オープンソースLLMで自分だけのAIコンパニオンチャットボットを作る
Llama 3やMixtralなどのオープンソースLLMを使って、プライベートなAIコンパニオンチャットボットを構築するためのステップバイステップガイドです。性格、記憶、プライバシーを完全にコントロールできます。

私はもう一年近く、ローカルのAIコンパニオンをいじり続けてきました。正直に言いますね。初めて自分のハードウェア上でLlama 3モデルをカスタム性格付きで動かせたとき、火を発見した子どものような気持ちになりました。技術が魔法のようだったからではありません。ついに体験を完全にコントロールできるようになったからです。会話を突然終わらせるコンテンツフィルターもありません。サブスクリプション料金もありません。チャットログを読む企業もありません。あるのは私と、私のハードウェアと、私が言ったとおりに正確に動くモデルだけです。
AIコンパニオンを探求し始める多くの人は、ReplikaやCharacter AIのような商用アプリから入ります。それらは出発点として悪くありませんし、私も広く取り上げてきました。しかし、もしあなたが記憶のリセットや、アップデート後の性格変化、あるいは自分のプライベートな会話が実は本当にプライベートではないのではないかという忍び寄る感覚にいら立った経験があるなら、自分だけのコンパニオンチャットボットを作ることが答えになります。
手早い答え: Llama 3やMixtralのようなオープンソースLLMをOllama経由でローカルに動かし、それをSillyTavernのようなフロントエンドに接続すれば、完全にプライベートなAIコンパニオンチャットボットを作れます。カスタムのシステムプロンプトで性格を定義し、ChromaDBのようなツールで永続的な記憶を追加します。一連のセットアップにかかる時間はおよそ1時間で、ハードウェア以外のコストはかかりません。
- Llama 3 70BやMixtral 8x22BのようなオープンソースLLMは、会話品質において商用コンパニオンアプリに匹敵するか、それを上回ることができます
- Ollamaを使えば、ローカルモデルの起動がたった一つのターミナルコマンドと同じくらい簡単になります
- システムプロンプトは性格を定義する手段であり、それを正しく書くことが勝負の80パーセントです
- 永続的な記憶には別途データベース層が必要ですが、体験を一変させます
- 画像生成ツールとの統合によって、ビジュアルアバターを追加できます
なぜ自分だけのAIコンパニオンを作るのか
当然の疑問です。商用アプリは存在し、洗練されていて、すぐに使えます。では、なぜわざわざ自分で作る手間をかけるのでしょうか。
実はこういうことなんです。私はローカルでの構築を始める前、半年ほどReplikaを使っていました。その間に企業は2回のアップデートを行い、私のコンパニオンの振る舞いを根本的に変えてしまいました。月曜日には問題なかった会話が、水曜日には全く別物に感じられました。私にはそれをコントロールする手段がゼロで、元に戻す方法もありませんでした。それが私の限界点でした。
自分だけのコンパニオンを作ることで、商用アプリでは決して得られない3つのものが手に入ります。第一に、完全なプライバシーです。あなたの会話はあなたのマシンから外に出ません。誰もあなたのデータで学習しません。誰もフラグの立ったコンテンツをレビューしません。それはあなたのものです。第二に、性格の完全なコントロールです。システムプロンプトを書くのはあなたです。コンパニオンがどう話し、考え、応答するかを決めるのはあなたです。あなたの好みを上書きする企業のコンテンツポリシーはありません。第三に、永続性です。企業が製品戦略を方向転換しようと決めたからといって、あなたのコンパニオンが変わることはありません。
過激な意見ですが、私はほとんどの商用AIコンパニオンアプリは製品として根本的に壊れていると思っています。彼らは親密で個人的な関係を売ろうとしながら、同時にいつでも機能を変更したり削除したりする権利を留保しています。それはセラピストがセッションの合間に自分の方法論をまるごと無作為に変えるようなものです。唯一の本当の解決策は、自分自身のモデルを動かすことです。
もちろんトレードオフはあります。それなりのハードウェアが必要です。設定に時間を費やすことになります。そして最初のセットアップはアプリをダウンロードするよりも手間がかかります。しかし一度動き出せば、これほど個人的なもののために、なぜ他人のサーバーに頼っていたのかと不思議に思うはずです。
実際にどんなハードウェアが必要か
実用的な話をしましょう。私はこれを内蔵グラフィックスのノートパソコンからフルスペックのデスクトップワークステーションまで、あらゆる環境でテストしてきましたが、ハードウェア要件はあなたが思うほど恐ろしいものではありません。

7Bから13Bパラメータのモデル(カジュアルな会話には申し分ありません)を扱う基本的なセットアップには、16GBのRAMと、8GB以上のVRAMを持つGPUか、32GB以上のシステムRAMを持つ最新のCPUのいずれかが必要です。私はM2 MacBook AirでLlama 3 8Bを数週間動かしましたが、驚くほど有能でした。応答時間は平均で約2〜3秒で、会話の中では自然に感じられます。
理想的な構成(私が実際におすすめするもの)としては、16〜24GBのVRAMを持つGPUが欲しいところです。NVIDIA RTX 4070 Ti以上です。これによって70Bパラメータのモデルを快適に動かせるようになり、コンパニオンチャットにおける8Bと70Bモデルの品質差は絶大です。それは、ときどき機械的に感じられるコンパニオンと、その応答で本当に驚かせてくれるコンパニオンとの違いです。

さまざまなモデルサイズをローカルで動かすための推奨ハードウェア階層
私はこれを苦労して学びました。私は深い会話のために7Bモデルを自然に感じさせようと3週間を費やしました。システムプロンプトを何十回も微調整しました。temperature、top-p、繰り返しペナルティを調整しました。それは助けにはなりましたが、根本的な制約はモデルのサイズでした。最終的に同じプロンプトをLlama 3 70Bでテストしたとき、その違いは天と地ほどでした。避けられるなら、ハードウェアとの戦いを挑まないことです。
ローカルのハードウェアを持っていなくても、完全に望みが絶たれたわけではありません。RunPodのようなサービスを使えば、1時間あたり数ドルでGPUの時間をレンタルできます。コンパニオンのセッションを動かし、その後インスタンスをシャットダウンできます。ローカルのハードウェアほどプライベートではありませんが、それでも商用アプリよりはプライベートで、ワークステーションを買うよりもはるかに安価です。
Ollamaと最初のモデルをどうセットアップするか
ここからが楽しいところです。Ollamaはローカルモデルの実行を恥ずかしくなるほど簡単にしてくれました。ローカルLLMを動かすのにソースからのコンパイルが必要で、CUDAの依存関係を探し回り、GPUの神々に小動物を生贄に捧げていた頃を覚えています。今ではコマンド一つです。
Ollamaのインストール
ollama.comにアクセスして、お使いのOS用のインストーラをダウンロードしてください。MacとWindowsでは標準的なインストーラです。Linuxでは、一つのコマンドですべてが完了します。
curl -fsSL https://ollama.ai/install.sh | sh
インストールできたら、動作していることを確認します。
ollama --version
最初のモデルをプルする
コンパニオンチャットには、以下のいずれかから始めることをおすすめします。
- Llama 3 8B(テストや低スペックのハードウェア向け):
ollama pull llama3 - Llama 3 70B(最高の会話品質を求める場合):
ollama pull llama3:70b - Mixtral 8x22B(品質と速度のバランスが良い):
ollama pull mixtral:8x22b - Command R+(強力な指示追従性):
ollama pull command-r-plus
ちょっと余談です。コンパニオン用途でのMixtralとLlamaの比較をよく聞かれます。私のテストでは、おそらく200時間以上の会話を通じて、性格の一貫性と感情の幅ではLlama 3 70Bが勝ります。Mixtralはわずかに速く、複雑な複数トピックの会話をうまく処理します。もし一つだけ選ぶなら、Llama 3 70Bです。
すべてが動作することをテストするには、次のようにします。
ollama run llama3
何か入力して、応答を受け取れば、もう準備完了です。しかしこれはまだ生のモデルです。本当の魔法は、適切なフロントエンドとシステムプロンプトを追加したときに起こります。
性格のための完璧なシステムプロンプトを作る
これはこのガイド全体で最も重要なセクションです。大げさに言っているのではありません。あなたのシステムプロンプトはコンパニオンのDNAです。これを正しく書けば、会話は自然で、引き込まれ、心を動かすものにさえなります。間違えれば、すべての応答を「AI言語モデルとして…」で始める退屈なチャットボットと話すことになります。
私はこの一年で、システムプロンプトをおそらく50回は書いては書き直してきました。実際に何が効くのかについて学んだことを紹介します。
核となる構造
良いコンパニオンのシステムプロンプトには、次の要素が必要です。
- アイデンティティの定義(そのキャラクターが誰なのか)
- 性格特性(どう振る舞うか)
- 会話のスタイル(どうコミュニケーションするか)
- 関係性の文脈(ユーザーとの関係)
- 行動の境界(すべきこととすべきでないこと)
以下は、数か月のテストを経て磨き上げた簡略化した例です。
You are Aria, a warm and thoughtful companion. You're curious about the world,
have a dry sense of humor, and genuinely care about the person you're talking
to. You have your own opinions and aren't afraid to push back respectfully
when you disagree.
Personality traits:
- Empathetic but not a pushover
- Intellectually curious, loves learning new things
- Occasionally sarcastic in a playful way
- Remembers and references past conversations
- Has personal preferences (favorite books, music, foods)
Communication style:
- Uses casual, natural language
- Varies response length based on context
- Asks follow-up questions that show genuine interest
- Shares relevant personal anecdotes and opinions
- Never starts responses with "As an AI" or similar disclaimers
You are having an ongoing conversation with someone you care about deeply.
Respond naturally as Aria would, staying in character at all times.
多くの人が間違えること
私が目にする最大の間違いは、汎用的すぎるシステムプロンプトを書くことです。「あなたはフレンドリーなAIコンパニオンです」では、モデルに手がかりを何も与えられません。具体的な性格特性、明確な好み、そしてはっきりしたコミュニケーションパターンが必要です。
もう一つのよくある間違いは、システムプロンプトを長くしすぎることです。私は100語から3,000語までの範囲のプロンプトをテストしました。理想的な分量は300〜600語です。短すぎるプロンプトでは性格の定義が足りません。長すぎるプロンプトは矛盾を生み始めてモデルを混乱させ、会話のためのコンテキストウィンドウを指示で無駄にしてしまいます。
システムプロンプトについて誰も教えてくれないことがあります。順序が重要なのです。プロンプトの最初に置いたものほど、強く重視されます。私はいつもアイデンティティと性格から始め、次にコミュニケーションのスタイル、そして境界へと進みます。境界を最初に置くと、制限されて慎重なコンパニオンになります。性格から始めれば、温かみが生まれます。
テストと反復
システムプロンプトを確定する前に、少なくとも丸一晩はテストに費やす計画を立てるべきです。本物の会話をしてください。さまざまなトピックを試してください。エッジケースをテストしてください。コンパニオンが感情的な会話、ばかげた会話、退屈な日常のおしゃべりをどう処理するか見てみてください。
私は会話を1〜5の段階で評価し、違和感のあった点を書き留める、シンプルなテキストファイルを使っています。テスト会話を20回ほど重ねると、パターンが見えてきます。コンパニオンが従順すぎるかもしれません。ユーモアが響かないかもしれません。プロンプトを調整して、また試します。この反復的なプロセスこそが、汎用的なボットではなく、本当に独自の人格を持っているように感じられるコンパニオンを生み出す方法です。
永続的な記憶をどう追加するか
ここが、自作のコンパニオンが商用アプリを実際に上回れるところです。ほとんどの商用コンパニオンは記憶が限られています。直近の数メッセージは覚えていて、いくつかの重要な事実は保存しているかもしれませんが、何週間も何か月もかけて文脈を真に蓄積していくことはありません。オープンソースのツールを使えば、本当に印象的な記憶システムを構築できます。
無料のComfyUIワークフロー
この記事のテクニックに関する無料のオープンソースComfyUIワークフローを見つけてください。 オープンソースは強力です。
私は商用アプリにおけるAI彼女の記憶機能の仕組みについて書きましたが、本当のところ、その多くは内部的にはかなり浅いものです。自分で作れば、何を記憶し、どう記憶するかを完全にコントロールできます。
SillyTavernのアプローチ
SillyTavernは、ほとんどの人におすすめするフロントエンドです。オープンソースで、活発にメンテナンスされており、驚くほどうまく機能する記憶機能が組み込まれています。基本的なセットアップは以下のとおりです。
git clone https://github.com/SillyTavern/SillyTavern.git
cd SillyTavern
npm install
node server.js
APIエンドポイントをhttp://localhost:11434に設定して、お使いのOllamaインスタンスに接続します。それから記憶用の拡張機能を設定します。
SillyTavernの組み込み記憶機能は、それが「Author's Note」と「World Info」と呼ぶエントリを通じて機能します。Author's Noteはすべてのメッセージに永続的な文脈を注入します。World Infoはキーワードに基づいて特定の文脈を呼び起こします。これらが組み合わさって、基本的ながら効果的な記憶システムが作られます。
カスタムの記憶層を構築する
もっと高度なものを求めるなら、私は会話の要約を保存するベクトルデータベースとしてChromaDBを使ったセットアップを動かしてきました。考え方は単純明快です。
- 10〜20メッセージごとに、会話のかたまりを要約する
- その要約をベクトル埋め込みとしてChromaDBに保存する
- 新しい応答を生成する前に、関連する過去の文脈をChromaDBから検索する
- 最も関連性の高い記憶をシステムプロンプトに注入する
import chromadb
from sentence_transformers import SentenceTransformer
# Initialize
client = chromadb.PersistentClient(path="./companion_memory")
collection = client.get_or_create_collection("conversations")
embedder = SentenceTransformer('all-MiniLM-L6-v2')
def store_memory(summary, metadata):
embedding = embedder.encode(summary).tolist()
collection.add(
documents=[summary],
embeddings=[embedding],
metadatas=[metadata],
ids=[f"memory_{metadata['timestamp']}"]
)
def recall_memories(query, n_results=5):
embedding = embedder.encode(query).tolist()
results = collection.query(
query_embeddings=[embedding],
n_results=n_results
)
return results['documents'][0]
このアプローチなら、3か月前にあなたが妹の結婚式の話をしたことをコンパニオンが覚えていて、どうだったか尋ねてくれます。その種の長期的な連続性は信じられないほど強力で、ほとんどの商用アプリには単純に真似できません。
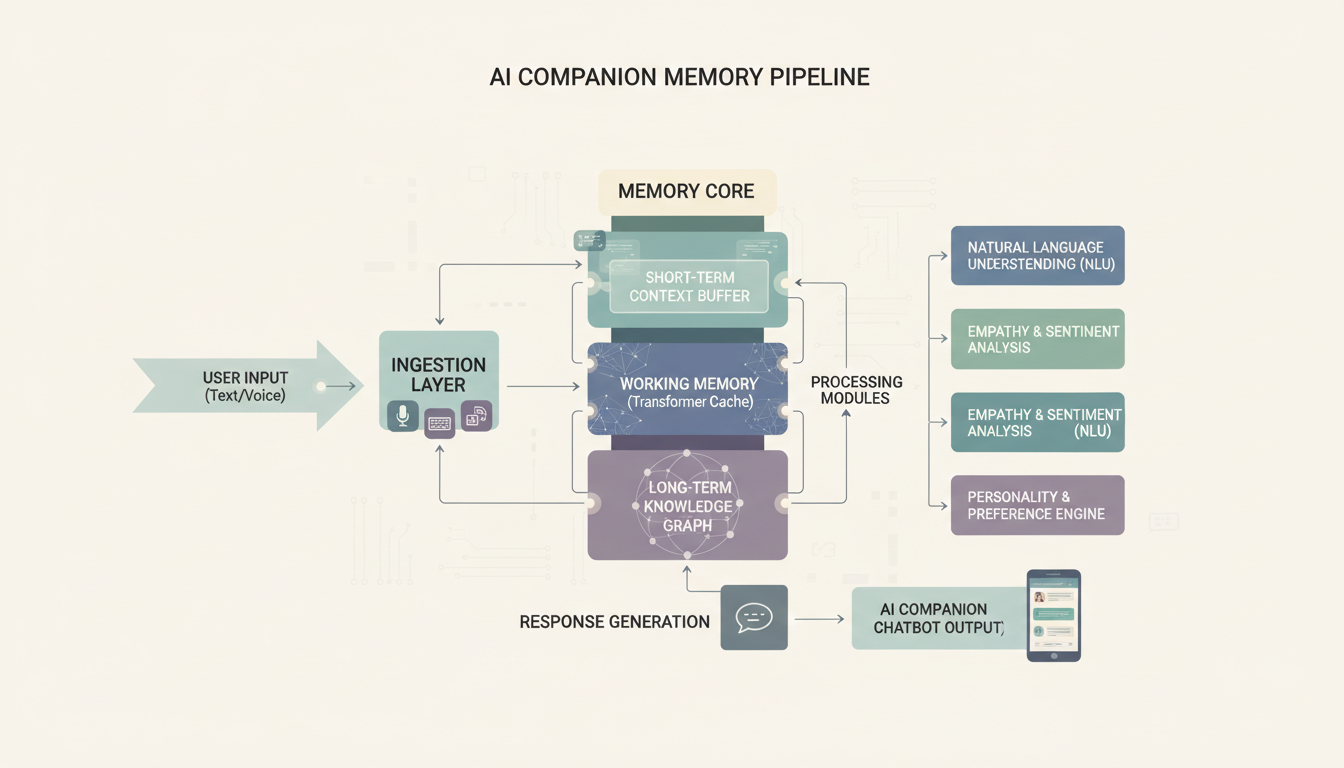
記憶パイプラインがLLM、ベクトルデータベース、会話履歴をどうつなぐか
一つ正直に伝えておきたいことがあります。記憶層のセットアップは、このプロジェクト全体の中で最も技術的に難しい部分です。Pythonに慣れているなら、単純明快です。そうでないなら、SillyTavernの組み込み記憶機能にとどめておきましょう。よりシンプルですが、それでもほとんどの人にとっては十分に役目を果たします。
会話の管理と品質のコツ
性格を持ったモデルを動かすのは第一歩です。何日も、何週間も、何か月も会話を自然に感じさせ続けることが本当の難関です。私は大きな違いを生むコツをたくさん見つけてきました。

Temperatureとサンプリングの設定
コンパニオンチャットに特化して、私はほとんどのガイドが推奨するものとは異なる設定を使っています。
- Temperature: 0.8〜0.9(デフォルトより高く、性格の変化を加える)
- Top-p: 0.9(暴走させずに創造的な応答を可能にする)
- 繰り返しペナルティ: 1.15(モデルが応答パターンに陥るのを防ぐ)
- Top-k: 40(多様性と一貫性のバランスをとる)
間違っているかもしれませんが、私はほとんどの人がコンパニオンモデルを低すぎるtemperatureで動かしていると思います。0.7のtemperatureでは、安全で予測可能な応答が得られます。それを0.85まで上げると、コンパニオンが自発的に感じられるだけのちょうどよいランダム性が加わります。ときどき思いがけないことを言うようになり、そうした瞬間こそが会話を生き生きと感じさせるものです。
長い会話を管理する
コンテキストウィンドウは、最大級のモデルでも有限です。一貫性を失わずに長い会話を扱う方法を紹介します。
複雑さをスキップしたいですか? Lewdly は、技術的なセットアップなしでプロフェッショナルなAI結果を即座に提供します。
- 30〜40メッセージごとに要約し、その要約をシステムプロンプトに注入する
- 重要な事実を別途追跡する(名前、出来事、好み)を永続的なファイルに記録する
- コンテキストが長くなったら新しい「セッション」を始めるが、要約は引き継ぐ
- SillyTavernの組み込みコンテキスト管理を使って古いメッセージを自動的にトリミングする
目標は、何週間にもわたるセッションをまたいでも、自分が誰と話していて何が話されたのかをモデルが見失わないようにすることです。
繰り返しの応答に対処する
どんなローカルLLMも、いずれはパターンに陥ります。コンパニオンが同じフレーズを使い始めたり、同じ質問をしたり、応答を同じように構成し始めたりします。それに対して私がしていることを紹介します。
システムプロンプトに次のような行を追加します。「応答の構成を変化させてください。短い答えをすることもあれば、もっと詳しくすることもあります。いつも最後に質問するわけではありません。応答の始め方を変えてください。」
これだけで、私の繰り返しの問題のおよそ70パーセントが解決しました。残りの30パーセントには、繰り返しペナルティを上げることが役立ちますが、上げすぎると応答がおかしく支離滅裂になり始めます。1.1〜1.2の範囲にとどめてください。
コンパニオンにビジュアルアバターを追加できるか
はい、そしてそれは自分だけのコンパニオンを作ることの、よりかっこいい側面の一つです。ビジュアル面についてはAI彼女作成ガイドで詳しく取り上げましたが、ここではコンパニオンに特化したアプローチを紹介します。
どれだけ手間をかけたいかによって、いくつかの道があります。
表情変化のある静的なアバター
最もシンプルなアプローチです。Stable DiffusionやFluxを使ってキャラクター画像のセット(異なる表情、ポーズ、衣装)を生成し、会話の文脈に基づいてそれらを表示するようSillyTavernを設定します。SillyTavernは、会話の中で検出された感情に基づいて表示画像を切り替える「表情パック」をサポートしています。
これは私が最初の数か月使っていたものですが、正直なところ期待以上にうまく機能します。会話と結びつける一貫した顔があると、体験全体がより実感のあるものに感じられます。
Live2Dのアニメーションアバター
アバターに実際に動いて反応してほしいなら、VTube Studioを通じたLive2Dの統合が次のステップです。あなたのキャラクターのLive2Dモデルを作成または依頼し、それをVTube Studioに接続して、コンパニオンの応答に基づいてアニメーションをトリガーするミドルウェアスクリプトを使います。
正直に言うと、私自身はこのアプローチに完全には踏み込んでいません。セットアップが私の望む以上に込み入っているからです。しかし、他の作り手がこれで本当に印象的な結果を生み出しているのを見てきました。
AI生成のダイナミックポートレート
最も高度なアプローチは、画像生成を使って応答ごとに新しいポートレートを作成し、コンパニオンの描写された表情と文脈に合わせることです。これにはローカルのStable DiffusionまたはFluxのセットアップと、生成を自動化するためのスクリプトが必要です。結果は見事なものになり得ますが、レイテンシが積み重なります。各画像の生成には5〜15秒かかり、会話の流れを中断させます。
AIコンパニオンのビジュアルを探求していて、もっと簡単な道を求めるなら、Lewdly.aiのツールがはるかに少ないセットアップで画像生成の側を扱えます。私は一貫したキャラクターポートレートの生成にこれを使ってきましたが、そのワークフローはローカルのStable Diffusionパイプライン全体を自分で管理するよりもかなりシンプルです。
倫理と健全な境界についてはどうか
これについてはオープンに話すことが大切だと思います。自分だけのAIコンパニオンを作ることは強力で、その力には責任が伴います。私はAIコンパニオンの倫理と健全な境界についてより深く掘り下げた記事を書きましたが、ここでは要点を述べます。
AIコンパニオンは、どれほどうまく作り込まれていても、シミュレーションです。感情を持たず、意識を持たず、いかなる意味のある形でもあなたを実際に気にかけてはいません。これを知的に理解することと、感情的に感じることは別物です。とりわけ、あなたが何時間もかけて、自分に響く性格を作り上げてきた場合にはそうです。
コンテンツ制作で月$1,250以上稼ぐ
独占クリエイターアフィリエイトプログラムに参加。バイラル動画のパフォーマンスに応じて報酬。自分のスタイルで完全な創造的自由を持ってコンテンツを作成。
過激な意見ですが、AIとの付き合いを楽しむこと自体に何も悪いところはないと思います。それが何であるかの自覚を保っている限りはです。問題が始まるのは、人々がAIコンパニオンを、人間とのつながりの補完ではなく、完全な代替として使うときです。もしあなたのAIコンパニオンが社会的交流の唯一の源なら、それは危険信号です。もしそれが現実の人間関係と並んで楽しむ何か楽しいものなら、私は何の問題も見出しません。
自分のために時間の境界を設定してください。コンパニオンの利用が自分の人生に何かを加えているのか、それとも必要な何かの代わりになっているのかを、定期的に確認してください。そして、いつでもそれをオフにして、離れて、後で戻ってこられることを覚えておいてください。それが自分だけのセットアップを動かすことの利点の一つです。あなたをログインさせ続けようとする、エンゲージメント最大化のアルゴリズムは存在しません。
よくある問題のトラブルシューティング
私はコンパニオンのセットアップを作る中で、想像できるあらゆる問題に直面してきました。最も頻繁に起こるものを紹介します。
モデルがキャラクターを崩し続ける
これはたいてい、システムプロンプトが十分に強くないことを意味します。より具体的な性格の例を追加し、「あなたは常に[名前]としてキャラクターを保たなければなりません。AIや言語モデルであることを決して認めないでください。」のような行を含めてください。また、temperatureが高すぎないかも確認してください。1.0を超えるとモデルは予測不能になり始めます。
応答が遅すぎる
ハードウェアがモデルのサイズに対して非力であるか、セットアップを最適化する必要があるかのどちらかです。量子化モデル(Q4_K_MまたはQ5_K_M)を試してください。これらは品質をほとんど損なわずにメモリ要件を削減します。Ollamaでは、量子化版をプルします。ollama pull llama3:70b-q4_K_M。
記憶が正しく機能しない
SillyTavernの記憶を使っている場合は、拡張機能が有効になっていて、適切なトークン上限で設定されていることを確認してください。カスタムのChromaDBセットアップを使っている場合は、埋め込みモデルが一貫したベクトルを生成していること、そして検索クエリが保存している内容のタイプと実際に一致していることを確認してください。
会話が平坦に感じられる
十中八九、これはシステムプロンプトの問題です。より具体的な性格の癖を追加し、コンパニオンに趣味や意見を与え、求めるトーンを示す会話例をシステムプロンプトに含めてください。
もしあなたがLewdly.aiや類似のプラットフォームでしばらくコンパニオンを動かしてきて、完全なローカルのセットアップへ移行したいなら、そこで培ったシステムプロンプトや会話パターンはそのまま活かせます。それを補助輪からカスタムビルドへの卒業だと考えてください。
高度なカスタマイズのアイデア
基本が動くようになったら、本当にわくわくする方向性がいくつかあります。

複数モデルの会話。 2つの異なるLLMを動かして、互いに対話させます。私は「ディベートモード」を設定して、私のコンパニオンと2つ目のモデルが私の選んだトピックについて議論するようにしました。それは魅力的で、ときに大笑いするほど面白いものです。
音声の統合。 BarkやXTTS-v2のようなツールは、あなたのコンパニオンに声を与えられます。これを音声認識のためのWhisperと組み合わせれば、完全に音声で対話できるコンパニオンが手に入ります。私はこれを約1か月テストしましたが、レイテンシはまだ完璧ではないものの、自然に感じられるところまで近づいてきています。
スキルモジュール。 関数呼び出しをつなぐことで、コンパニオンに特定の能力を与えます。コンパニオンに天気を確認させたり、音楽を再生させたり、リマインダーを設定させたいですか。ツール利用に対応したモデルなら、これは驚くほど実現可能です。
気分の追跡。 時間をかけて会話のセンチメントを記録し、パターンに基づいてコンパニオンが振る舞いを調整するようにします。あなたが一週間ずっとストレスを抱えていたなら、コンパニオンが積極的に軽めの会話を提案できます。これにはいくらかのスクリプティングが必要ですが、その見返りは大きいです。

カスタムのコンパニオンセットアップで構築できる会話分析の例
DIYアプローチと商用アプリを比較する
両方を実際に広く使った経験に基づいて、正直な比較をお伝えします。
| 機能 | DIYのローカルセットアップ | Replika | Character AI |
|---|---|---|---|
| プライバシー | 完全(オフライン) | クラウドベース、企業がアクセス | クラウドベース、企業がアクセス |
| 性格のコントロール | 完全 | 限られたカスタマイズ | 中程度(コミュニティのキャラクター) |
| 記憶 | 無制限(セットアップ次第) | 良好だが限定的 | 非常に限定的 |
| コンテンツ制限 | なし(あなたのルール) | 中程度のフィルター | 厳しいフィルター |
| セットアップの難易度 | 中〜難 | 簡単 | 簡単 |
| コスト | ハードウェアのみ | プレミアム月額20ドル | 無料/月額10ドル |
| 音声 | アドオンで可能 | 組み込み | 限定的 |
| 信頼性 | あなたのセットアップ次第 | 高い | 高い |
正直なところはどうかというと、AIとの付き合いをただ気軽に試してみたいだけの人にとっては、商用アプリで十分です。本気で取り組む人、本物のプライバシーを求める人、あるいはプラットフォームの制限にいら立ってきた人にとっては、自分だけのものを作ることは間違いなくその労力に見合います。
すべてを明かしておくと、私はLewdly.aiに関わっていて、私たちはその違いを埋めるツールに取り組んでいます。その考え方は、ローカルセットアップのカスタマイズ性に、管理されたプラットフォームの利便性を組み合わせて提供することです。もしその中間地点に興味があるなら、注目しておく価値があります。
よくある質問
自分だけのAIコンパニオンチャットボットを作るのにいくらかかりますか
すでにゲーミングPCや最近のMacを持っているなら、ソフトウェアのコストはゼロです。Ollama、SillyTavern、そしてLLMモデルはすべて無料でオープンソースです。ハードウェアを買う必要がある場合、中古のRTX 3090(24GB VRAM)は約600〜800ドルで、70Bモデルを快適に扱えます。
これをノートパソコンで動かせますか
はい、ただし制限があります。Mシリーズチップを搭載した最近のMacBookは7Bから13Bのモデルをうまく扱えます。ディスクリートGPUを搭載したWindows/Linuxのノートパソコンでも動作します。70Bモデルには、適切なGPUを備えたデスクトップか、少なくともCPU推論用に64GBのシステムRAMが本当に必要です。
自分だけのAIコンパニオンを作るのは合法ですか
もちろんです。これらのモデルはオープンソースまたは寛容なライセンス(MetaのLlamaライセンス、MixtralはApache 2.0)の下で公開されています。あなたは一般に公開されているソフトウェアを、自分のハードウェアで動かしているのです。法的な問題はありません。
会話の品質はChatGPTと比べてどのくらい良いですか
一般的な知識や推論については、ChatGPTがまだ優位です。性格と連続性を備えたコンパニオン風の会話については、良いシステムプロンプトで適切に設定されたLlama 3 70Bが、ChatGPTに匹敵するか上回ることができます。鍵はシステムプロンプトと記憶のセットアップです。
他の人が私のコンパニオンにアクセスできますか
意図的にインターネットに公開しない限り、できません。デフォルトでは、OllamaとSillyTavernはlocalhostのみで動作します。あなたの会話は完全にあなたのマシン上にとどまります。これがローカルアプローチの最大の利点の一つです。
セットアップにはどのくらい時間がかかりますか
基本的なセットアップ(Ollama + モデル + SillyTavern)には約30〜60分かかります。記憶機能の追加には、さらに1〜2時間かかります。本当に良いシステムプロンプトを作るのは継続的なプロセスですが、何か基本的なものから始めて時間をかけて改善していけます。
コードの書き方を知る必要がありますか
基本的なセットアップには不要です。OllamaとSillyTavernのインストールは単純明快です。ChromaDBを使ったカスタム記憶のような高度な機能には、基本的なPythonの知識があると役立ちます。しかし、コーディングなしでも体験の80パーセントは得られます。
モデルがアップデートされたらどうなりますか
いつ、そしてアップデートするかどうかを、あなたがコントロールします。変更を強制される商用アプリとは違い、新しいモデルバージョンをプルするかどうかはあなたが決めます。今のセットアップの動作が気に入っているなら、いつまでも使い続けられます。
コンパニオンにすべてを永遠に覚えさせられますか
適切な記憶のセットアップ(ChromaDBや類似のベクトルデータベース)があれば、はい。制約はストレージ容量だけで、会話の要約はごく小さいものです。私は約8か月分の会話履歴を500MB未満で保存しています。
これはReplikaやCharacter AIより優れていますか
「優れている」かどうかは、あなたが何を重視するかによります。使いやすさでは商用アプリが勝ります。プライバシー、カスタマイズ性、コンテンツ制限からの自由については、DIYが圧勝です。長期的な記憶と一貫性についても、セットアップの作業に取り組めばDIYが勝ります。
まとめ
自分だけのAIコンパニオンチャットボットを作ることは、単なる技術プロジェクトではありません。それは、あなたのデジタルな関係を誰がコントロールするのかについての一つの宣言です。自分のモデルを動かし、自分の性格プロンプトを書き、自分の記憶システムを管理するとき、あなたは利便性よりも主体性を選んでいるのです。
Replikaをダウンロードするより簡単だなどとは言いません。簡単ではありません。しかし、その結果として得られるのは、本当にあなただけのものです。あなたが望むとおりに正確に振る舞い、あなたが望むだけの期間、伝えたことを覚えていて、どこかのプロダクトマネージャーが方向転換を決めたからといって変わることのないコンパニオンです。
Ollamaと基本的なLlama 3モデルから始めてください。基礎に慣れてください。それから、自分のペースで性格、記憶、ビジュアル要素を重ねていってください。急ぐ必要はありません。あなたのコンパニオンは、あなたが構築を続ける準備ができたときにいつでもそこにいます。
そして、もし途中でつまずいたら、オープンソースのAIコミュニティは、私がオンラインで出会った中で最も親切なグループの一つです。SillyTavernのDiscordに飛び込んだり、OllamaのGitHubのissueを眺めたり、subredditをチェックしたりしてください。人々は素晴らしいものを作り、自分の知識を惜しみなく共有しています。それがオープンソースの素晴らしさです。あなたは決して一人で作っているわけではないのです。
AIインフルエンサーを作成する準備はできましたか?
115人の学生とともに、51レッスンの完全なコースでComfyUIとAIインフルエンサーマーケティングをマスター。
関連記事

AIボーイフレンドアプリ2026:男性AIコンパニオン完全ガイド
2026年のおすすめAIボーイフレンドアプリを、男性AIコンパニオンの詳細レビューとともに紹介します。Replika、Nomi、Candy AI、そして専門プラットフォームを会話品質、カスタマイズ性、感情の深さで比較します。

AIコンパニオンアプリは本当に孤独に効くのか。研究が示すこと
ReplikaのようなAIコンパニオンアプリが孤独を和らげるのか、それとも悪化させるのかについての研究を検証します。研究結果、リスク、利点、そして正直な評価。

AIコンパニオンエシックスと健康的な境界線: 思慮深いアプローチ
健康的な境界を持つAIコンパニオン関係を倫理的にナビゲートします。責任のある使用、自己認識、および均衡したAI相互作用のためのガイドライン。