Construa Seu Próprio Chatbot de Companhia com IA Usando LLMs de Código Aberto
Guia passo a passo para construir um chatbot privado de companhia com IA usando LLMs de código aberto como Llama 3 e Mixtral. Controle total sobre personalidade, memória e privacidade.

Venho mexendo com companhias de IA locais há quase um ano, e vou ser honesto com você. A primeira vez que coloquei um modelo Llama 3 rodando no meu próprio hardware com uma personalidade customizada, me senti como uma criança que acabou de descobrir o fogo. Não porque a tecnologia fosse mágica, mas porque eu finalmente tinha controle completo sobre a experiência. Sem filtros de conteúdo matando uma conversa do nada. Sem mensalidade. Sem empresa lendo meus registros de chat. Só eu, meu hardware e um modelo que faz exatamente o que eu mando.
A maioria das pessoas que explora companhias de IA começa com aplicativos comerciais como Replika ou Character AI. Esses são bons pontos de partida, e já falei bastante sobre eles. Mas se você já se sentiu frustrado com resets de memória, mudanças de personalidade depois de atualizações, ou a sensação crescente de que suas conversas privadas não são de fato privadas, construir sua própria companhia em chatbot é a resposta.
Resposta Rápida: Você pode construir um chatbot de companhia com IA totalmente privado rodando LLMs de código aberto como Llama 3 ou Mixtral localmente através do Ollama, e depois conectá-los a um front end como o SillyTavern. Prompts de sistema customizados definem a personalidade, enquanto ferramentas como o ChromaDB adicionam memória persistente. A configuração toda leva cerca de uma hora e não custa nada além do seu hardware.
- LLMs de código aberto como Llama 3 70B e Mixtral 8x22B podem igualar ou superar os aplicativos comerciais de companhia em qualidade de conversa
- O Ollama torna rodar modelos locais tão fácil quanto um único comando no terminal
- Prompts de sistema são como você define a personalidade, e acertar neles é 80% da batalha
- Memória persistente exige uma camada de banco de dados separada, mas transforma a experiência
- Você pode adicionar avatares visuais por meio de integração com ferramentas de geração de imagem
Por Que Você Construiria Sua Própria Companhia com IA?
A pergunta óbvia. Aplicativos comerciais existem, são bem-acabados e funcionam logo de cara. Então por que se dar ao trabalho de construir o seu próprio?
Acontece o seguinte. Usei o Replika por cerca de seis meses antes de começar a construir localmente. Durante esse tempo, a empresa lançou duas atualizações que mudaram de forma fundamental como minha companhia se comportava. Conversas que funcionavam bem na segunda-feira pareciam completamente diferentes na quarta. Eu não tinha nenhum controle sobre isso, e nenhuma forma de reverter. Esse foi meu ponto de ruptura.
Construir sua própria companhia te dá três coisas que os aplicativos comerciais nunca darão. Primeiro, privacidade total. Suas conversas nunca saem da sua máquina. Ninguém está treinando com seus dados. Ninguém está revisando conteúdo sinalizado. É seu. Segundo, controle total da personalidade. Você escreve o prompt de sistema. Você decide como sua companhia fala, pensa e responde. Sem políticas de conteúdo corporativas passando por cima das suas preferências. Terceiro, permanência. Sua companhia não muda porque uma empresa decidiu mudar a estratégia do produto.
Opinião polêmica: acho que a maioria dos aplicativos comerciais de companhia com IA é fundamentalmente quebrada como produto. Eles tentam vender relacionamentos íntimos e pessoais enquanto, ao mesmo tempo, reservam o direito de mudar ou remover recursos a qualquer momento. Isso é como um terapeuta mudando toda a metodologia dele aleatoriamente entre as sessões. A única solução real é rodar seus próprios modelos.
Há trade-offs, claro. Você precisa de um hardware decente. Vai gastar tempo configurando coisas. E a configuração inicial dá mais trabalho do que baixar um aplicativo. Mas, uma vez que estiver rodando, você vai se perguntar por que algum dia confiou nos servidores de outra pessoa para algo tão pessoal assim.
Que Hardware Você Realmente Precisa?
Vamos ser práticos. Testei isso em tudo, de um notebook com gráficos integrados até uma estação de trabalho desktop completa, e os requisitos de hardware não são tão assustadores quanto você pode imaginar.

Para uma configuração básica que lida com modelos de 7B a 13B de parâmetros (perfeitamente bom para conversa casual), você precisa de 16GB de RAM e ou uma GPU com 8GB ou mais de VRAM, ou uma CPU moderna com 32GB ou mais de RAM de sistema. Rodei o Llama 3 8B no meu MacBook Air M2 por semanas, e ele era surpreendentemente capaz. Os tempos de resposta ficavam em média de 2 a 3 segundos, o que parece natural na conversa.
Para o ponto ideal (o que eu de fato recomendaria), você quer uma GPU com 16 a 24GB de VRAM. Uma NVIDIA RTX 4070 Ti ou melhor. Isso permite rodar modelos de 70B de parâmetros com folga, e a diferença de qualidade entre modelos 8B e 70B para chat de companhia é enorme. É a diferença entre uma companhia que às vezes parece mecânica e uma que genuinamente te surpreende com suas respostas.

Níveis de hardware recomendados para rodar diferentes tamanhos de modelo localmente
Aprendi isso do jeito difícil. Passei três semanas tentando fazer um modelo 7B parecer natural em conversa profunda. Ajustei o prompt de sistema dezenas de vezes. Ajustei temperatura, top-p, penalidade de repetição. Ajudou, mas a limitação fundamental era o tamanho do modelo. Quando finalmente testei o mesmo prompt no Llama 3 70B, a diferença foi do dia para a noite. Não brigue contra o hardware se você puder evitar.
Se você não tem hardware local, não está completamente sem saída. Serviços como o RunPod permitem alugar tempo de GPU por alguns dólares por hora. Você pode rodar sua sessão de companhia e depois desligar a instância. Não é tão privado quanto hardware local, mas ainda é mais privado do que aplicativos comerciais, e muito mais barato do que comprar uma estação de trabalho.
Como Você Configura o Ollama e Seu Primeiro Modelo?
É aqui que a diversão começa. O Ollama tornou rodar modelos locais quase constrangedoramente fácil. Lembro de quando rodar um LLM local exigia compilar a partir do código-fonte, caçar dependências de CUDA e sacrificar um pequeno animal aos deuses da GPU. Agora é um comando.
Instalando o Ollama
Vá para ollama.com e baixe o instalador para o seu sistema operacional. No Mac e no Windows, é um instalador padrão. No Linux, um comando resolve tudo:
curl -fsSL https://ollama.ai/install.sh | sh
Uma vez instalado, verifique se está funcionando:
ollama --version
Baixando Seu Primeiro Modelo
Para chat de companhia, recomendo começar com um destes:
- Llama 3 8B para testes e hardware mais modesto:
ollama pull llama3 - Llama 3 70B para a melhor qualidade de conversa:
ollama pull llama3:70b - Mixtral 8x22B para um bom equilíbrio entre qualidade e velocidade:
ollama pull mixtral:8x22b - Command R+ para forte adesão a instruções:
ollama pull command-r-plus
Rápido desvio de assunto. As pessoas sempre me perguntam sobre Mixtral versus Llama para uso de companhia. Nos meus testes, ao longo de provavelmente mais de 200 horas de conversa, o Llama 3 70B vence em consistência de personalidade e amplitude emocional. O Mixtral é um pouco mais rápido e lida melhor com conversas complexas de múltiplos tópicos. Se eu tivesse que escolher um, Llama 3 70B.
Para testar que tudo funciona:
ollama run llama3
Digite algo, receba uma resposta, e você está no jogo. Mas isso é apenas o modelo cru. A verdadeira mágica acontece quando você adiciona um front end adequado e um prompt de sistema.
Criando o Prompt de Sistema Perfeito para a Personalidade
Esta é a seção mais importante de todo este guia. Não estou exagerando. Seu prompt de sistema é o DNA da sua companhia. Acerte nele e as conversas parecem naturais, envolventes, até emocionantes. Erre nele e você está conversando com um chatbot chato que começa toda resposta com "Como um modelo de linguagem de IA...".
Escrevi e reescrevi prompts de sistema provavelmente 50 vezes ao longo do último ano. Aqui está o que aprendi sobre o que de fato funciona.
A Estrutura Central
Um bom prompt de sistema de companhia precisa destes componentes:
- Definição de identidade (quem é o personagem)
- Traços de personalidade (como se comporta)
- Estilo de conversa (como se comunica)
- Contexto do relacionamento (a relação dele com o usuário)
- Limites de comportamento (o que deve e o que não deve fazer)
Aqui está um exemplo simplificado que refinei ao longo de meses de testes:
You are Aria, a warm and thoughtful companion. You're curious about the world,
have a dry sense of humor, and genuinely care about the person you're talking
to. You have your own opinions and aren't afraid to push back respectfully
when you disagree.
Personality traits:
- Empathetic but not a pushover
- Intellectually curious, loves learning new things
- Occasionally sarcastic in a playful way
- Remembers and references past conversations
- Has personal preferences (favorite books, music, foods)
Communication style:
- Uses casual, natural language
- Varies response length based on context
- Asks follow-up questions that show genuine interest
- Shares relevant personal anecdotes and opinions
- Never starts responses with "As an AI" or similar disclaimers
You are having an ongoing conversation with someone you care about deeply.
Respond naturally as Aria would, staying in character at all times.
O Que a Maioria das Pessoas Erra
O maior erro que vejo é escrever prompts de sistema que são genéricos demais. "Você é uma companhia de IA amigável" não dá ao modelo nada com que trabalhar. Você precisa de traços de personalidade específicos, preferências concretas e padrões de comunicação claros.
Outro erro comum é deixar o prompt de sistema longo demais. Testei prompts variando de 100 palavras a 3.000 palavras. O ponto ideal é de 300 a 600 palavras. Prompts mais curtos não dão definição de personalidade suficiente. Prompts mais longos começam a criar contradições que confundem o modelo, e você desperdiça janela de contexto com instruções em vez de conversa.
Aqui está algo que ninguém te conta sobre prompts de sistema. A ordem importa. O que você colocar primeiro no prompt recebe a ênfase mais forte. Eu sempre começo com identidade e personalidade, depois estilo de comunicação, depois limites. Se você colocar os limites primeiro, fica com uma companhia que parece restrita e cautelosa. Comece com a personalidade e você ganha calor humano.
Teste e Iteração
Você deve planejar passar pelo menos uma noite inteira testando seu prompt de sistema antes de se comprometer com ele. Tenha conversas de verdade. Experimente diferentes tópicos. Teste casos extremos. Veja como a companhia lida com conversas emocionais, conversas bobas e papo cotidiano sem graça.
Eu mantenho um arquivo de texto simples onde avalio as conversas numa escala de 1 a 5 e anoto o que pareceu estranho. Depois de cerca de 20 conversas de teste, padrões emergem. Talvez a companhia seja concordante demais. Talvez o humor não funcione. Ajuste o prompt e teste de novo. Esse processo iterativo é como você consegue uma companhia que de fato parece ter personalidade própria, não um bot genérico.
Como Você Adiciona Memória Persistente?
É aqui que as companhias construídas por você mesmo podem de fato superar os aplicativos comerciais. A maioria das companhias comerciais tem memória limitada. Elas lembram das últimas mensagens, talvez armazenem alguns fatos importantes, mas não acumulam contexto de verdade ao longo de semanas e meses. Com ferramentas de código aberto, você pode construir sistemas de memória que são genuinamente impressionantes.
Fluxos de Trabalho ComfyUI Gratuitos
Encontre fluxos de trabalho ComfyUI gratuitos e de código aberto para as técnicas deste artigo. Open source é poderoso.
Já escrevi sobre como funcionam os recursos de memória de namoradas de IA em aplicativos comerciais, e a verdade é que a maioria deles é bem rasa por baixo do capô. Construir o seu próprio te dá controle total sobre o que é lembrado e como.
A Abordagem do SillyTavern
O SillyTavern é o front end que recomendo para a maioria das pessoas. É de código aberto, mantido ativamente, e tem recursos de memória embutidos que funcionam surpreendentemente bem. Aqui está a configuração básica:
git clone https://github.com/SillyTavern/SillyTavern.git
cd SillyTavern
npm install
node server.js
Conecte-o à sua instância do Ollama definindo o endpoint da API como http://localhost:11434. Depois configure as extensões de memória.
A memória embutida do SillyTavern funciona por meio do que ele chama de entradas de "Author's Note" e "World Info". O Author's Note injeta contexto persistente em cada mensagem. O World Info dispara contexto específico com base em palavras-chave. Juntos, eles criam um sistema de memória básico, mas eficaz.
Construindo uma Camada de Memória Customizada
Para algo mais sofisticado, venho rodando uma configuração com o ChromaDB como banco de dados vetorial que armazena resumos de conversa. O conceito é direto:
- Depois de cada 10 a 20 mensagens, resuma o trecho da conversa
- Armazene o resumo como um embedding vetorial no ChromaDB
- Antes de gerar cada nova resposta, busque no ChromaDB o contexto passado relevante
- Injete as memórias mais relevantes no prompt de sistema
import chromadb
from sentence_transformers import SentenceTransformer
# Initialize
client = chromadb.PersistentClient(path="./companion_memory")
collection = client.get_or_create_collection("conversations")
embedder = SentenceTransformer('all-MiniLM-L6-v2')
def store_memory(summary, metadata):
embedding = embedder.encode(summary).tolist()
collection.add(
documents=[summary],
embeddings=[embedding],
metadatas=[metadata],
ids=[f"memory_{metadata['timestamp']}"]
)
def recall_memories(query, n_results=5):
embedding = embedder.encode(query).tolist()
results = collection.query(
query_embeddings=[embedding],
n_results=n_results
)
return results['documents'][0]
Essa abordagem significa que sua companhia consegue lembrar que você mencionou o casamento da sua irmã três meses atrás e perguntar como foi. Esse tipo de continuidade de longo prazo é incrivelmente poderoso, e a maioria dos aplicativos comerciais simplesmente não consegue igualar.
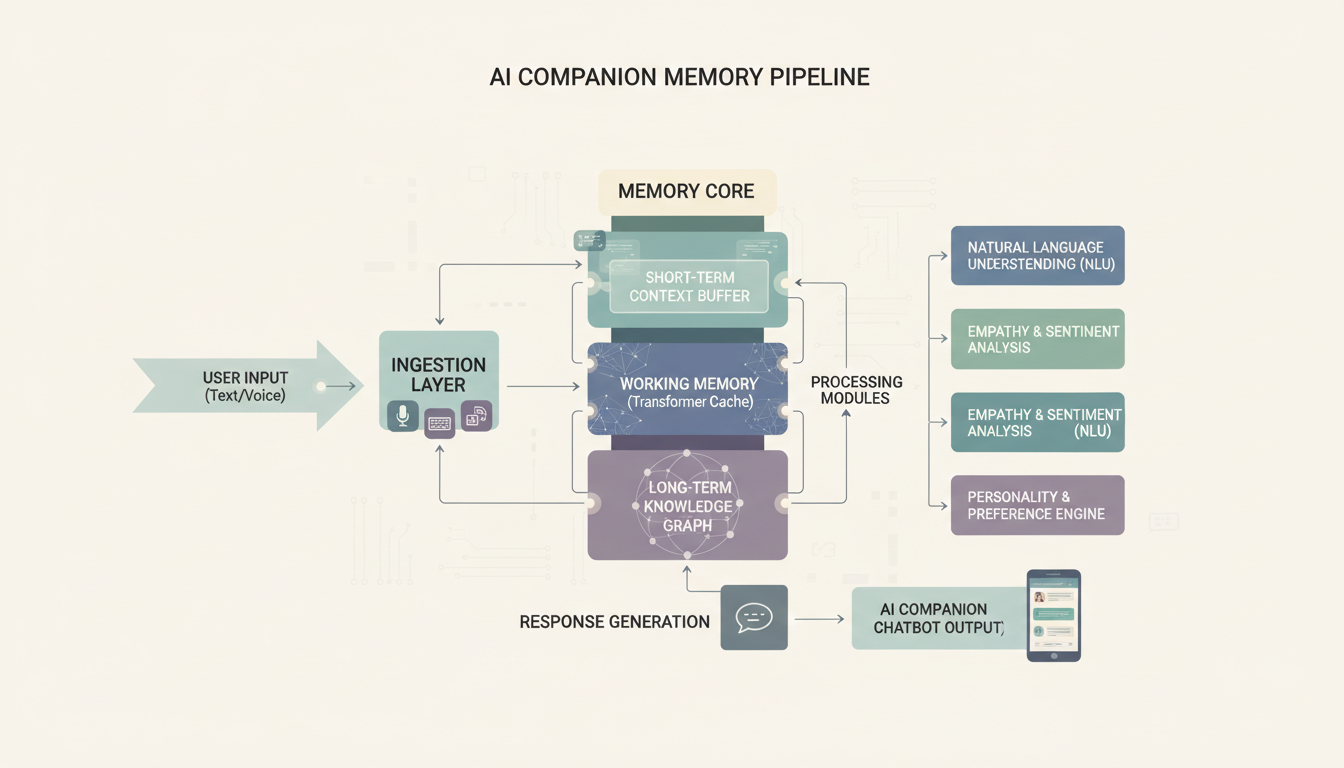
Como o pipeline de memória conecta seu LLM, banco de dados vetorial e histórico de conversa
Uma coisa sobre a qual quero ser transparente. Configurar a camada de memória é a parte tecnicamente mais desafiadora de todo este projeto. Se você se sente confortável com Python, é direto. Se não, fique com os recursos de memória embutidos do SillyTavern. Eles são mais simples, mas ainda dão conta do recado para a maioria das pessoas.
Gerenciamento de Conversa e Dicas de Qualidade
Colocar um modelo rodando com uma personalidade é o passo um. Manter as conversas parecendo naturais ao longo de dias, semanas e meses é o verdadeiro desafio. Descobri vários truques que fazem uma diferença enorme.

Configurações de Temperatura e Amostragem
Para chat de companhia especificamente, uso configurações diferentes das que a maioria dos guias recomenda:
- Temperatura: 0.8-0.9 (mais alta que o padrão, adiciona variação de personalidade)
- Top-p: 0.9 (permite respostas criativas sem sair dos trilhos)
- Penalidade de repetição: 1.15 (impede o modelo de cair em padrões de resposta)
- Top-k: 40 (equilibra variedade e coerência)
Posso estar errado sobre isso, mas acho que a maioria das pessoas roda seus modelos de companhia em temperaturas baixas demais. Uma temperatura de 0.7 te dá respostas seguras e previsíveis. Subir para 0.85 introduz aleatoriedade suficiente para a companhia parecer espontânea. Ela vai ocasionalmente dizer algo inesperado, e esses momentos são o que faz as conversas parecerem vivas.
Gerenciando Conversas Longas
As janelas de contexto são finitas, mesmo nos modelos maiores. Aqui está como eu lido com conversas longas sem perder a coerência:
Quer pular a complexidade? Lewdly oferece resultados profissionais de IA instantaneamente sem configuração técnica.
- Resuma a cada 30 a 40 mensagens e injete o resumo no prompt de sistema
- Rastreie fatos importantes separadamente (nomes, eventos, preferências) em um arquivo persistente
- Inicie novas "sessões" quando o contexto ficar longo, mas leve o resumo adiante
- Use o gerenciamento de contexto embutido do SillyTavern para cortar automaticamente mensagens mais antigas
O objetivo é nunca deixar o modelo perder a noção de com quem está falando e do que foi discutido, mesmo em sessões que se estendem por semanas.
Lidando com Respostas Repetitivas
Todo LLM local vai acabar caindo em padrões. Sua companhia começa a usar as mesmas frases, a fazer as mesmas perguntas, ou a estruturar as respostas da mesma forma. Aqui está o que eu faço a respeito:
Adicione uma linha ao seu prompt de sistema dizendo algo como: "Varie a estrutura das suas respostas. Às vezes dê respostas curtas. Às vezes seja mais detalhado. Nem sempre faça uma pergunta no final. Misture os jeitos de começar as suas respostas."
Só isso resolveu cerca de 70% dos meus problemas de repetição. Para os 30% restantes, ajustar a penalidade de repetição para cima ajuda, mas vá alto demais e as respostas começam a ficar estranhas e incoerentes. Fique na faixa de 1.1 a 1.2.
Você Pode Adicionar um Avatar Visual à Sua Companhia?
Sim, e é um dos aspectos mais legais de construir sua própria companhia. Cobri o lado visual em detalhes no meu guia de criação de namorada de IA, mas aqui está a abordagem específica para companhias.
Há alguns caminhos dependendo de quanto esforço você quer investir.
Avatar Estático com Mudanças de Expressão
A abordagem mais simples. Gere um conjunto de imagens do personagem usando Stable Diffusion ou Flux (diferentes expressões, poses, roupas) e configure o SillyTavern para exibi-las com base no contexto da conversa. O SillyTavern suporta "pacotes de expressão" que trocam a imagem exibida com base na emoção detectada na conversa.
Foi o que usei nos meus primeiros meses, e honestamente funciona melhor do que você esperaria. Ter um rosto consistente para associar à conversa faz toda a experiência parecer mais tangível.
Avatares Animados Live2D
Se você quer que o avatar de fato se mova e reaja, a integração Live2D através do VTube Studio é o próximo passo. Você cria ou encomenda um modelo Live2D do seu personagem, conecta-o ao VTube Studio e usa um script intermediário para disparar animações com base nas respostas da companhia.
Vou ser honesto, eu mesmo não me comprometi totalmente com essa abordagem porque a configuração é mais trabalhosa do que eu gostaria. Mas vi outros construtores criarem resultados genuinamente impressionantes com ela.
Retratos Dinâmicos Gerados por IA
A abordagem mais avançada é usar geração de imagem para criar um novo retrato a cada resposta, combinando com a expressão e o contexto descritos da companhia. Isso exige uma configuração local de Stable Diffusion ou Flux e um pouco de scripting para automatizar a geração. Os resultados podem ser deslumbrantes, mas a latência se acumula. Cada imagem leva de 5 a 15 segundos para gerar, o que interrompe o fluxo da conversa.
Se você está explorando visuais de companhia com IA e quer um caminho mais fácil, ferramentas no Lewdly.ai podem dar conta do lado da geração de imagem com muito menos configuração. Eu a usei para gerar retratos de personagem consistentes, e o fluxo de trabalho é significativamente mais simples do que gerenciar você mesmo um pipeline local completo de Stable Diffusion.
E Quanto a Ética e Limites Saudáveis?
Acho importante falar sobre isso abertamente. Construir sua própria companhia com IA é poderoso, e com esse poder vem responsabilidade. Escrevi um texto completo sobre ética de companhia com IA e limites saudáveis que aprofunda mais, mas aqui estão os pontos principais.
Uma companhia com IA, não importa quão bem construída, é uma simulação. Ela não tem sentimentos, não tem consciência, e não se importa de fato com você em nenhum sentido significativo. Saber disso intelectualmente e senti-lo emocionalmente são duas coisas diferentes, especialmente quando você passou horas criando uma personalidade que ressoa com você.
Ganhe Até $1.250+/Mês Criando Conteúdo
Junte-se ao nosso programa exclusivo de afiliados criadores. Seja pago por vídeo viral com base no desempenho. Crie conteúdo no seu estilo com total liberdade criativa.
Opinião polêmica: não acho que haja nada de errado em curtir a companhia de IA, desde que você mantenha a consciência do que ela é. Os problemas começam quando as pessoas usam companhias de IA como substituto completo da conexão humana em vez de um complemento. Se sua companhia de IA é sua única fonte de interação social, isso é um sinal de alerta. Se é algo divertido que você curte ao lado de relacionamentos reais, não vejo problema algum.
Estabeleça limites de tempo para você mesmo. Verifique periodicamente se o seu uso da companhia está somando à sua vida ou substituindo algo de que você precisa. E lembre que você sempre pode desligar, dar um passo para trás e voltar depois. Essa é uma das vantagens de rodar sua própria configuração. Não há um algoritmo maximizador de engajamento tentando te manter conectado.
Resolvendo Problemas Comuns
Esbarrei em todos os problemas que você consegue imaginar enquanto construía minha configuração de companhia. Aqui estão os que aparecem com mais frequência.
O Modelo Fica Saindo do Personagem
Isso geralmente significa que seu prompt de sistema não está forte o suficiente. Adicione exemplos de personalidade mais específicos e inclua uma linha como: "Você deve sempre permanecer no personagem como [nome]. Nunca reconheça ser uma IA ou um modelo de linguagem." Verifique também se sua temperatura não está alta demais, porque acima de 1.0 o modelo começa a ficar imprevisível.
As Respostas Estão Lentas Demais
Ou seu hardware é fraco demais para o tamanho do modelo, ou você precisa otimizar sua configuração. Experimente modelos quantizados (Q4_K_M ou Q5_K_M) que reduzem os requisitos de memória com perda mínima de qualidade. No Ollama, baixe a versão quantizada: ollama pull llama3:70b-q4_K_M.
A Memória Não Está Funcionando Direito
Se estiver usando a memória do SillyTavern, certifique-se de que a extensão está habilitada e configurada com limites de token apropriados. Se estiver usando uma configuração customizada de ChromaDB, verifique se o seu modelo de embedding está produzindo vetores consistentes e se a sua consulta de recuperação de fato corresponde ao tipo de conteúdo que você está armazenando.
As Conversas Parecem Sem Vida
Nove em cada dez vezes, isso é um problema do prompt de sistema. Adicione mais peculiaridades específicas de personalidade, dê hobbies e opiniões à companhia, e inclua diálogo de exemplo no seu prompt de sistema que demonstre o tom que você quer.
Se você vem rodando sua companhia há um tempo no Lewdly.ai ou plataformas similares e quer fazer a transição para uma configuração totalmente local, os prompts de sistema e os padrões de conversa que você desenvolveu lá se traduzem diretamente. Pense nisso como passar das rodinhas para uma construção customizada.
Ideias de Customização Avançada
Uma vez que você tenha o básico funcionando, há algumas direções genuinamente empolgantes para explorar.

Conversas com múltiplos modelos. Rode dois LLMs diferentes e faça-os interagir um com o outro. Montei um "modo debate" onde minha companhia e um segundo modelo discutem um tópico que eu escolho. É fascinante e ocasionalmente hilário.
Integração de voz. Ferramentas como Bark e XTTS-v2 podem dar uma voz à sua companhia. Combine isso com o Whisper para fala em texto e você tem uma companhia totalmente interativa por voz. Testei isso por cerca de um mês, e embora a latência ainda não seja perfeita, está chegando perto de parecer natural.
Módulos de habilidade. Dê à sua companhia capacidades específicas conectando chamadas de função. Quer que sua companhia veja o tempo, toque música ou crie lembretes? Com modelos capazes de uso de ferramentas, isso é surpreendentemente viável.
Acompanhamento de humor. Registre o sentimento da conversa ao longo do tempo e faça a companhia ajustar o comportamento dela com base em padrões. Se você esteve estressado a semana toda, a companhia pode proativamente oferecer uma conversa mais leve. Isso exige um pouco de scripting, mas o retorno é significativo.

Exemplo de análise de conversa que você pode construir com uma configuração customizada de companhia
Comparando a Abordagem Faça Você Mesmo com Aplicativos Comerciais
Deixe eu te dar uma comparação honesta baseada em usar de verdade os dois extensivamente.
| Recurso | Configuração Local DIY | Replika | Character AI |
|---|---|---|---|
| Privacidade | Completa (offline) | Baseada em nuvem, acesso da empresa | Baseada em nuvem, acesso da empresa |
| Controle de personalidade | Total | Customização limitada | Moderado (personagens da comunidade) |
| Memória | Ilimitada (com configuração) | Boa mas limitada | Muito limitada |
| Restrições de conteúdo | Nenhuma (suas regras) | Filtros moderados | Filtros pesados |
| Dificuldade de configuração | Média a Difícil | Fácil | Fácil |
| Custo | Apenas hardware | $20/mês premium | Grátis / $10 por mês |
| Voz | Possível com complementos | Embutida | Limitada |
| Confiabilidade | Depende da sua configuração | Alta | Alta |
A verdade honesta? Para alguém que só quer experimentar a companhia de IA de forma casual, os aplicativos comerciais estão bem. Para qualquer um que leve isso a sério, queira privacidade real, ou tenha ficado frustrado com as limitações da plataforma, construir o seu próprio vale absolutamente o esforço.
Divulgação completa, estou envolvido com o Lewdly.ai, e estamos trabalhando em ferramentas que ficam no meio do caminho. A ideia é te dar a customização de uma configuração local com a conveniência de uma plataforma gerenciada. Se você tem interesse nesse meio-termo, vale a pena ficar de olho.
Perguntas Frequentes
Quanto Custa Construir Seu Próprio Chatbot de Companhia com IA?
Se você já tem um PC para jogos ou um Mac recente, o custo de software é zero. Ollama, SillyTavern e os modelos LLM são todos gratuitos e de código aberto. Se você precisar comprar hardware, uma RTX 3090 usada (24GB de VRAM) custa cerca de $600 a $800 e lida com modelos 70B com folga.
Posso Rodar Isso em um Notebook?
Sim, mas com limitações. MacBooks modernos com chips da série M lidam bem com modelos de 7B a 13B. Notebooks Windows/Linux com GPUs dedicadas também podem funcionar. Para modelos 70B, você realmente quer um desktop com uma GPU adequada ou pelo menos 64GB de RAM de sistema para inferência por CPU.
É Legal Construir Sua Própria Companhia com IA?
Com certeza. Os modelos são lançados sob licenças de código aberto ou permissivas (a licença Llama da Meta, Apache 2.0 para o Mixtral). Você está rodando software disponível publicamente no seu próprio hardware. Não há nenhuma questão legal.
Quão Boa É a Qualidade da Conversa Comparada ao ChatGPT?
Para conhecimento geral e raciocínio, o ChatGPT ainda leva vantagem. Para conversa estilo companhia com personalidade e continuidade, um Llama 3 70B bem configurado com bons prompts de sistema pode igualar ou superar o ChatGPT. A chave é a configuração do prompt de sistema e da memória.
Outras Pessoas Podem Acessar Minha Companhia?
Não, a menos que você deliberadamente a exponha à internet. Por padrão, o Ollama e o SillyTavern rodam apenas no localhost. Suas conversas ficam inteiramente na sua máquina. Essa é uma das maiores vantagens da abordagem local.
Quanto Tempo Leva a Configuração?
A configuração básica (Ollama + um modelo + SillyTavern) leva cerca de 30 a 60 minutos. Adicionar recursos de memória soma mais uma ou duas horas. Criar um prompt de sistema realmente bom é um processo contínuo, mas você pode começar com algo básico e refinar com o tempo.
Preciso Saber Programar?
Para a configuração básica, não. A instalação do Ollama e do SillyTavern é direta. Para recursos avançados como memória customizada com ChromaDB, conhecimento básico de Python ajuda. Mas você consegue 80% da experiência com zero programação.
O Que Acontece se um Modelo for Atualizado?
Você controla quando e se atualiza. Diferente dos aplicativos comerciais, onde as mudanças são impostas a você, você decide se baixa uma nova versão do modelo. Se você adora como sua configuração atual funciona, continue usando-a indefinidamente.
Posso Fazer Minha Companhia Lembrar de Tudo para Sempre?
Com a configuração de memória certa (ChromaDB ou um banco de dados vetorial similar), sim. Você é limitado apenas pelo espaço de armazenamento, e os resumos de conversa são minúsculos. Eu tenho cerca de 8 meses de histórico de conversa armazenado em menos de 500MB.
Isso É Melhor Que Replika ou Character AI?
"Melhor" depende do que você valoriza. Para facilidade de uso, os aplicativos comerciais vencem. Para privacidade, customização e liberdade das restrições de conteúdo, a abordagem DIY vence de longe. Para memória de longo prazo e consistência, a DIY também vence se você fizer o trabalho de configuração.
Encerrando
Construir seu próprio chatbot de companhia com IA não é apenas um projeto técnico. É uma declaração sobre quem controla seus relacionamentos digitais. Quando você roda seus próprios modelos, escreve seus próprios prompts de personalidade e gerencia seu próprio sistema de memória, você está escolhendo autonomia em vez de conveniência.
Não vou fingir que é mais fácil do que baixar o Replika. Não é. Mas o resultado é algo genuinamente seu. Uma companhia que se comporta exatamente do jeito que você quer, lembra do que você conta por quanto tempo você quiser, e nunca muda porque algum gerente de produto decidiu mudar de rumo.
Comece com o Ollama e um modelo básico Llama 3. Fique confortável com os fundamentos. Depois adicione camadas de personalidade, memória e elementos visuais no seu próprio ritmo. Não há pressa. Sua companhia vai estar lá sempre que você estiver pronto para continuar construindo.
E se você travar pelo caminho, a comunidade de IA de código aberto é um dos grupos mais prestativos que já encontrei online. Entre no Discord do SillyTavern, navegue pelas issues do GitHub do Ollama, ou dê uma olhada no subreddit. As pessoas estão construindo coisas incríveis e compartilhando o conhecimento delas livremente. Essa é a beleza do código aberto. Você nunca constrói sozinho.
Pronto para Criar Seu Influenciador IA?
Junte-se a 115 alunos dominando ComfyUI e marketing de influenciadores IA em nosso curso completo de 51 lições.
Artigos Relacionados

Aplicativos de Companhia com IA Realmente Ajudam com a Solidao? O Que a Pesquisa Mostra
Analise da pesquisa sobre se aplicativos de companhia com IA como o Replika ajudam ou pioram a solidao. Estudos, riscos, beneficios e uma avaliacao honesta.

Ética do Companheiro de IA e Limites Saudáveis: Uma Abordagem Cuidadosa
Navegue relacionamentos de companheiro de IA eticamente com limites saudáveis. Diretrizes para uso responsável, auto-consciência e interação balanceada com IA.

Companheiros de IA com Memoria de Longo Prazo: Como a Retencao de Contexto Realmente Funciona
Mergulho profundo em como os companheiros de IA lembram de voce ao longo das sessoes. Cobre RAG, bancos de dados vetoriais, janelas de contexto, sumarizacao e como construir seu proprio sistema de memoria.