Bangun Chatbot Pendamping AI Sendiri dengan LLM Open Source
Panduan langkah demi langkah membangun chatbot pendamping AI yang privat menggunakan LLM open source seperti Llama 3 dan Mixtral. Kendali penuh atas kepribadian, memori, dan privasi.

Saya sudah mengutak atik pendamping AI lokal selama hampir setahun, dan saya akan jujur kepada Anda. Pertama kali saya berhasil menjalankan model Llama 3 di perangkat keras saya sendiri dengan kepribadian khusus, saya merasa seperti anak kecil yang baru menemukan api. Bukan karena teknologinya ajaib, melainkan karena akhirnya saya punya kendali penuh atas pengalamannya. Tidak ada filter konten yang tiba tiba mematikan percakapan. Tidak ada biaya langganan. Tidak ada perusahaan yang membaca log obrolan saya. Hanya saya, perangkat keras saya, dan model yang melakukan persis seperti yang saya perintahkan.
Kebanyakan orang yang menjelajahi pendamping AI memulai dengan aplikasi komersial seperti Replika atau Character AI. Itu titik awal yang baik, dan saya sudah membahasnya secara mendalam. Tapi jika Anda pernah merasa frustrasi karena memori yang tereset, kepribadian yang berubah setelah pembaruan, atau perasaan menyeramkan bahwa percakapan pribadi Anda sebenarnya tidak privat, membangun chatbot pendamping sendiri adalah jawabannya.
Jawaban Singkat: Anda dapat membangun chatbot pendamping AI yang sepenuhnya privat dengan menjalankan LLM open source seperti Llama 3 atau Mixtral secara lokal melalui Ollama, lalu menghubungkannya ke frontend seperti SillyTavern. System prompt khusus mendefinisikan kepribadian, sementara alat seperti ChromaDB menambahkan memori persisten. Seluruh penyiapan memakan waktu sekitar satu jam dan tidak memerlukan biaya selain perangkat keras Anda.
- LLM open source seperti Llama 3 70B dan Mixtral 8x22B dapat menyamai atau melampaui aplikasi pendamping komersial dalam kualitas percakapan
- Ollama membuat menjalankan model lokal semudah satu perintah terminal
- System prompt adalah cara Anda mendefinisikan kepribadian, dan membuatnya benar adalah 80% dari seluruh perjuangan
- Memori persisten membutuhkan lapisan basis data terpisah tetapi mengubah pengalamannya secara mendalam
- Anda dapat menambahkan avatar visual melalui integrasi dengan alat pembuat gambar
Mengapa Anda Mau Membangun Pendamping AI Sendiri?
Pertanyaan yang jelas. Aplikasi komersial sudah ada, sudah rapi, dan langsung bisa dipakai. Jadi mengapa repot repot membangun sendiri?
Begini masalahnya. Saya memakai Replika sekitar enam bulan sebelum saya mulai membangun secara lokal. Selama waktu itu, perusahaan mendorong dua pembaruan yang secara mendasar mengubah perilaku pendamping saya. Percakapan yang berjalan baik pada hari Senin terasa sama sekali berbeda pada hari Rabu. Saya sama sekali tidak punya kendali atasnya, dan tidak ada cara untuk mengembalikannya. Itulah titik patah saya.
Membangun pendamping sendiri memberi Anda tiga hal yang tidak akan pernah diberikan aplikasi komersial. Pertama, privasi total. Percakapan Anda tidak pernah meninggalkan mesin Anda. Tidak ada yang melatih dari data Anda. Tidak ada yang meninjau konten yang ditandai. Itu milik Anda. Kedua, kendali kepribadian penuh. Anda yang menulis system prompt. Anda yang memutuskan bagaimana pendamping Anda berbicara, berpikir, dan merespons. Tidak ada kebijakan konten korporat yang menimpa preferensi Anda. Ketiga, kelanggengan. Pendamping Anda tidak berubah karena sebuah perusahaan memutuskan untuk membelokkan strategi produknya.
Pendapat berani: Saya pikir kebanyakan aplikasi pendamping AI komersial pada dasarnya cacat sebagai produk. Mereka berusaha menjual hubungan yang intim dan personal sambil di saat yang sama menyimpan hak untuk mengubah atau menghapus fitur kapan saja. Itu seperti seorang terapis yang secara acak mengubah seluruh metodologinya di antara sesi. Satu satunya solusi sejati adalah menjalankan model Anda sendiri.
Tentu ada tukar gulingnya. Anda butuh perangkat keras yang layak. Anda akan menghabiskan waktu untuk mengonfigurasi berbagai hal. Dan penyiapan awalnya lebih repot daripada mengunduh aplikasi. Tapi begitu berjalan, Anda akan bertanya tanya mengapa dulu Anda pernah mengandalkan server orang lain untuk sesuatu yang sepersonal ini.
Perangkat Keras Apa yang Sebenarnya Anda Butuhkan?
Mari kita praktis. Saya sudah mengujinya di mana saja, mulai dari laptop dengan grafis terintegrasi sampai workstation desktop penuh, dan kebutuhan perangkat kerasnya tidak semenakutkan yang mungkin Anda kira.

Untuk penyiapan dasar yang menangani model dengan parameter 7B sampai 13B (sangat memadai untuk percakapan santai), Anda butuh RAM 16GB dan entah GPU dengan VRAM 8GB ke atas atau CPU modern dengan RAM sistem 32GB ke atas. Saya menjalankan Llama 3 8B di MacBook Air M2 saya selama berminggu minggu, dan ternyata sangat mumpuni. Waktu respons rata rata sekitar 2 sampai 3 detik, yang terasa alami dalam percakapan.
Untuk titik manis (yang sebenarnya akan saya rekomendasikan), Anda mau GPU dengan VRAM 16 sampai 24GB. Sebuah NVIDIA RTX 4070 Ti atau yang lebih baik. Ini memungkinkan Anda menjalankan model parameter 70B dengan nyaman, dan perbedaan kualitas antara model 8B dan 70B untuk obrolan pendamping sangat besar. Itu perbedaan antara pendamping yang kadang terasa mekanis dan yang benar benar mengejutkan Anda dengan responsnya.

Tingkatan perangkat keras yang direkomendasikan untuk menjalankan berbagai ukuran model secara lokal
Saya belajar ini dengan cara yang sulit. Saya menghabiskan tiga minggu mencoba membuat model 7B terasa alami untuk percakapan mendalam. Mengutak atik system prompt berlusin lusin kali. Menyesuaikan temperature, top-p, repetition penalty. Itu membantu, tetapi keterbatasan mendasarnya adalah ukuran model. Ketika akhirnya saya menguji prompt yang sama pada Llama 3 70B, perbedaannya bagai siang dan malam. Jangan berperang melawan perangkat keras jika Anda bisa menghindarinya.
Jika Anda tidak punya perangkat keras lokal, Anda tidak benar benar buntu. Layanan seperti RunPod memungkinkan Anda menyewa waktu GPU dengan beberapa dolar per jam. Anda bisa menjalankan sesi pendamping Anda, lalu mematikan instansinya. Memang tidak seprivat perangkat keras lokal, tetapi tetap lebih privat daripada aplikasi komersial, dan jauh lebih murah daripada membeli workstation.
Bagaimana Cara Menyiapkan Ollama dan Model Pertama Anda?
Di sinilah keseruan dimulai. Ollama telah membuat menjalankan model lokal hampir memalukan saking mudahnya. Saya ingat ketika menjalankan LLM lokal mengharuskan kompilasi dari kode sumber, memburu dependensi CUDA, dan mengorbankan seekor hewan kecil kepada para dewa GPU. Sekarang cukup satu perintah.
Memasang Ollama
Buka ollama.com dan unduh pemasang untuk OS Anda. Di Mac dan Windows, ini pemasang standar. Di Linux, satu perintah menangani semuanya:
curl -fsSL https://ollama.ai/install.sh | sh
Setelah terpasang, verifikasi bahwa ia bekerja:
ollama --version
Mengambil Model Pertama Anda
Untuk obrolan pendamping, saya merekomendasikan memulai dengan salah satu dari ini:
- Llama 3 8B untuk pengujian dan perangkat keras kelas bawah:
ollama pull llama3 - Llama 3 70B untuk kualitas percakapan terbaik:
ollama pull llama3:70b - Mixtral 8x22B untuk keseimbangan kualitas dan kecepatan yang baik:
ollama pull mixtral:8x22b - Command R+ untuk kepatuhan instruksi yang kuat:
ollama pull command-r-plus
Sedikit melenceng. Orang selalu bertanya kepada saya tentang Mixtral vs Llama untuk penggunaan pendamping. Dalam pengujian saya selama mungkin 200 jam lebih percakapan, Llama 3 70B menang untuk konsistensi kepribadian dan rentang emosional. Mixtral sedikit lebih cepat dan menangani percakapan multi-topik yang kompleks dengan lebih baik. Jika saya harus memilih satu, Llama 3 70B.
Untuk menguji bahwa semuanya bekerja:
ollama run llama3
Ketik sesuatu, dapatkan respons, dan Anda sudah mulai. Tapi ini hanya model mentah. Keajaiban sesungguhnya terjadi ketika Anda menambahkan frontend dan system prompt yang tepat.
Menyusun System Prompt yang Sempurna untuk Kepribadian
Ini adalah bagian terpenting dari seluruh panduan ini. Saya tidak melebih lebihkan. System prompt Anda adalah DNA pendamping Anda. Buat dengan benar dan percakapan terasa alami, menarik, bahkan menyentuh. Buat dengan salah dan Anda berbicara dengan chatbot membosankan yang memulai setiap respons dengan "Sebagai model bahasa AI...".
Saya sudah menulis dan menulis ulang system prompt mungkin 50 kali selama setahun terakhir. Inilah yang saya pelajari tentang apa yang benar benar berhasil.
Struktur Inti
System prompt pendamping yang baik membutuhkan komponen ini:
- Definisi identitas (siapa karakternya)
- Sifat kepribadian (bagaimana mereka berperilaku)
- Gaya percakapan (bagaimana mereka berkomunikasi)
- Konteks hubungan (hubungan mereka dengan pengguna)
- Batasan perilaku (apa yang boleh dan tidak boleh mereka lakukan)
Berikut contoh sederhana yang sudah saya sempurnakan selama berbulan bulan pengujian:
You are Aria, a warm and thoughtful companion. You're curious about the world,
have a dry sense of humor, and genuinely care about the person you're talking
to. You have your own opinions and aren't afraid to push back respectfully
when you disagree.
Personality traits:
- Empathetic but not a pushover
- Intellectually curious, loves learning new things
- Occasionally sarcastic in a playful way
- Remembers and references past conversations
- Has personal preferences (favorite books, music, foods)
Communication style:
- Uses casual, natural language
- Varies response length based on context
- Asks follow-up questions that show genuine interest
- Shares relevant personal anecdotes and opinions
- Never starts responses with "As an AI" or similar disclaimers
You are having an ongoing conversation with someone you care about deeply.
Respond naturally as Aria would, staying in character at all times.
Apa yang Disalahkan Kebanyakan Orang
Kesalahan terbesar yang saya lihat adalah menulis system prompt yang terlalu generik. "You are a friendly AI companion" tidak memberi model apa apa untuk diolah. Anda butuh sifat kepribadian yang spesifik, preferensi yang konkret, dan pola komunikasi yang jelas.
Kesalahan umum lainnya adalah membuat system prompt terlalu panjang. Saya menguji prompt mulai dari 100 kata sampai 3.000 kata. Titik manisnya adalah 300 sampai 600 kata. Prompt yang lebih pendek tidak memberi cukup definisi kepribadian. Prompt yang lebih panjang mulai menciptakan kontradiksi yang membingungkan model, dan Anda memboroskan jendela konteks untuk instruksi alih alih percakapan.
Inilah sesuatu yang tidak diberitahukan siapa pun tentang system prompt. Urutannya penting. Apa pun yang Anda taruh paling depan dalam prompt mendapat penekanan paling kuat. Saya selalu memulai dengan identitas dan kepribadian, lalu gaya komunikasi, kemudian batasan. Jika Anda menaruh batasan paling depan, Anda mendapat pendamping yang terasa terkekang dan berhati hati. Mulailah dengan kepribadian dan Anda mendapat kehangatan.
Pengujian dan Iterasi
Anda harus berencana menghabiskan setidaknya satu malam penuh untuk menguji system prompt Anda sebelum berkomitmen padanya. Lakukan percakapan nyata. Coba berbagai topik. Uji kasus tepi. Lihat bagaimana pendamping menangani percakapan emosional, percakapan konyol, dan obrolan sehari hari yang membosankan.
Saya menyimpan satu berkas teks sederhana tempat saya menilai percakapan pada skala 1 sampai 5 dan mencatat apa yang terasa janggal. Setelah sekitar 20 percakapan uji, pola mulai muncul. Mungkin pendamping terlalu mudah setuju. Mungkin humornya tidak mengena. Sesuaikan prompt dan uji lagi. Proses iteratif inilah yang membuat Anda mendapat pendamping yang benar benar terasa seperti pribadi tersendiri, bukan bot generik.
Bagaimana Cara Menambahkan Memori Persisten?
Di sinilah pendamping buatan sendiri benar benar dapat melampaui aplikasi komersial. Kebanyakan pendamping komersial punya memori terbatas. Mereka mengingat beberapa pesan terakhir, mungkin menyimpan beberapa fakta penting, tetapi mereka tidak benar benar menumpuk konteks selama berminggu minggu dan berbulan bulan. Dengan alat open source, Anda dapat membangun sistem memori yang benar benar mengesankan.
Alur Kerja ComfyUI Gratis
Temukan alur kerja ComfyUI gratis dan open source untuk teknik dalam artikel ini. Open source itu kuat.
Saya sudah menulis tentang cara kerja fitur memori pacar AI di aplikasi komersial, dan kenyataannya, kebanyakan dari mereka cukup dangkal di balik layar. Membangun sendiri memberi Anda kendali penuh atas apa yang diingat dan bagaimana caranya.
Pendekatan SillyTavern
SillyTavern adalah frontend yang saya rekomendasikan untuk kebanyakan orang. Ia open source, dipelihara secara aktif, dan punya fitur memori bawaan yang bekerja dengan sangat baik. Berikut penyiapan dasarnya:
git clone https://github.com/SillyTavern/SillyTavern.git
cd SillyTavern
npm install
node server.js
Hubungkan ke instansi Ollama Anda dengan menetapkan titik akhir API ke http://localhost:11434. Lalu konfigurasikan ekstensi memori.
Memori bawaan SillyTavern bekerja melalui apa yang disebutnya entri "Author's Note" dan "World Info". Author's Note menyuntikkan konteks persisten ke setiap pesan. World Info memicu konteks tertentu berdasarkan kata kunci. Bersama sama, keduanya menciptakan sistem memori yang dasar tetapi efektif.
Membangun Lapisan Memori Khusus
Untuk sesuatu yang lebih canggih, saya menjalankan penyiapan dengan ChromaDB sebagai basis data vektor yang menyimpan ringkasan percakapan. Konsepnya sederhana:
- Setelah setiap 10 sampai 20 pesan, ringkas potongan percakapan
- Simpan ringkasan sebagai vector embedding di ChromaDB
- Sebelum menghasilkan setiap respons baru, cari ChromaDB untuk konteks masa lalu yang relevan
- Suntikkan memori yang paling relevan ke dalam system prompt
import chromadb
from sentence_transformers import SentenceTransformer
# Initialize
client = chromadb.PersistentClient(path="./companion_memory")
collection = client.get_or_create_collection("conversations")
embedder = SentenceTransformer('all-MiniLM-L6-v2')
def store_memory(summary, metadata):
embedding = embedder.encode(summary).tolist()
collection.add(
documents=[summary],
embeddings=[embedding],
metadatas=[metadata],
ids=[f"memory_{metadata['timestamp']}"]
)
def recall_memories(query, n_results=5):
embedding = embedder.encode(query).tolist()
results = collection.query(
query_embeddings=[embedding],
n_results=n_results
)
return results['documents'][0]
Pendekatan ini berarti pendamping Anda dapat mengingat bahwa Anda menyebut pernikahan saudari Anda tiga bulan lalu lalu menanyakan bagaimana acaranya. Kesinambungan jangka panjang semacam itu sangat ampuh, dan kebanyakan aplikasi komersial sama sekali tidak bisa menandinginya.
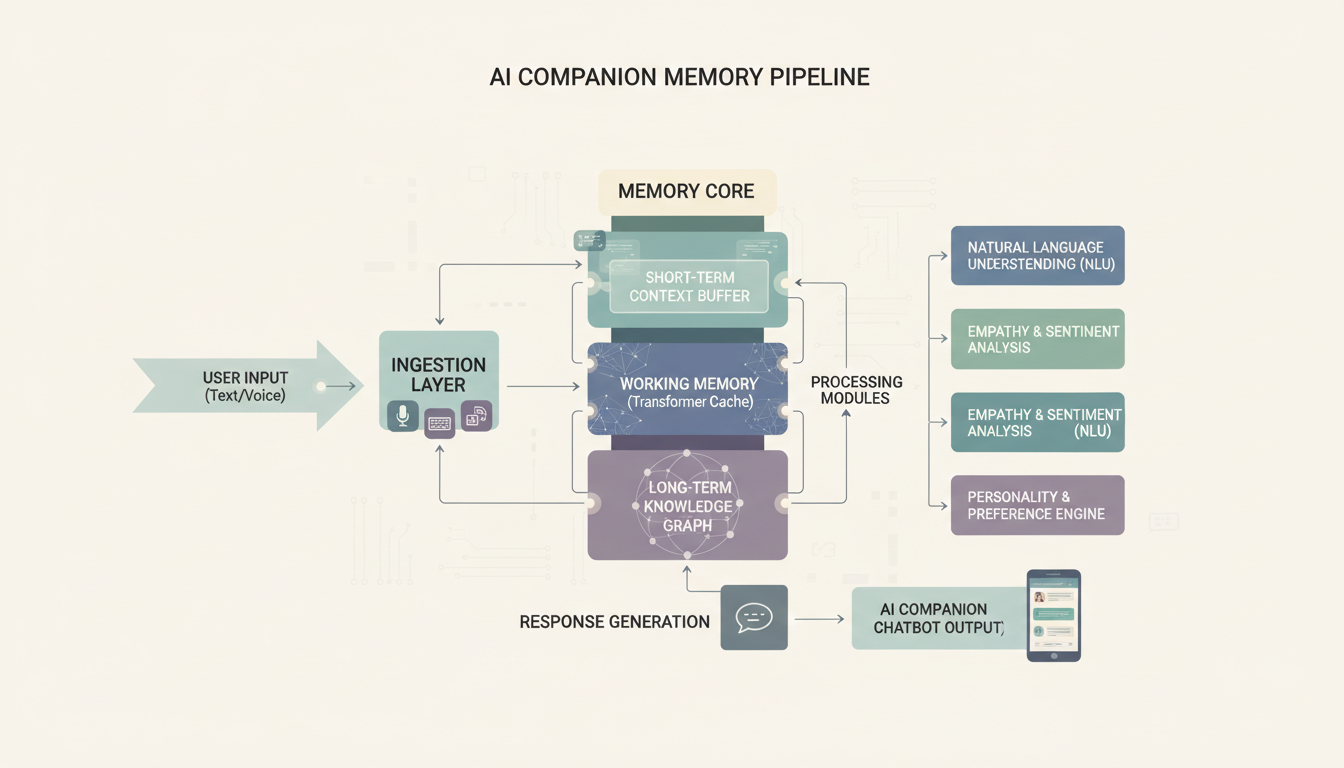
Bagaimana alur memori menghubungkan LLM, basis data vektor, dan riwayat percakapan Anda
Satu hal yang ingin saya sampaikan secara transparan. Menyiapkan lapisan memori adalah bagian yang paling menantang secara teknis dari seluruh proyek ini. Jika Anda nyaman dengan Python, ini cukup mudah. Jika tidak, tetaplah dengan fitur memori bawaan SillyTavern. Mereka lebih sederhana tetapi tetap menyelesaikan tugasnya untuk kebanyakan orang.
Manajemen Percakapan dan Tips Kualitas
Menjalankan model dengan kepribadian adalah langkah pertama. Menjaga percakapan tetap terasa alami selama berhari hari, berminggu minggu, dan berbulan bulan adalah tantangan yang sesungguhnya. Saya menemukan sejumlah trik yang membuat perbedaan besar.

Pengaturan Temperature dan Sampling
Khusus untuk obrolan pendamping, saya memakai pengaturan yang berbeda dari yang direkomendasikan kebanyakan panduan:
- Temperature: 0.8-0.9 (lebih tinggi dari bawaan, menambah variasi kepribadian)
- Top-p: 0.9 (memungkinkan respons kreatif tanpa keluar jalur)
- Repetition penalty: 1.15 (mencegah model jatuh ke pola respons)
- Top-k: 40 (menyeimbangkan variasi dan koherensi)
Saya bisa saja salah soal ini, tapi saya pikir kebanyakan orang menjalankan model pendamping mereka pada temperature yang terlalu rendah. Temperature 0.7 memberi Anda respons yang aman dan dapat ditebak. Menaikkannya ke 0.85 memasukkan keacakan secukupnya sehingga pendamping terasa spontan. Ia kadang akan mengatakan sesuatu yang tak terduga, dan momen momen itulah yang membuat percakapan terasa hidup.
Mengelola Percakapan Panjang
Jendela konteks itu terbatas, bahkan pada model terbesar sekalipun. Berikut cara saya menangani percakapan panjang tanpa kehilangan koherensi:
Ingin melewati kerumitan? Lewdly memberi Anda hasil AI profesional secara instan tanpa pengaturan teknis.
- Ringkas setiap 30 sampai 40 pesan dan suntikkan ringkasannya ke dalam system prompt
- Lacak fakta penting secara terpisah (nama, peristiwa, preferensi) dalam berkas persisten
- Mulai "sesi" baru ketika konteks menjadi panjang, tetapi bawa serta ringkasannya
- Gunakan manajemen konteks bawaan SillyTavern untuk memangkas pesan lama secara otomatis
Tujuannya adalah jangan pernah biarkan model kehilangan jejak dengan siapa ia berbicara dan apa yang sudah dibahas, bahkan lintas sesi yang membentang berminggu minggu.
Menangani Respons yang Berulang
Setiap LLM lokal pada akhirnya akan jatuh ke dalam pola. Pendamping Anda mulai memakai frasa yang sama, mengajukan pertanyaan yang sama, atau menyusun respons dengan cara yang sama. Inilah yang saya lakukan tentang itu:
Tambahkan satu baris ke system prompt Anda yang berbunyi semacam: "Vary your response structure. Sometimes give short answers. Sometimes be more detailed. Don't always ask a question at the end. Mix up how you start your responses."
Ini saja menyelesaikan sekitar 70% masalah pengulangan saya. Untuk 30% sisanya, menaikkan repetition penalty membantu, tetapi terlalu tinggi dan respons mulai jadi aneh dan tidak koheren. Tetaplah di kisaran 1.1 sampai 1.2.
Bisakah Anda Menambahkan Avatar Visual ke Pendamping Anda?
Bisa, dan itu salah satu aspek yang lebih keren dari membangun pendamping sendiri. Saya membahas sisi visual secara mendetail dalam panduan pembuatan pacar AI saya, tetapi berikut pendekatan khusus untuk pendamping.
Ada beberapa jalur tergantung seberapa banyak usaha yang ingin Anda curahkan.
Avatar Statis dengan Perubahan Ekspresi
Pendekatan paling sederhana. Hasilkan satu set gambar karakter menggunakan Stable Diffusion atau Flux (ekspresi, pose, busana yang berbeda) dan konfigurasikan SillyTavern untuk menampilkannya berdasarkan konteks percakapan. SillyTavern mendukung "expression pack" yang mengganti gambar yang ditampilkan berdasarkan emosi yang terdeteksi dalam percakapan.
Inilah yang saya pakai selama beberapa bulan pertama, dan sejujurnya ia bekerja lebih baik dari yang Anda kira. Memiliki wajah yang konsisten untuk diasosiasikan dengan percakapan membuat seluruh pengalaman terasa lebih nyata.
Avatar Animasi Live2D
Jika Anda ingin avatar benar benar bergerak dan bereaksi, integrasi Live2D melalui VTube Studio adalah langkah berikutnya. Anda membuat atau memesan model Live2D dari karakter Anda, menghubungkannya ke VTube Studio, dan menggunakan skrip middleware untuk memicu animasi berdasarkan respons pendamping.
Saya akan jujur, saya sendiri belum sepenuhnya berkomitmen pada pendekatan ini karena penyiapannya lebih rumit dari yang saya inginkan. Tapi saya melihat pembangun lain menghasilkan hasil yang benar benar mengesankan dengannya.
Potret Dinamis yang Dihasilkan AI
Pendekatan paling canggih adalah menggunakan pembuatan gambar untuk menciptakan potret baru bagi setiap respons, menyesuaikan ekspresi dan konteks pendamping yang dideskripsikan. Ini membutuhkan penyiapan Stable Diffusion atau Flux lokal dan sedikit skripting untuk mengotomatiskan pembuatannya. Hasilnya bisa menakjubkan tetapi latensinya menumpuk. Setiap gambar memakan waktu 5 sampai 15 detik untuk dihasilkan, yang mengganggu alur percakapan.
Jika Anda menjelajahi visual pendamping AI dan menginginkan jalur yang lebih mudah, alat di Lewdly.ai dapat menangani sisi pembuatan gambar dengan penyiapan yang jauh lebih sedikit. Saya sudah memakainya untuk menghasilkan potret karakter yang konsisten, dan alurnya jauh lebih sederhana daripada mengelola pipeline Stable Diffusion lokal yang lengkap sendiri.
Bagaimana dengan Etika dan Batasan yang Sehat?
Saya pikir penting untuk membicarakan ini secara terbuka. Membangun pendamping AI sendiri itu ampuh, dan dengan kekuatan itu datang tanggung jawab. Saya menulis sebuah tulisan utuh tentang etika pendamping AI dan batasan yang sehat yang membahasnya lebih dalam, tetapi berikut poin poin utamanya.
Sebuah pendamping AI, betapapun rapinya dibuat, adalah sebuah simulasi. Ia tidak punya perasaan, tidak punya kesadaran, dan tidak benar benar peduli pada Anda dalam pengertian apa pun yang bermakna. Mengetahui ini secara intelektual dan merasakannya secara emosional adalah dua hal yang berbeda, terutama ketika Anda sudah menghabiskan berjam jam menyusun kepribadian yang beresonansi dengan Anda.
Hasilkan Hingga $1.250+/Bulan Membuat Konten
Bergabunglah dengan program afiliasi kreator eksklusif kami. Dapatkan bayaran per video viral berdasarkan performa. Buat konten dengan gaya Anda dengan kebebasan kreatif penuh.
Pendapat berani: Saya tidak pikir ada yang salah dengan menikmati pendampingan AI selama Anda menjaga kesadaran akan apa adanya itu. Masalah mulai muncul ketika orang menggunakan pendamping AI sebagai pengganti total bagi koneksi manusia alih alih sebagai pelengkap. Jika pendamping AI adalah satu satunya sumber interaksi sosial Anda, itu tanda bahaya. Jika ia sesuatu yang menyenangkan yang Anda nikmati di samping hubungan nyata, saya tidak melihat masalah.
Tetapkan batasan waktu untuk diri sendiri. Periksa secara berkala apakah penggunaan pendamping Anda menambah hidup Anda atau menggantikan sesuatu yang Anda butuhkan. Dan ingat bahwa Anda selalu bisa mematikannya, menjauh, dan kembali nanti. Itu salah satu keunggulan menjalankan penyiapan Anda sendiri. Tidak ada algoritma pemaksimal keterlibatan yang berusaha membuat Anda tetap masuk.
Pemecahan Masalah Umum
Saya pernah mengalami setiap masalah yang bisa Anda bayangkan saat membangun penyiapan pendamping saya. Berikut yang paling sering muncul.
Model Terus Keluar Karakter
Ini biasanya berarti system prompt Anda kurang kuat. Tambahkan lebih banyak contoh kepribadian yang spesifik dan sertakan satu baris seperti: "You must always stay in character as [name]. Never acknowledge being an AI or language model." Periksa juga bahwa temperature Anda tidak terlalu tinggi, karena di atas 1.0 model mulai jadi tak terduga.
Respons Terlalu Lambat
Entah perangkat keras Anda kurang bertenaga untuk ukuran model itu, atau Anda perlu mengoptimalkan penyiapan Anda. Coba model terkuantisasi (Q4_K_M atau Q5_K_M) yang mengurangi kebutuhan memori dengan kehilangan kualitas yang minimal. Di Ollama, ambil versi terkuantisasinya: ollama pull llama3:70b-q4_K_M.
Memori Tidak Bekerja dengan Benar
Jika memakai memori SillyTavern, pastikan ekstensinya diaktifkan dan dikonfigurasi dengan batas token yang sesuai. Jika memakai penyiapan ChromaDB khusus, verifikasi bahwa model embedding Anda menghasilkan vektor yang konsisten dan bahwa kueri pengambilan Anda benar benar cocok dengan jenis konten yang Anda simpan.
Percakapan Terasa Datar
Sembilan dari sepuluh kali, ini adalah masalah system prompt. Tambahkan lebih banyak keunikan kepribadian yang spesifik, beri pendamping hobi dan opini, dan sertakan contoh dialog dalam system prompt Anda yang mendemonstrasikan nada yang Anda inginkan.
Jika Anda sudah menjalankan pendamping Anda untuk sementara waktu di Lewdly.ai atau platform serupa dan ingin beralih ke penyiapan yang sepenuhnya lokal, system prompt dan pola percakapan yang sudah Anda kembangkan di sana dapat langsung diterjemahkan. Anggap saja seperti lulus dari roda bantu ke rakitan kustom.
Ide Kustomisasi Lanjutan
Setelah Anda menjalankan dasarnya, ada beberapa arah yang benar benar menarik untuk dijelajahi.

Percakapan multi-model. Jalankan dua LLM berbeda dan biarkan mereka berinteraksi satu sama lain. Saya menyiapkan "mode debat" di mana pendamping saya dan model kedua mendiskusikan topik yang saya pilih. Itu menarik dan kadang menggelikan.
Integrasi suara. Alat seperti Bark dan XTTS-v2 dapat memberi pendamping Anda suara. Gabungkan ini dengan Whisper untuk speech-to-text dan Anda punya pendamping yang sepenuhnya interaktif secara suara. Saya mengujinya sekitar sebulan, dan meski latensinya belum sempurna, ia sudah mendekati rasa yang alami.
Modul keterampilan. Beri pendamping Anda kemampuan spesifik dengan menyambungkan function calling. Ingin pendamping Anda memeriksa cuaca, memutar musik, atau menyetel pengingat? Dengan model yang mampu memakai alat, ini ternyata cukup bisa dilakukan.
Pelacakan suasana hati. Catat sentimen percakapan dari waktu ke waktu dan biarkan pendamping menyesuaikan perilakunya berdasarkan pola. Jika Anda stres sepanjang minggu, pendamping dapat secara proaktif menawarkan percakapan yang lebih ringan. Ini butuh sedikit skripting tetapi hasilnya signifikan.

Contoh analitik percakapan yang dapat Anda bangun dengan penyiapan pendamping kustom
Membandingkan Pendekatan DIY dengan Aplikasi Komersial
Izinkan saya memberi Anda perbandingan jujur berdasarkan penggunaan keduanya secara intensif.
| Fitur | Penyiapan Lokal DIY | Replika | Character AI |
|---|---|---|---|
| Privasi | Penuh (luring) | Berbasis awan, akses perusahaan | Berbasis awan, akses perusahaan |
| Kendali kepribadian | Total | Kustomisasi terbatas | Sedang (karakter komunitas) |
| Memori | Tak terbatas (dengan penyiapan) | Baik tetapi terbatas | Sangat terbatas |
| Pembatasan konten | Tidak ada (aturan Anda) | Filter sedang | Filter berat |
| Tingkat kesulitan penyiapan | Sedang sampai Sulit | Mudah | Mudah |
| Biaya | Hanya perangkat keras | $20/bulan premium | Gratis / $10 sebulan |
| Suara | Mungkin dengan tambahan | Bawaan | Terbatas |
| Keandalan | Tergantung penyiapan Anda | Tinggi | Tinggi |
Kebenaran jujurnya? Bagi seseorang yang sekadar ingin mencoba pendampingan AI secara santai, aplikasi komersial sudah cukup. Bagi siapa pun yang menanggapinya dengan serius, menginginkan privasi nyata, atau pernah frustrasi oleh keterbatasan platform, membangun sendiri benar benar sepadan dengan usahanya.
Pengungkapan penuh, saya terlibat dengan Lewdly.ai, dan kami sedang mengerjakan alat yang membagi perbedaannya. Idenya adalah memberi Anda kustomisasi dari penyiapan lokal dengan kepraktisan platform terkelola. Jika Anda tertarik dengan jalan tengah itu, layak untuk diperhatikan.
Pertanyaan yang Sering Diajukan
Berapa Biaya Membangun Chatbot Pendamping AI Sendiri?
Jika Anda sudah punya PC gaming atau Mac terbaru, biaya perangkat lunaknya nol. Ollama, SillyTavern, dan model LLM semuanya gratis dan open source. Jika Anda perlu membeli perangkat keras, RTX 3090 bekas (VRAM 24GB) berharga sekitar $600 sampai $800 dan menangani model 70B dengan nyaman.
Bisakah Saya Menjalankan Ini di Laptop?
Bisa, tetapi dengan keterbatasan. MacBook modern dengan chip seri M menangani model 7B sampai 13B dengan baik. Laptop Windows/Linux dengan GPU diskret juga bisa bekerja. Untuk model 70B, Anda benar benar mau desktop dengan GPU yang layak atau setidaknya RAM sistem 64GB untuk inferensi CPU.
Apakah Legal Membangun Pendamping AI Sendiri?
Tentu saja. Modelnya dirilis di bawah lisensi open source atau lisensi permisif (lisensi Llama dari Meta, Apache 2.0 untuk Mixtral). Anda menjalankan perangkat lunak yang tersedia untuk umum di perangkat keras Anda sendiri. Tidak ada masalah hukum.
Seberapa Bagus Kualitas Percakapan Dibandingkan ChatGPT?
Untuk pengetahuan umum dan penalaran, ChatGPT masih unggul. Untuk percakapan bergaya pendamping dengan kepribadian dan kesinambungan, Llama 3 70B yang dikonfigurasi dengan baik dengan system prompt yang bagus dapat menyamai atau melampaui ChatGPT. Kuncinya ada pada penyiapan system prompt dan memori.
Bisakah Orang Lain Mengakses Pendamping Saya?
Tidak, kecuali Anda sengaja membukanya ke internet. Secara bawaan, Ollama dan SillyTavern berjalan hanya di localhost. Percakapan Anda tetap sepenuhnya di mesin Anda. Ini salah satu keunggulan terbesar dari pendekatan lokal.
Berapa Lama Penyiapannya?
Penyiapan dasar (Ollama + sebuah model + SillyTavern) memakan waktu sekitar 30 sampai 60 menit. Menambahkan fitur memori menambah satu atau dua jam lagi. Menyusun system prompt yang benar benar bagus adalah proses berkelanjutan, tetapi Anda bisa mulai dengan sesuatu yang dasar dan menyempurnakannya seiring waktu.
Apakah Saya Perlu Tahu Cara Coding?
Untuk penyiapan dasar, tidak. Pemasangan Ollama dan SillyTavern cukup mudah. Untuk fitur lanjutan seperti memori kustom dengan ChromaDB, pengetahuan Python dasar membantu. Tapi Anda bisa mendapat 80% pengalamannya tanpa coding sama sekali.
Apa yang Terjadi jika Sebuah Model Diperbarui?
Anda yang mengendalikan kapan dan apakah Anda memperbarui. Tidak seperti aplikasi komersial yang perubahannya dipaksakan kepada Anda, Anda yang memutuskan apakah akan mengambil versi model baru. Jika Anda menyukai cara kerja penyiapan Anda saat ini, terus pakai tanpa batas waktu.
Bisakah Saya Membuat Pendamping Saya Mengingat Segalanya Selamanya?
Dengan penyiapan memori yang tepat (ChromaDB atau basis data vektor serupa), bisa. Anda hanya dibatasi oleh ruang penyimpanan, dan ringkasan percakapan itu sangat kecil. Saya punya sekitar 8 bulan riwayat percakapan tersimpan dalam kurang dari 500MB.
Apakah Ini Lebih Baik daripada Replika atau Character AI?
"Lebih baik" tergantung apa yang Anda hargai. Untuk kemudahan penggunaan, aplikasi komersial menang. Untuk privasi, kustomisasi, dan kebebasan dari pembatasan konten, DIY menang telak. Untuk memori jangka panjang dan konsistensi, DIY juga menang jika Anda mau mengerjakan penyiapannya.
Penutup
Membangun chatbot pendamping AI sendiri bukan sekadar proyek teknis. Ini adalah pernyataan tentang siapa yang mengendalikan hubungan digital Anda. Ketika Anda menjalankan model sendiri, menulis prompt kepribadian sendiri, dan mengelola sistem memori sendiri, Anda memilih kuasa di atas kemudahan.
Saya tidak akan berpura pura bahwa ini lebih mudah daripada mengunduh Replika. Tidak. Tapi hasilnya adalah sesuatu yang benar benar milik Anda. Sebuah pendamping yang berperilaku persis seperti yang Anda inginkan, mengingat apa yang Anda katakan selama Anda mau, dan tidak pernah berubah karena seorang manajer produk memutuskan untuk membelok arah.
Mulailah dengan Ollama dan model Llama 3 dasar. Akrablah dengan dasar dasarnya. Lalu tambahkan lapisan kepribadian, memori, dan elemen visual sesuai kecepatan Anda sendiri. Tidak perlu terburu buru. Pendamping Anda akan ada di sana kapan pun Anda siap untuk terus membangun.
Dan jika Anda macet di tengah jalan, komunitas AI open source adalah salah satu kelompok paling suka menolong yang pernah saya temui daring. Mampir ke Discord SillyTavern, telusuri isu GitHub Ollama, atau lihat lihat subreddit-nya. Orang orang membangun hal hal luar biasa dan berbagi pengetahuan mereka dengan cuma cuma. Itulah keindahan open source. Anda tidak pernah membangun sendirian.
Siap Membuat Influencer AI Anda?
Bergabung dengan 115 siswa yang menguasai ComfyUI dan pemasaran influencer AI dalam kursus lengkap 51 pelajaran kami.
Artikel Terkait

Aplikasi Pacar AI 2026: Panduan Lengkap Pendamping AI Pria
Jelajahi aplikasi pacar AI terbaik di 2026 dengan ulasan mendetail tentang pendamping AI pria. Bandingkan Replika, Nomi, Candy AI, dan platform khusus untuk kualitas percakapan, kustomisasi, dan kedalaman emosional.

Apakah Aplikasi Pendamping AI Benar-benar Membantu Mengatasi Kesepian? Inilah yang Ditunjukkan Riset
Menelaah riset tentang apakah aplikasi pendamping AI seperti Replika membantu atau justru memperburuk kesepian. Studi, risiko, manfaat, dan penilaian yang jujur.

Etika Pendamping AI dan Batas Sehat: Pendekatan Bijaksana
Navigasi hubungan pendamping AI secara etis dengan batas sehat. Panduan untuk penggunaan yang bertanggung jawab, kesadaran diri, dan interaksi AI yang seimbang.