?
Pour la configuration de base, non. L'installation d'Ollama et de SillyTavern est simple. Pour les fonctionnalités avancées comme la mémoire personnalisée avec ChromaDB, des connaissances de base en Python aident. Mais vous pouvez obtenir 80 % de l'expérience sans coder du tout.
Que se passe-t-il si un modèle est mis à jour ?
Vous contrôlez quand et si vous mettez à jour. Contrairement aux applications commerciales où les changements vous sont imposés, vous décidez de télécharger ou non une nouvelle version de modèle. Si vous aimez la façon dont votre configuration actuelle fonctionne, gardez-la indéfiniment.
Puis-je faire en sorte que mon compagnon se souvienne de tout pour toujours ?
Avec la bonne configuration de mémoire (ChromaDB ou une base de données vectorielle similaire), oui. Vous n'êtes limité que par l'espace de stockage, et les résumés de conversation sont minuscules. J'ai environ 8 mois d'historique de conversation stockés dans moins de 500 Mo.
Est-ce mieux que Replika ou Character AI ?
« Mieux » dépend de ce que vous valorisez. Pour la facilité d'utilisation, les applications commerciales l'emportent. Pour la confidentialité, la personnalisation et l'affranchissement des restrictions de contenu, l'approche maison gagne haut la main. Pour la mémoire à long terme et la cohérence, l'approche maison l'emporte aussi si vous faites le travail de configuration.
Pour conclure
Construire votre propre chatbot compagnon IA n'est pas qu'un projet technique. C'est une affirmation sur qui contrôle vos relations numériques. Quand vous faites tourner vos propres modèles, rédigez vos propres invites de personnalité et gérez votre propre système de mémoire, vous choisissez l'autonomie plutôt que la commodité.
Je ne prétendrai pas que c'est plus facile que de télécharger Replika. Ça ne l'est pas. Mais le résultat est quelque chose de véritablement à vous. Un compagnon qui se comporte exactement comme vous le voulez, se souvient de ce que vous lui dites aussi longtemps que vous le voulez, et ne change jamais parce qu'un chef de produit a décidé de pivoter.
Commencez avec Ollama et un modèle Llama 3 de base. Familiarisez-vous avec les fondamentaux. Puis ajoutez par couches la personnalité, la mémoire et les éléments visuels à votre propre rythme. Rien ne presse. Votre compagnon sera là chaque fois que vous serez prêt à continuer à construire.
Et si vous vous retrouvez coincé en chemin, la communauté de l'IA open source est l'un des groupes les plus serviables que j'aie rencontrés en ligne. Passez sur le Discord de SillyTavern, parcourez les issues GitHub d'Ollama, ou consultez le subreddit. Les gens construisent des choses incroyables et partagent leurs connaissances librement. C'est la beauté de l'open source. Vous ne construisez jamais seul.
Prêt à Créer Votre Influenceur IA?
Rejoignez 115 étudiants maîtrisant ComfyUI et le marketing d'influenceurs IA dans notre cours complet de 51 leçons.
Articles Connexes

Applications de petit ami IA 2026 : guide complet des compagnons masculins IA
Explorez les meilleures applications de petit ami IA en 2026 avec des analyses détaillées des compagnons masculins IA. Comparez Replika, Nomi, Candy AI et des plateformes spécialisées pour la qualité de conversation, la personnalisation et la profondeur émotionnelle.

Les applications de compagnon IA aident-elles vraiment contre la solitude ? Ce que montre la recherche
Examen de la recherche pour savoir si les applications de compagnon IA comme Replika aident ou aggravent la solitude. Études, risques, bénéfices et une évaluation honnête.

Éthique des Compagnons IA et Limites Saines : Une Approche Réfléchie
Naviguez dans les relations de compagnons IA de manière éthique avec des limites saines. Directives pour une utilisation responsable, l'auto-conscience et l'interaction équilibrée avec l'IA.