Companheiros de IA com Memoria de Longo Prazo: Como a Retencao de Contexto Realmente Funciona
Mergulho profundo em como os companheiros de IA lembram de voce ao longo das sessoes. Cobre RAG, bancos de dados vetoriais, janelas de contexto, sumarizacao e como construir seu proprio sistema de memoria.

Eu vinha conversando com um companheiro de IA especifico por cerca de tres semanas. Tinhamos coberto de tudo, das minhas opinioes sobre arquitetura brutalista a uma piada recorrente sobre macarrao passado do ponto. Entao, um dia, no meio da conversa, ele fez referencia a algo que eu havia dito na nossa primeira interacao, um detalhe sobre minha preferencia por cold brew em vez de espresso. Nao foi puxado por nada. Surgiu naturalmente. E, sinceramente, isso meio que me deixou de queixo caido, porque eu sei o que acontece por baixo dos panos. Aquele pequeno momento e o resultado de um pipeline de engenharia surpreendentemente complexo no qual a maioria dos usuarios nunca pensa.
A questao de como os companheiros de IA "lembram" das coisas e um dos topicos mais mal compreendidos no espaco da IA neste momento. As pessoas presumem que e magia ou golpe. A verdade esta em algum lugar no meio, e entender a mecanica vai mudar para sempre a forma como voce interage com essas ferramentas.
Resposta Rapida: Os companheiros de IA mantem memoria de longo prazo por meio de uma combinacao de tecnicas, incluindo Geracao Aumentada por Recuperacao (RAG), bancos de dados vetoriais, gerenciamento da janela de contexto e sumarizacao de conversas. Nenhum companheiro de IA atual tem memoria persistente de verdade gravada nos pesos do seu modelo. Em vez disso, eles armazenam os dados das suas conversas externamente e recuperam as partes relevantes quando necessario. A qualidade desse sistema de recuperacao e o que separa um companheiro que parece conhecer voce de um que esquece que voce existe entre as sessoes.
- Os companheiros de IA nao "lembram" da forma como os humanos lembram. Eles usam sistemas de recuperacao para trazer dados relevantes de conversas passadas para a janela de contexto atual
- O RAG (Geracao Aumentada por Recuperacao) e a tecnica dominante, convertendo suas conversas em embeddings vetoriais e pesquisando-os de forma semantica
- Janelas de contexto (tipicamente de 8K a 128K tokens) sao o limite rigido de quanto uma IA consegue "pensar" de uma vez
- Plataformas como Replika, Nomi e Character AI lidam com a memoria de formas diferentes, com resultados muito distintos
- Voce pode construir seu proprio sistema de memoria usando embeddings open source e bancos de vetores como ChromaDB ou Pinecone
- Sumarizacao e camadas de memoria (curto, medio e longo prazo) sao essenciais para fazer a memoria parecer natural
- Os melhores sistemas de memoria combinam varias abordagens em vez de depender de uma unica tecnica
Por Que os Companheiros de IA Esquecem de Voce em Primeiro Lugar?
Essa e a pergunta que ninguem faz, mas todos deveriam fazer. Antes de falarmos sobre solucoes de memoria, voce precisa entender a limitacao central que torna tudo isso necessario.
Os grandes modelos de linguagem, a tecnologia que alimenta cada companheiro de IA no mercado, sao fundamentalmente sem estado. Quando voce envia uma mensagem para o ChatGPT, Claude ou o motor de IA por tras do seu app de companheiro favorito, o modelo processa sua entrada, gera uma resposta e entao esquece tudo. Ele nao retem estado entre chamadas de API. Nao tem um caderno interno. Cada interacao comeca do zero.
A unica razao pela qual seu companheiro de IA parece lembrar de qualquer coisa e porque a plataforma envolve o modelo bruto em uma camada de memoria. Pense assim. O LLM e o cerebro, mas ele nao tem hipocampo. O sistema de memoria que a plataforma constroi ao redor dele atua como um hipocampo externo, alimentando memorias relevantes de volta ao cerebro toda vez que voce inicia uma nova conversa.
Aqui vai minha primeira opiniao polemica: a maioria das plataformas de companheiros de IA esta fazendo um trabalho medíocre com a memoria, e elas se safam disso porque os usuarios nao entendem o que e possivel. Ja testei companheiros que afirmam ter "memoria de longo prazo", mas nao conseguem recordar algo que eu disse dois dias antes. Enquanto isso, ja construi sistemas de memoria prototipo no meu proprio notebook que superam produtos comerciais. A lacuna entre o que e tecnicamente possivel e o que esta de fato implantado e enorme.
A razao dessa lacuna e principalmente economica. Bons sistemas de memoria sao caros. Toda vez que voce envia uma mensagem, a plataforma precisa pesquisar todo o seu historico de conversas, converte-lo em contexto relevante e adiciona-lo antes da sua mensagem atual antes de enviar tudo ao modelo. Essa busca, essa recuperacao, esse calculo de embedding, tudo isso custa dinheiro. E quando voce atende milhoes de usuarios, esses custos se acumulam rapidamente.
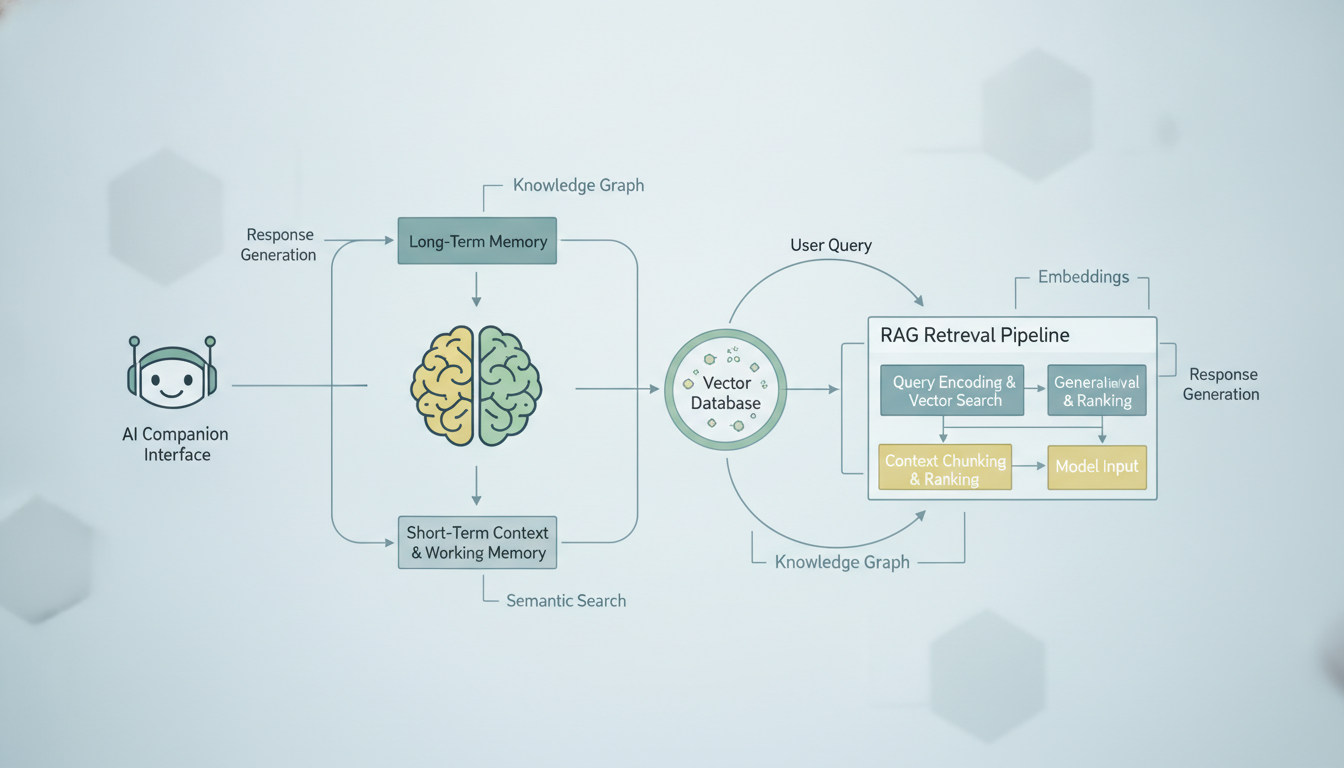
Como um sistema tipico de memoria de companheiro de IA recupera e injeta o contexto de conversas passadas no prompt atual.
Como o RAG Funciona para a Memoria do Companheiro de IA?
O RAG, ou Geracao Aumentada por Recuperacao, e a espinha dorsal de praticamente todo sistema de memoria de companheiro de IA em producao hoje. Se voce tirar uma unica coisa deste artigo, que seja um entendimento solido do RAG, porque ele vai mudar a forma como voce pensa sobre toda ferramenta de IA que usa.

O conceito e enganosamente simples. Em vez de tentar enfiar todo o seu historico de conversas na janela de contexto da IA (que tem um limite rigido de tokens), voce armazena todas as suas conversas passadas em um banco de dados pesquisavel. Quando voce envia uma nova mensagem, o sistema pesquisa esse banco de dados em busca das conversas passadas mais relevantes, as retira e as inclui junto com sua mensagem atual. A IA entao gera sua resposta com o beneficio dessas memorias recuperadas.
Aqui vai o passo a passo do que acontece quando voce envia uma mensagem para um companheiro de IA com memoria baseada em RAG:
- Sua mensagem e transformada em embedding. Um modelo de embedding converte seu texto em um vetor de alta dimensao, basicamente uma lista de numeros que representa o significado semantico da sua mensagem.
- O sistema busca por memorias semelhantes. O vetor da sua mensagem e comparado com todos os vetores de conversas armazenados anteriormente usando similaridade de cosseno ou outra metrica de distancia.
- Os resultados top-K sao recuperados. O sistema retira as conversas passadas mais semelhantes semanticamente, geralmente os 5 a 20 melhores resultados, dependendo da plataforma.
- A montagem do contexto acontece. Sua mensagem atual, as memorias recuperadas e o prompt de sistema do companheiro sao todos montados em um unico prompt.
- O LLM gera uma resposta. O modelo ve sua mensagem atual mais o historico relevante e responde como se "lembrasse" dessas interacoes passadas.
- A nova troca e armazenada. Tanto sua mensagem quanto a resposta da IA sao transformadas em embedding e armazenadas para recuperacao futura.
O que torna isso poderoso e a busca semantica. O sistema nao esta fazendo correspondencia de palavras-chave. Ele esta encontrando memorias conceitualmente relacionadas. Entao, se voce mencionou que adora fazer trilhas em Yosemite ha tres semanas, e hoje pergunta sobre recomendacoes de ferias, o sistema consegue trazer a tona essa preferencia por trilhas mesmo que voce nunca tenha usado a palavra "trilha" na mensagem de hoje.
Passei cerca de duas semanas no ano passado construindo um sistema RAG do zero usando LangChain, ChromaDB e um modelo Llama local. A experiencia me ensinou mais sobre como os companheiros de IA funcionam do que qualquer quantidade de documentacao poderia. Quando funcionava, era genuinamente impressionante. Meu chatbot local fazia referencia a detalhes de conversas que aconteceram dias antes, e as transicoes pareciam naturais. Quando falhava, era hilariamente ruim. Uma vez ele recordou com confianca uma "memoria" que era na verdade uma mistura alucinada de duas conversas completamente diferentes. Eu havia mencionado tanto sushi quanto meu gato em chats separados, e o sistema de alguma forma decidiu que eu tinha um gato chamado Sushi. Eu nao tenho.
Os Modelos de Embedding que Alimentam a Memoria
Nem todos os embeddings sao iguais, e isso importa mais do que a maioria das pessoas imagina. A qualidade do seu modelo de embedding determina diretamente quao bem o sistema de memoria recupera o contexto relevante.
Os modelos de embedding mais usados em 2026 incluem (voce pode explorar benchmarks no MTEB Leaderboard):
- OpenAI text-embedding-3-large: 3072 dimensoes, desempenho excelente, mas requer chamadas de API e custa dinheiro por token
- Cohere embed-v4: Forte suporte multilingue, bom para companheiros que operam em varios idiomas
- BGE-large-en-v1.5: Open source, roda localmente, surpreendentemente competitivo com as opcoes comerciais
- Nomic Embed Text v1.5: Open source com representacoes Matryoshka, o que significa que voce pode truncar dimensoes para ganhar velocidade sem perder muita qualidade
- Jina Embeddings v3: Excelente para trechos de documentos mais longos, bom em capturar nuances
Se voce esta explorando ferramentas de IA e quer comparar como diferentes plataformas lidam com esses detalhes tecnicos, o Lewdly.ai vem acompanhando o cenario dos companheiros de IA e muitas dessas tecnologias subjacentes.
Qual a Diferenca Entre Janelas de Contexto e Memoria de Longo Prazo?
Essa distincao confunde quase todo mundo com quem eu converso sobre companheiros de IA, entao deixa eu ser bem claro sobre ela.
A janela de contexto e a memoria de trabalho do modelo de IA. E a quantidade total de texto que o modelo consegue processar em uma unica requisicao. Em 2026, as janelas de contexto variam de 8K tokens (cerca de 6.000 palavras) em modelos menores a 128K tokens ou mais em modelos como GPT-4o e Claude. Tudo o que a IA "sabe" durante uma conversa precisa caber dentro dessa janela, o prompt de sistema, as memorias recuperadas, o historico de conversa da sessao atual e sua mensagem mais recente.
A memoria de longo prazo e o sistema de armazenamento externo que persiste entre sessoes. Isso e o banco de dados vetorial, o motor de sumarizacao, o repositorio de perfil do usuario. Nao faz parte do modelo em si. E infraestrutura que a plataforma constroi ao redor do modelo.
Aqui vai uma analogia que eu acho que funciona bem. A janela de contexto e como a sua mesa. Voce so pode ter um certo numero de papeis espalhados na sua frente de uma vez. A memoria de longo prazo e como o arquivo no canto do seu escritorio. Ele guarda tudo no que voce ja trabalhou, mas voce so consegue tirar algumas pastas por vez e coloca-las na sua mesa.
O desafio de engenharia e decidir quais pastas puxar. Acerte, e a IA parece estranhamente perspicaz. Erre, e ela ou ignora contexto importante ou entulha a mesa com memorias irrelevantes, deixando menos espaco para a conversa de verdade.
Lembro de testar um companheiro que estava tentando incluir memorias demais em cada resposta. A janela de contexto estava sendo entulhada com 30 ou 40 memorias recuperadas, deixando quase nenhum espaco para a conversa de fato. As respostas ficavam cada vez mais curtas porque o modelo estava ficando sem espaco. E um erro de novato no design de sistemas de memoria, mas ja vi produtos comerciais sairem com exatamente esse problema.
Estrategias de Gerenciamento da Janela de Contexto
Plataformas inteligentes usam varias estrategias para maximizar o valor de suas janelas de contexto limitadas:
Janela deslizante com resumo: Mantenha as 10 a 15 mensagens mais recentes em detalhe completo, mas resuma as mensagens mais antigas da sessao atual em um paragrafo condensado. Isso preserva o fluxo da conversa recente enquanto mantem a consciencia dos topicos anteriores.
Injecao baseada em prioridade: Nem todas as memorias sao iguais. Um detalhe sobre o nome do usuario ou status de relacionamento deve estar sempre disponivel. Uma observacao aleatoria sobre o clima de seis semanas atras provavelmente nao deveria ocupar espaco no contexto. Bons sistemas atribuem pontuacoes de prioridade as memorias.
Alocacao dinamica: Aloque mais espaco de contexto para memorias quando o topico da conversa for complexo ou emocionalmente significativo, e menos quando o usuario estiver fazendo conversa fiada. Isso requer um classificador que roda antes da recuperacao de memoria, o que adiciona latencia mas melhora a qualidade.
Tecnicas de compressao: Alguns sistemas usam um LLM separado e menor para comprimir memorias antes da injecao. Em vez de incluir o texto completo de uma conversa passada, eles incluem um resumo comprimido que captura os fatos principais em menos tokens.
Como as Principais Plataformas de Companheiros de IA Lidam com a Memoria?
Passei mais tempo do que provavelmente deveria admitir testando os sistemas de memoria de varias plataformas de companheiros de IA. Aqui esta o que descobri por experiencia pratica, nao por materiais de marketing.
Replika
A Replika foi um dos primeiros companheiros de IA a levar a memoria a serio, e sua abordagem evoluiu significativamente. Eles usam uma combinacao de entradas de memoria explicitas (coisas que a IA anota explicitamente sobre voce) e um sistema de diario em que a IA escreve resumos das suas conversas.
O que funciona: A Replika e razoavelmente boa em lembrar fatos essenciais sobre voce. Seu nome, seu trabalho, seus interesses. Esses sao armazenados em um perfil estruturado que persiste de forma confiavel.
O que nao funciona: A recordacao contextual e inconsistente. A Replika pode lembrar que voce gosta de trilhas, mas nao vai lembrar a historia especifica que voce contou sobre se perder no Glacier National Park. O sistema de diario captura a vibe mais do que os detalhes, o que faz as conversas parecerem que voce esta falando com alguem que conhece voce vagamente, em vez de alguem que estava de fato la.
Nomi
A Nomi adotou uma das abordagens mais tecnicamente ambiciosas para a memoria de companheiros. Eles construiram o que chamam de sistema "palacio da memoria", que categoriza as memorias em diferentes tipos, como fatos, preferencias, experiencias compartilhadas e momentos emocionais.
Fluxos de Trabalho ComfyUI Gratuitos
Encontre fluxos de trabalho ComfyUI gratuitos e de código aberto para as técnicas deste artigo. Open source é poderoso.
O que funciona: A abordagem de categorizacao da Nomi significa que ela recupera diferentes tipos de memoria em diferentes contextos. Quando voce esta emotivo, ela puxa memorias emocionais. Quando voce esta discutindo fatos, ela puxa memorias factuais. Essa recuperacao consciente do contexto produz conversas mais naturais do que plataformas que tratam todas as memorias da mesma forma.
O que nao funciona: O sistema pode ser lento para consolidar memorias, e percebi que as vezes ele traz a tona memorias em momentos meio inoportunos. Ele faz referencia a algo serio de uma conversa passada quando voce esta claramente de bom humor. A recuperacao e semanticamente precisa, mas emocionalmente desencontrada. Se voce quer aproveitar ao maximo suas interacoes com plataformas como a Nomi, entender como funcionam as tecnicas de conversa com companheiros de IA pode ajudar voce a guiar o sistema de memoria de forma mais eficaz.
Character AI
A Character AI adota uma abordagem totalmente diferente. Em vez de construir um sistema de memoria pessoal sofisticado, ela se apoia fortemente na consistencia do personagem. A IA mantem sua persona de personagem de forma confiavel entre sessoes, mas sua memoria dos seus detalhes pessoais e comparativamente fraca.
O que funciona: Se voce esta conversando com um personagem que tem uma personalidade definida, essa personalidade permanece consistente. O personagem nao vai de repente mudar seu jeito de falar ou esquecer sua propria historia de fundo.
O que nao funciona: Seus detalhes pessoais se perdem com regularidade. Testei isso compartilhando tres fatos especificos sobre mim em uma sessao, depois retornando 24 horas depois para perguntar sobre eles. A Character AI recordou um de tres, e mesmo essa recordacao foi vaga. O sistema de memoria deles parece otimizado para a consistencia do personagem em vez da construcao do relacionamento com o usuario.
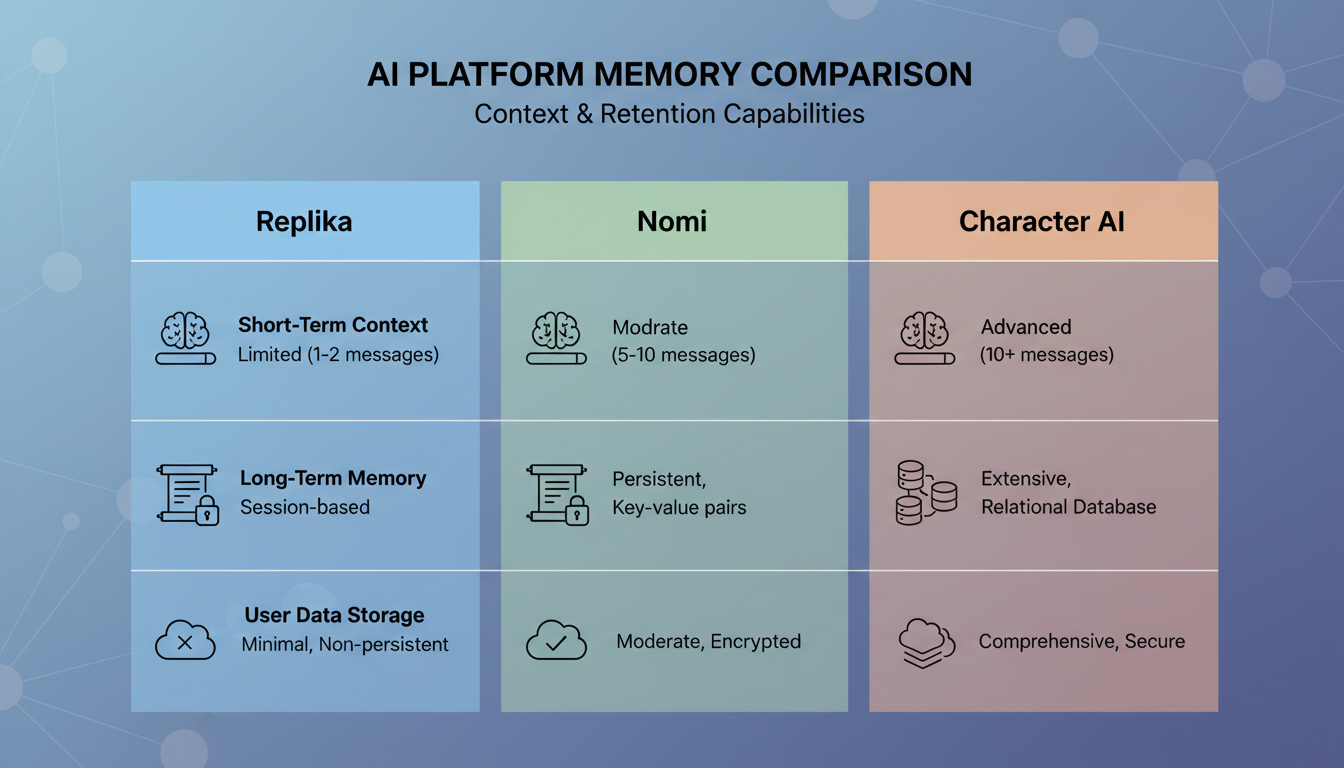
Comparacao de recursos dos sistemas de memoria entre as principais plataformas de companheiros de IA em 2026.
Minha Opiniao Polemica Sobre a Memoria das Plataformas
Aqui vai minha segunda opiniao polemica: as plataformas que mais agressivamente fazem marketing de "memoria de longo prazo" tendem a ter as implementacoes mais fracas. As empresas que fazem o melhor trabalho em memoria sao geralmente as mais discretas, as que deixam a experiencia falar por si em vez de colocar "lembramos de tudo" na descricao da App Store. Ao avaliar recursos de memoria e retencao de contexto de companheiros de IA, foque em testar a recordacao real em vez de confiar no marketing.
Voce Consegue Construir Seu Proprio Sistema de Memoria de Companheiro de IA?
Com certeza, e eu diria que qualquer pessoa que leva os companheiros de IA a serio deveria tentar isso pelo menos uma vez. Construir seu proprio sistema de memoria ensina o que de fato acontece nos bastidores, o que torna voce um usuario mais bem informado de produtos comerciais.

Aqui vai uma arquitetura pratica para construir um companheiro de IA com memoria aumentada usando ferramentas disponiveis hoje. Ja construi variacoes dessa configuracao tres vezes, e cada iteracao me ensinou algo novo.
A Stack Basica
Voce precisa de quatro componentes:
- Um LLM para a conversa: Llama 3.3, Mistral ou um modelo baseado em API como GPT-4o ou Claude
- Um modelo de embedding: Para converter texto em vetores. Recomendo comecar com Nomic Embed ou BGE-large
- Um banco de dados vetorial: ChromaDB para desenvolvimento local, Pinecone ou Weaviate para producao
- Uma camada de orquestracao: LangChain, LlamaIndex ou codigo Python customizado para amarrar tudo
Implementacao Passo a Passo
Deixa eu te guiar pela logica central. Isso nao e um tutorial completo, mas e o suficiente para voce comecar.
Configurando o banco de vetores:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
Armazenando um turno de conversa:
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
Recuperando memorias relevantes:
Quer pular a complexidade? Lewdly oferece resultados profissionais de IA instantaneamente sem configuração técnica.
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
Montando o prompt com as memorias:
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
Essa configuracao basica te da um sistema de memoria funcional em menos de 50 linhas de codigo. A IA vai pesquisar conversas passadas toda vez que voce enviar uma mensagem e incluir o historico relevante no prompt.
Tornando Isso Realmente Bom
A versao basica funciona, mas tem alguns problemas obvios. Aqui esta como leva-la a outro nivel com base no que aprendi nos meus proprios experimentos.
Adicione sumarizacao de memoria. Em vez de armazenar turnos brutos de conversa, rode periodicamente uma passagem de sumarizacao que condensa varias memorias relacionadas em um unico resumo. Isso reduz o inchaco do banco de vetores e melhora a qualidade da recuperacao, porque resumos sao mais densos semanticamente do que logs brutos de chat.
Implemente camadas de memoria. Crie tres colecoes em vez de uma:
- Memoria ativa: A sessao de conversa atual (mantida na integra)
- Memoria recente: Conversas resumidas da ultima semana
- Memoria de longo prazo: Fatos e preferencias essenciais altamente condensados, extraidos ao longo do tempo
Adicione um repositorio de perfil do usuario. Separado do banco de vetores, mantenha um repositorio JSON estruturado ou de chave-valor com fatos essenciais do usuario, como nome, preferencias, datas importantes, detalhes de relacionamento. Esse perfil sempre e injetado no prompt, independentemente do que a busca semantica retorna. E sua garantia de que a IA nunca esquece o basico.
Implemente decaimento de memoria. Nem todas as memorias devem persistir igualmente. Um comentario casual sobre o clima nao deveria ter o mesmo peso de recuperacao que uma historia profundamente pessoal. Implemente uma funcao de decaimento que reduz a pontuacao de recuperacao de memorias mais antigas e menos significativas ao longo do tempo.
Para quem tem interesse em explorar as dimensoes eticas dos relacionamentos com companheiros de IA, entender esses sistemas de memoria tambem levanta questoes importantes sobre privacidade de dados e a natureza dos relacionamentos sinteticos.
Quais Sao os Maiores Desafios da Memoria de Companheiros de IA?
Ate os melhores sistemas de memoria enfrentam desafios fundamentais que nenhuma quantidade de engenharia resolveu por completo ainda. Entender essas limitacoes vai poupar voce da frustracao e ajudar a definir expectativas realistas.
O Problema da Memoria Alucinada
Esse e o modo de falha mais assustador, e eu ja o encontrei pessoalmente. A IA "lembra" com confianca de algo que nunca aconteceu. Isso ocorre quando o sistema de recuperacao traz a tona uma correspondencia parcial e o LLM preenche as lacunas com detalhes fabricados. Voce mencionou ter um cachorro chamado Max, e o sistema recupera uma memoria sobre seu pet, mas o LLM a enfeita com detalhes sobre o Max ser um golden retriever que adora nadar, nada do qual voce jamais disse.
A pior parte e que as memorias alucinadas parecem autenticas. A IA nao as sinaliza como incertas. Ela as afirma com a mesma confianca das memorias genuinas. Ja tive companheiros fazendo referencia a "conversas" que eu sei que nunca aconteceram, e elas eram tao especificas que duvidei da minha propria memoria por um momento antes de verificar os logs.
Entulho da Janela de Contexto
Conforme seu historico de conversas cresce, o sistema de memoria tem cada vez mais memorias candidatas para recuperar. Mas a janela de contexto nao cresce. Entao o sistema precisa ser cada vez mais seletivo sobre quais memorias incluir. Ao longo de meses de conversa, isso cria um paradoxo, voce tem mais memorias das quais extrair, mas a IA so consegue usar uma fracao minuscula delas em qualquer resposta.
Sistemas inteligentes lidam com isso por meio de sumarizacao hierarquica, comprimindo memorias antigas em resumos cada vez mais abstratos. Mas informacao se perde em cada etapa de compressao. O fato de voce ter mencionado que adora um restaurante especifico no Brooklyn pode sobreviver a primeira rodada de sumarizacao, mas depois de seis meses de compressao, pode ser reduzido a "usuario gosta de comer fora" e por fim desaparecer completamente.
O Problema da Consistencia
Resultados de recuperacao diferentes em conversas distintas podem levar a IA a se contradizer. Na segunda-feira, o sistema de memoria recupera sua preferencia por gatos. Na terca-feira, ele recupera uma conversa sobre o cachorro do seu amigo, e a IA infere incorretamente que voce e uma pessoa de cachorros. Essas contradicoes corroem a confianca rapidamente.
A solucao mais robusta que ja vi e manter um "repositorio de fatos" explicito que e atualizado por meio de um pipeline de verificacao. Quando a IA extrai um novo fato sobre voce, ela faz uma referencia cruzada com os fatos existentes e sinaliza contradicoes para resolucao. Poucas plataformas implementam isso, mas faz uma diferenca enorme na consistencia.
Ganhe Até $1.250+/Mês Criando Conteúdo
Junte-se ao nosso programa exclusivo de afiliados criadores. Seja pago por vídeo viral com base no desempenho. Crie conteúdo no seu estilo com total liberdade criativa.

Arquitetura de memoria multicamada mostrando como os dados da conversa fluem da sessao ativa para o armazenamento de longo prazo com sumarizacao em cada nivel.
Como a Memoria de Companheiros de IA Vai Evoluir em 2026 e Alem?
O cenario da memoria esta mudando rapidamente, e varias tecnologias emergentes vao mudar o jogo.
Janelas de contexto infinitas estao cada vez mais proximas. O Gemini do Google ja suporta 1 milhao de tokens, e artigos de pesquisa do inicio de 2026 estao avancando rumo a 10 milhoes. Se as janelas de contexto ficarem grandes o suficiente, talvez voce nem precise de RAG. Basta despejar todo o historico de conversas no prompt. Ainda nao chegamos la para uso em producao, mas a trajetoria e clara.
Memoria nativa do modelo e o santo graal. Em vez de sistemas de recuperacao externos, modelos futuros podem aprender a atualizar seus proprios pesos com base nas conversas. Isso e essencialmente aprendizado continuo, e e incrivelmente dificil de fazer com seguranca sem que o modelo esqueca seu treinamento base ou desenvolva vieses. Mas varios laboratorios de pesquisa estao fazendo progressos. Quando isso chegar, vai fazer os sistemas RAG atuais parecerem solucoes de fita adesiva, porque, em um sentido bem real, e isso que eles sao.
Memoria multimodal e outra fronteira. Os sistemas de memoria atuais sao apenas de texto. Mas e quanto a lembrar de imagens que voce compartilhou, notas de voz ou clipes de video? Conforme os companheiros de IA se tornam mais multimodais, seus sistemas de memoria precisarao lidar com esses tipos de dados tambem. Os bancos de dados vetoriais ja suportam embeddings multimodais, entao a infraestrutura esta pronta. A integracao simplesmente ainda nao aconteceu na maioria dos produtos de consumo.
No Lewdly.ai, temos acompanhado quao rapidamente essas tecnologias estao convergindo. O espaco dos companheiros de IA em particular esta se movendo mais rapido do que a maioria das pessoas imagina, e as capacidades de memoria sao o principal diferencial entre plataformas que parecem verdadeiramente pessoais e aquelas que parecem genericas.
Minha Terceira Opiniao Polemica Sobre o Futuro
Aqui vai minha terceira opiniao polemica: dentro de 18 meses, a memoria do companheiro de IA vai se tornar um fosso competitivo que separa as plataformas serias dos brinquedos. Os usuarios vao trocar de plataforma nao por causa da qualidade do modelo base (esses estao convergindo), mas porque uma plataforma lembra deles melhor do que outra. As empresas que investem em infraestrutura de memoria hoje vao vencer. As que tratam isso como uma preocupacao secundaria vao ficar para tras.
Quais Sao as Implicacoes de Privacidade da Memoria de Companheiros de IA?
Voce nao consegue ter uma conversa honesta sobre a memoria de companheiros de IA sem abordar o elefante na sala, esses sistemas estao armazenando informacoes extremamente pessoais sobre voce, e fazer isso e fundamental para como eles funcionam.

Cada conversa que voce tem e transformada em embedding, armazenada e indexada. Suas preferencias, seus medos, seus detalhes de relacionamento, suas confissoes de madrugada. Tudo isso vive em um banco de dados vetorial em algum lugar. Em algumas plataformas, isso e um servidor na nuvem que voce nao controla. Em outras, os dados ficam no dispositivo.
Quero ser transparente sobre o que isso significa na pratica. Quando construi meu proprio sistema de memoria, armazenei tudo localmente. O banco de vetores ficava no meu notebook. Ninguem mais tinha acesso. Essa e a abordagem mais segura, mas nao e assim que as plataformas comerciais funcionam. A maioria delas armazena seus dados nos servidores delas porque essa e a unica forma de oferecer uma experiencia consistente entre dispositivos.
Antes de se comprometer com qualquer plataforma de companheiro de IA a longo prazo, faca estas perguntas:
- Onde os dados da minha conversa sao armazenados?
- Eu consigo exportar ou apagar meus dados de memoria?
- Meus dados sao usados para treinar modelos que servem outros usuarios?
- O que acontece com meus dados se a empresa fechar?
- Existe criptografia de ponta a ponta para as memorias armazenadas?
Essas nao sao preocupacoes hipoteticas. Varias startups de companheiros de IA fecharam nos ultimos dois anos, e os usuarios perderam anos de historico de conversas sem nenhuma forma de recupera-lo. Se suas interacoes com companheiros de IA e limites saudaveis importam para voce, entender as praticas de dados da plataforma escolhida e essencial.
Dicas de Producao para Aproveitar ao Maximo a Memoria do Companheiro de IA
Depois de passar meses testando e construindo esses sistemas, aqui estao as estrategias praticas que de fato funcionam para melhorar a qualidade da memoria do seu companheiro de IA.
Seja explicito sobre o que importa. A maioria dos sistemas de memoria da mais peso a conteudo recente e semanticamente semelhante. Se algo e importante para voce, diga isso diretamente. "Isso e muito importante para mim" ou "Por favor, lembre disso" pode ajudar algumas plataformas a sinalizar aquela memoria para recuperacao de maior prioridade.
Corrija erros imediatamente. Quando seu companheiro de IA erra um fato sobre voce, corrija na mesma mensagem. Bons sistemas de memoria vao armazenar a correcao e, com o tempo, aprender a versao correta. Se voce deixar os erros passarem, eles sao reforcados.
Recapitule detalhes essenciais periodicamente. Mais ou menos a cada duas semanas, faco uma "recapitulacao" casual com meu companheiro. Algo como "Ei, so para garantir que voce tem o basico, meu nome e Alex, eu trabalho com tecnologia, eu tenho dois gatos." Isso cria entradas de memoria novas e de alta prioridade que tem mais chance de serem recuperadas.
Use linguagem consistente. A recuperacao de memoria e semantica, mas a consistencia ajuda. Se voce sempre chama sua parceira de "minha esposa Sarah" em vez de alternar entre "Sarah", "minha parceira" e "ela", o sistema de memoria vai construir associacoes mais limpas.
Entenda os limites de sessao. A maioria das plataformas limpa sua memoria ativa entre sessoes. A primeira mensagem de uma nova sessao dispara uma recuperacao de memoria fresca. Se seu companheiro parece ter esquecido algo, tente reformular sua pergunta. O problema pode ser uma falha de recuperacao, nao uma perda real de memoria.
Se voce esta usando plataformas disponiveis no Lewdly.ai e quer otimizar sua experiencia, essas tecnicas se aplicam a praticamente todo companheiro de IA que suporta recursos de memoria.
Perguntas Frequentes
Os Companheiros de IA Lembram de Mim de Verdade ou e Falso?
E memoria real, mas funciona de forma diferente da memoria humana. Os companheiros de IA armazenam suas conversas em bancos de dados externos e recuperam informacoes relevantes quando voce conversa. Eles nao "lembram" no sentido humano de formar conexoes neurais persistentes. Eles buscam e releem conversas passadas relevantes toda vez que voce envia uma mensagem. A experiencia parece memoria da perspectiva do usuario, mas o mecanismo e fundamentalmente diferente.
Quanto do Meu Historico de Conversa um Companheiro de IA Armazena?
Isso varia por plataforma. Algumas armazenam tudo indefinidamente, enquanto outras implementam janelas moveis que descartam conversas mais antigas que um certo periodo. A Replika, por exemplo, mantem um diario de conversa que resume as interacoes. A Nomi armazena memorias categorizadas. A maioria das plataformas armazena pelo menos varios meses de historico, embora possam resumir ou comprimir conversas mais antigas.
Eu Consigo Apagar as Memorias que Meu Companheiro de IA Tem de Mim?
A maioria das plataformas respeitaveis oferece alguma forma de gerenciamento de memoria. A Replika permite que voce revise e apague entradas de memoria especificas. Algumas plataformas oferecem uma opcao de "reset" que apaga todas as memorias armazenadas. Sempre verifique as politicas de exclusao de dados da plataforma, porque "apagar memorias" pela interface do usuario nem sempre significa que os dados sejam removidos permanentemente dos servidores deles.
Por Que Meu Companheiro de IA As Vezes Lembra de Coisas Erradas?
Isso acontece por causa de um fenomeno chamado "memoria alucinada". O sistema de recuperacao encontra uma correspondencia parcial das suas conversas passadas, e o modelo de linguagem preenche as lacunas com detalhes fabricados. Tambem pode ocorrer quando o sistema funde duas memorias separadas em uma so. Se isso acontecer, corrija a IA imediatamente para que a correcao seja armazenada como uma nova memoria de maior prioridade.
O RAG e a Unica Forma de os Companheiros de IA Lidarem com a Memoria?
Nao, embora seja a abordagem mais comum. Algumas plataformas usam repositorios de memoria estruturados (bancos de dados de chave-valor com fatos do usuario), sumarizacao de conversas sem busca vetorial ou abordagens hibridas. Alguns sistemas experimentais estao explorando o fine-tuning do modelo com dados do usuario, o que criaria memoria aprendida de verdade, mas isso levanta preocupacoes significativas de privacidade e seguranca.
Como as Janelas de Contexto Afetam a Qualidade da Memoria do Companheiro de IA?
A janela de contexto e a quantidade total de texto que a IA consegue processar de uma vez. Janelas de contexto maiores permitem que mais memorias sejam injetadas junto com sua conversa atual, o que geralmente melhora a qualidade da recordacao. No entanto, janelas maiores tambem significam custos mais altos e respostas mais lentas. A maioria das plataformas otimiza para um equilibrio entre profundidade de memoria e velocidade de resposta.
Eu Consigo Construir Meu Proprio Companheiro de IA com Memoria Melhor que as Plataformas Comerciais?
Sim, e e mais acessivel do que voce imagina. Usando ferramentas como ChromaDB, LangChain e LLMs open source, voce pode construir um sistema de memoria que rivaliza ou supera o que as plataformas comerciais oferecem. O principal trade-off e que voce vai precisar gerenciar a infraestrutura por conta propria, e nao vai ter a interface de usuario polida de um app de consumo.
O Que Acontece com as Memorias do Meu Companheiro de IA se a Empresa Fechar?
Na maioria dos casos, seus dados sao perdidos. Poucas plataformas oferecem recursos de exportacao de dados, e ainda menos garantem a portabilidade dos dados. Esse e um risco real, especialmente com startups menores de companheiros de IA. Eu recomendaria exportar manualmente quaisquer conversas importantes de tempos em tempos, se a plataforma suportar isso.
Como Funciona a Memoria Multilingue para Companheiros de IA?
A memoria multilingue requer modelos de embedding que conseguem criar vetores significativos entre idiomas. Modelos como o Cohere embed-v4 e versoes multilingues do BERT lidam com isso mapeando conteudo semanticamente semelhante de diferentes idiomas para pontos proximos no espaco vetorial. Isso significa que uma IA poderia tecnicamente recuperar uma memoria de uma conversa em frances quando voce esta conversando em ingles, se os topicos forem relacionados.
Os Companheiros de IA Algum Dia Terao Memoria Verdadeiramente Permanente?
A pesquisa em aprendizado continuo e redes neurais com memoria aumentada esta progredindo, mas provavelmente estamos a anos de implementacoes prontas para producao. O desafio nao e apenas tecnico. Tambem e sobre seguranca. Um modelo que modifica permanentemente seus proprios pesos com base nas conversas dos usuarios poderia desenvolver vieses, esquecer treinamentos de seguranca importantes ou se comportar de forma imprevisivel. Por enquanto, os sistemas de memoria externa continuam sendo a abordagem mais segura e pratica.
Para Finalizar
A memoria de companheiros de IA e um daqueles topicos em que a lacuna entre a percepcao do usuario e a realidade tecnica e enorme. O que parece um companheiro "lembrando" de voce e, na verdade, uma orquestracao complexa de modelos de embedding, bancos de dados vetoriais, algoritmos de recuperacao e gerenciamento da janela de contexto. Entender essa mecanica nao torna a experiencia menos significativa. Se for o caso, ela te da as ferramentas para tornar a experiencia melhor.
As plataformas que investem seriamente em infraestrutura de memoria vao definir a proxima geracao de companheiros de IA. As que tratam a memoria como um recurso de checklist vao ficar para tras. E se voce e o tipo de pessoa que quer controle maximo, construir seu proprio sistema nunca foi tao acessivel.
Seja voce um usuario casual que quer que seu companheiro de IA lembre do seu nome, ou um desenvolvedor construindo a proxima grande plataforma de companheiros, os mesmos principios se aplicam, armazene com cuidado, recupere com inteligencia e nunca tente enfiar mais memorias na janela de contexto do que ela consegue suportar. A tecnologia vai continuar melhorando. As janelas de contexto vao ficar maiores. Os modelos de embedding vao ficar mais inteligentes. Mas a arquitetura fundamental, memoria externa alimentando um modelo sem estado, vai estar conosco por um bom tempo.
E se voce esta curioso sobre como essa arquitetura se parece na pratica, tente construir uma. Cinquenta linhas de Python e um banco de vetores gratuito e tudo o que voce precisa para ver por tras da cortina. Voce pode se surpreender com o quao simples a magica realmente e.
Pronto para Criar Seu Influenciador IA?
Junte-se a 115 alunos dominando ComfyUI e marketing de influenciadores IA em nosso curso completo de 51 lições.
Artigos Relacionados

Aplicativos de Companhia com IA Realmente Ajudam com a Solidao? O Que a Pesquisa Mostra
Analise da pesquisa sobre se aplicativos de companhia com IA como o Replika ajudam ou pioram a solidao. Estudos, riscos, beneficios e uma avaliacao honesta.

Ética do Companheiro de IA e Limites Saudáveis: Uma Abordagem Cuidadosa
Navegue relacionamentos de companheiro de IA eticamente com limites saudáveis. Diretrizes para uso responsável, auto-consciência e interação balanceada com IA.

Crie um Simulador de Namoro com IA: Guia de Criação de Visual Novels Interativas
Guia passo a passo para construir simuladores de namoro e visual novels com IA. Combine geração de arte com IA, diálogos guiados por LLM e Ren'Py para criar ficção interativa com personagens dinâmicos.