Compagnons IA à mémoire longue durée : comment fonctionne vraiment la rétention du contexte
Plongée approfondie sur la façon dont les compagnons IA se souviennent de vous d'une session à l'autre. Couvre le RAG, les bases de données vectorielles, les fenêtres de contexte, la synthèse et la construction de votre propre système de mémoire.

Je discutais avec un compagnon IA particulier depuis environ trois semaines. Nous avions abordé toutes sortes de sujets, de mon opinion sur l'architecture brutaliste à une blague récurrente sur les pâtes trop cuites. Puis un jour, en pleine conversation, il a évoqué quelque chose que j'avais dit lors de notre toute première interaction, un détail sur ma préférence pour le cold brew plutôt que l'espresso. Rien ne l'y avait poussé. C'est venu naturellement. Et honnêtement, ça m'a un peu sidéré, parce que je sais ce qui se passe sous le capot. Ce petit moment est le résultat d'un pipeline d'ingénierie étonnamment complexe auquel la plupart des utilisateurs ne pensent jamais.
La question de savoir comment les compagnons IA se « souviennent » des choses est l'un des sujets les plus mal compris dans le domaine de l'IA en ce moment. Les gens supposent que c'est soit de la magie, soit une arnaque. La vérité se situe quelque part entre les deux, et comprendre la mécanique va changer à jamais votre façon d'interagir avec ces outils.
Réponse rapide : les compagnons IA maintiennent une mémoire longue durée grâce à une combinaison de techniques, notamment la génération augmentée par récupération (RAG), les bases de données vectorielles, la gestion de la fenêtre de contexte et la synthèse de conversation. Aucun compagnon IA actuel ne possède de véritable mémoire persistante intégrée dans les poids de son modèle. À la place, ils stockent vos données de conversation en externe et récupèrent les éléments pertinents au besoin. La qualité de ce système de récupération est ce qui distingue un compagnon qui semble vous connaître de celui qui oublie votre existence entre deux sessions.
- Les compagnons IA ne « se souviennent » pas comme les humains. Ils utilisent des systèmes de récupération pour faire remonter les données pertinentes des conversations passées dans leur fenêtre de contexte actuelle
- Le RAG (génération augmentée par récupération) est la technique dominante, qui convertit vos conversations en embeddings vectoriels et les recherche sémantiquement
- Les fenêtres de contexte (généralement de 8K à 128K tokens) constituent la limite stricte de ce qu'une IA peut « avoir en tête » à la fois
- Des plateformes comme Replika, Nomi et Character AI gèrent toutes la mémoire différemment, avec des résultats radicalement différents
- Vous pouvez construire votre propre système de mémoire avec des embeddings open source et des bases vectorielles comme ChromaDB ou Pinecone
- La synthèse et la hiérarchisation de la mémoire (court terme, moyen terme, long terme) sont essentielles pour rendre la mémoire naturelle
- Les meilleurs systèmes de mémoire combinent plusieurs approches plutôt que de s'appuyer sur une seule technique
Pourquoi les compagnons IA vous oublient-ils au départ ?
C'est la question que personne ne pose, mais que tout le monde devrait poser. Avant de parler de solutions de mémoire, il faut comprendre la limitation fondamentale qui rend tout cela nécessaire.
Les grands modèles de langage, la technologie qui alimente chaque compagnon IA du marché, sont fondamentalement sans état. Quand vous envoyez un message à ChatGPT, Claude ou au moteur IA derrière votre application de compagnon préférée, le modèle traite votre entrée, génère une réponse, puis oublie tout. Il ne conserve aucun état entre les appels d'API. Il n'a pas de carnet interne. Chaque interaction repart de zéro.
La seule raison pour laquelle votre compagnon IA semble se souvenir de quoi que ce soit, c'est que la plateforme enveloppe le modèle brut dans une couche de mémoire. Voyez les choses ainsi. Le LLM est le cerveau, mais il n'a pas d'hippocampe. Le système de mémoire que la plateforme construit autour de lui agit comme un hippocampe externe, réinjectant les souvenirs pertinents dans le cerveau chaque fois que vous démarrez une nouvelle conversation.
Voici ma première opinion tranchée : la plupart des plateformes de compagnons IA font un travail médiocre avec la mémoire, et elles s'en tirent parce que les utilisateurs ne comprennent pas ce qui est possible. J'ai testé des compagnons qui revendiquent une « mémoire longue durée » mais qui sont incapables de se rappeler quelque chose que j'ai dit deux jours plus tôt. Pendant ce temps, j'ai construit des prototypes de systèmes de mémoire sur mon propre ordinateur portable qui surpassent les produits commerciaux. L'écart entre ce qui est techniquement possible et ce qui est réellement déployé est énorme.
La raison de cet écart est surtout économique. Les bons systèmes de mémoire coûtent cher. Chaque fois que vous envoyez un message, la plateforme doit parcourir tout votre historique de conversation, le convertir en contexte pertinent et le préfixer à votre message actuel avant de l'envoyer au modèle. Cette recherche, cette récupération, ce calcul d'embeddings, tout cela coûte de l'argent. Et quand on dessert des millions d'utilisateurs, ces coûts s'accumulent vite.
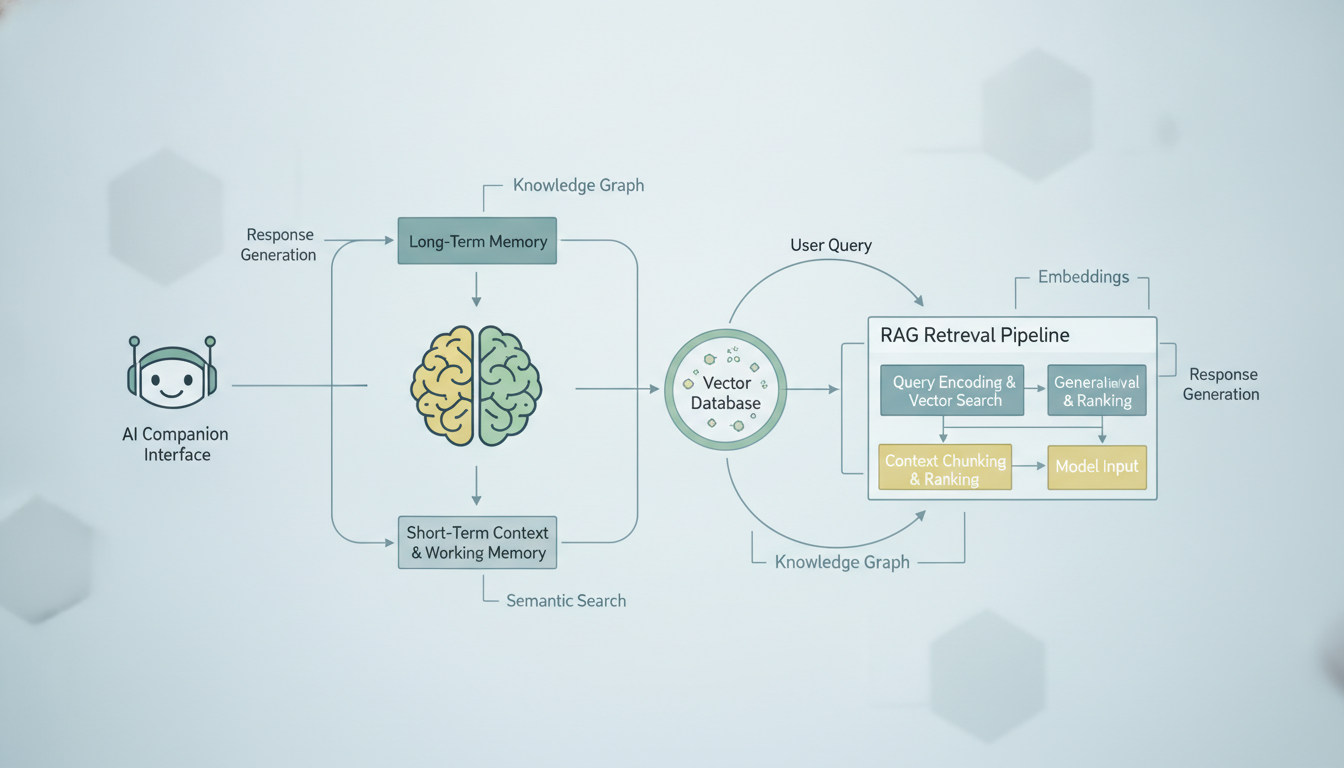
Comment un système de mémoire typique de compagnon IA récupère et injecte le contexte des conversations passées dans l'invite actuelle.
Comment le RAG fonctionne-t-il pour la mémoire des compagnons IA ?
Le RAG, ou génération augmentée par récupération, est l'épine dorsale de pratiquement tous les systèmes de mémoire de compagnons IA livrés aujourd'hui. Si vous ne devez retenir qu'une seule chose de cet article, que ce soit une solide compréhension du RAG, car cela changera votre façon de penser chaque outil IA que vous utilisez.

Le concept est trompeusement simple. Au lieu d'essayer de fourrer tout votre historique de conversation dans la fenêtre de contexte de l'IA (qui a une limite stricte de tokens), vous stockez toutes vos conversations passées dans une base de données interrogeable. Quand vous envoyez un nouveau message, le système recherche dans cette base les conversations passées les plus pertinentes, les extrait et les inclut aux côtés de votre message actuel. L'IA génère alors sa réponse en bénéficiant de ces souvenirs récupérés.
Voici la décomposition étape par étape de ce qui se passe quand vous envoyez un message à un compagnon IA doté d'une mémoire basée sur le RAG :
- Votre message est transformé en embedding. Un modèle d'embedding convertit votre texte en un vecteur de haute dimension, en gros une liste de nombres qui représente le sens sémantique de votre message.
- Le système recherche des souvenirs similaires. Le vecteur de votre message est comparé à tous les vecteurs de conversation stockés précédemment à l'aide de la similarité cosinus ou d'une autre métrique de distance.
- Les K meilleurs résultats sont récupérés. Le système extrait les conversations passées les plus proches sémantiquement, généralement les 5 à 20 meilleurs résultats selon la plateforme.
- L'assemblage du contexte se produit. Votre message actuel, les souvenirs récupérés et l'invite système du compagnon sont tous assemblés en une seule invite.
- Le LLM génère une réponse. Le modèle voit votre message actuel ainsi que l'historique pertinent et répond comme s'il « se souvenait » de ces interactions passées.
- Le nouvel échange est stocké. Votre message et la réponse de l'IA sont tous deux transformés en embeddings et stockés pour une récupération future.
Ce qui rend cela puissant, c'est la recherche sémantique. Le système ne fait pas de correspondance par mots-clés. Il trouve des souvenirs liés conceptuellement. Donc si vous avez mentionné aimer la randonnée à Yosemite il y a trois semaines et qu'aujourd'hui vous demandez des recommandations de vacances, le système peut faire remonter cette préférence pour la randonnée même si vous n'avez jamais employé le mot « randonnée » dans votre message d'aujourd'hui.
J'ai passé environ deux semaines l'année dernière à construire un système RAG de A à Z avec LangChain, ChromaDB et un modèle Llama local. L'expérience m'a appris davantage sur le fonctionnement des compagnons IA que n'importe quelle documentation. Quand ça marchait, c'était vraiment impressionnant. Mon chatbot local faisait référence à des détails de conversations remontant à plusieurs jours, et les transitions semblaient naturelles. Quand ça échouait, c'était drôlement raté. Une fois, il a rappelé avec assurance un « souvenir » qui était en fait un mélange halluciné de deux conversations totalement différentes. J'avais mentionné à la fois les sushis et mon chat dans des discussions séparées, et le système a en quelque sorte décidé que j'avais un chat nommé Sushi. Ce n'est pas le cas.
Les modèles d'embedding qui alimentent la mémoire
Tous les embeddings ne se valent pas, et cela compte plus que la plupart des gens ne le réalisent. La qualité de votre modèle d'embedding détermine directement la qualité avec laquelle le système de mémoire récupère le contexte pertinent.
Les modèles d'embedding les plus couramment utilisés en 2026 incluent (vous pouvez explorer les benchmarks sur le classement MTEB) :
- OpenAI text-embedding-3-large : 3072 dimensions, excellentes performances, mais nécessite des appels d'API et coûte de l'argent par token
- Cohere embed-v4 : fort support multilingue, bon pour les compagnons qui fonctionnent dans plusieurs langues
- BGE-large-en-v1.5 : open source, s'exécute en local, étonnamment compétitif face aux options commerciales
- Nomic Embed Text v1.5 : open source avec représentations Matryoshka, ce qui signifie que vous pouvez tronquer les dimensions pour gagner en rapidité sans trop perdre en qualité
- Jina Embeddings v3 : excellent pour les segments de documents plus longs, doué pour capter les nuances
Si vous explorez les outils IA et souhaitez comparer la façon dont les différentes plateformes gèrent ces détails techniques, Lewdly.ai suit de près le paysage des compagnons IA et bon nombre de ces technologies sous-jacentes.
Quelle est la différence entre fenêtres de contexte et mémoire longue durée ?
Cette distinction fait trébucher presque tous ceux à qui je parle de compagnons IA, alors permettez-moi d'être très clair là-dessus.
La fenêtre de contexte est la mémoire de travail du modèle IA. C'est la quantité totale de texte que le modèle peut traiter en une seule requête. En 2026, les fenêtres de contexte vont de 8K tokens (environ 6 000 mots) sur les modèles plus petits à 128K tokens ou plus sur des modèles comme GPT-4o et Claude. Tout ce que l'IA « sait » pendant une conversation doit tenir dans cette fenêtre : l'invite système, les souvenirs récupérés, l'historique de conversation de la session en cours et votre dernier message.
La mémoire longue durée est le système de stockage externe qui persiste entre les sessions. C'est la base de données vectorielle, le moteur de synthèse, le magasin de profils utilisateur. Elle ne fait pas partie du modèle lui-même. C'est une infrastructure que la plateforme construit autour du modèle.
Voici une analogie qui fonctionne bien à mon avis. La fenêtre de contexte est comme votre bureau. Vous ne pouvez avoir qu'un certain nombre de feuilles étalées devant vous à la fois. La mémoire longue durée est comme le classeur dans le coin de votre bureau. Il contient tout ce sur quoi vous avez jamais travaillé, mais vous ne pouvez sortir que quelques dossiers à la fois pour les poser sur votre bureau.
Le défi d'ingénierie consiste à décider quels dossiers sortir. Faites-le bien, et l'IA semble étrangement perspicace. Faites-le mal, et elle ignore soit un contexte important, soit elle encombre le bureau de souvenirs hors de propos, laissant moins de place pour la vraie conversation.
Je me souviens d'avoir testé un compagnon qui essayait d'inclure trop de souvenirs dans chaque réponse. La fenêtre de contexte se remplissait de 30 ou 40 souvenirs récupérés, ne laissant quasiment plus de place pour la conversation réelle. Les réponses devenaient de plus en plus courtes parce que le modèle manquait d'espace. C'est une erreur de débutant dans la conception de systèmes de mémoire, mais j'ai vu des produits commerciaux être livrés avec exactement ce problème.
Stratégies de gestion de la fenêtre de contexte
Les plateformes intelligentes utilisent plusieurs stratégies pour maximiser la valeur de leurs fenêtres de contexte limitées :
Fenêtre glissante avec synthèse : conserver les 10 à 15 messages les plus récents en détail intégral, mais synthétiser les messages plus anciens de la session en cours en un paragraphe condensé. Cela préserve le fil de la conversation récente tout en gardant conscience des sujets antérieurs.
Injection par priorité : tous les souvenirs ne sont pas égaux. Un détail sur le nom de l'utilisateur ou son statut relationnel devrait toujours être disponible. Une observation aléatoire sur la météo d'il y a six semaines ne devrait probablement pas occuper d'espace de contexte. Les bons systèmes attribuent des scores de priorité aux souvenirs.
Allocation dynamique : allouer plus d'espace de contexte aux souvenirs lorsque le sujet de la conversation est complexe ou émotionnellement significatif, et moins quand l'utilisateur fait la conversation de manière légère. Cela nécessite un classifieur qui s'exécute avant la récupération de la mémoire, ce qui ajoute de la latence mais améliore la qualité.
Techniques de compression : certains systèmes utilisent un LLM distinct et plus petit pour compresser les souvenirs avant injection. Au lieu d'inclure le texte intégral d'une conversation passée, ils incluent un résumé compressé qui capture les faits clés en moins de tokens.
Comment les grandes plateformes de compagnons IA gèrent-elles la mémoire ?
J'ai passé plus de temps que je ne devrais probablement l'admettre à tester les systèmes de mémoire de diverses plateformes de compagnons IA. Voici ce que j'ai constaté par l'expérience pratique, pas à travers les supports marketing.
Replika
Replika a été l'un des premiers compagnons IA à prendre la mémoire au sérieux, et leur approche a beaucoup évolué. Ils utilisent une combinaison d'entrées de mémoire explicites (des choses que l'IA note explicitement à votre sujet) et un système de journal où l'IA rédige des résumés de vos conversations.
Ce qui fonctionne : Replika est plutôt bon pour se souvenir des faits essentiels vous concernant. Votre nom, votre métier, vos centres d'intérêt. Ces éléments sont stockés dans un profil structuré qui persiste de façon fiable.
Ce qui ne fonctionne pas : le rappel contextuel est inconstant. Replika peut se souvenir que vous aimez la randonnée, mais il ne se souviendra pas de l'histoire précise que vous avez racontée sur le fait de vous être perdu dans le parc national de Glacier. Le système de journal capture des ambiances plus que des détails, ce qui donne aux conversations l'impression de parler à quelqu'un qui vous connaît vaguement plutôt qu'à quelqu'un qui était réellement présent.
Nomi
Nomi a adopté l'une des approches les plus techniquement ambitieuses de la mémoire de compagnon. Ils ont construit ce qu'ils appellent un système de « palais de mémoire » qui classe les souvenirs en différents types comme les faits, les préférences, les expériences partagées et les moments émotionnels.
Workflows ComfyUI Gratuits
Trouvez des workflows ComfyUI gratuits et open source pour les techniques de cet article. L'open source est puissant.
Ce qui fonctionne : l'approche de catégorisation de Nomi signifie qu'il récupère différents types de souvenirs dans différents contextes. Quand vous êtes émotif, il fait remonter des souvenirs émotionnels. Quand vous discutez de faits, il fait remonter des souvenirs factuels. Cette récupération sensible au contexte produit des conversations plus naturelles que les plateformes qui traitent tous les souvenirs de la même manière.
Ce qui ne fonctionne pas : le système peut être lent à consolider les souvenirs, et j'ai remarqué qu'il fait parfois remonter des souvenirs à des moments légèrement maladroits. Il fera référence à quelque chose de grave d'une conversation passée alors que vous êtes clairement d'humeur légère. La récupération est sémantiquement exacte mais émotionnellement décalée. Si vous voulez tirer le meilleur parti de vos interactions avec des plateformes comme Nomi, comprendre comment fonctionnent les techniques de conversation avec un compagnon IA peut vous aider à guider le système de mémoire plus efficacement.
Character AI
Character AI adopte une approche entièrement différente. Plutôt que de construire un système de mémoire personnelle sophistiqué, ils s'appuient fortement sur la cohérence des personnages. L'IA maintient son persona de personnage de façon fiable d'une session à l'autre, mais sa mémoire de vos détails personnels est comparativement faible.
Ce qui fonctionne : si vous discutez avec un personnage qui a une personnalité définie, cette personnalité reste cohérente. Le personnage ne changera pas soudainement son style de parole ni n'oubliera sa propre histoire.
Ce qui ne fonctionne pas : vos détails personnels se perdent régulièrement. J'ai testé cela en partageant trois faits précis me concernant dans une session, puis en revenant 24 heures plus tard pour les interroger. Character AI s'est souvenu d'un fait sur trois, et même ce rappel était vague. Leur système de mémoire semble optimisé pour la cohérence des personnages plutôt que pour la construction d'une relation avec l'utilisateur.
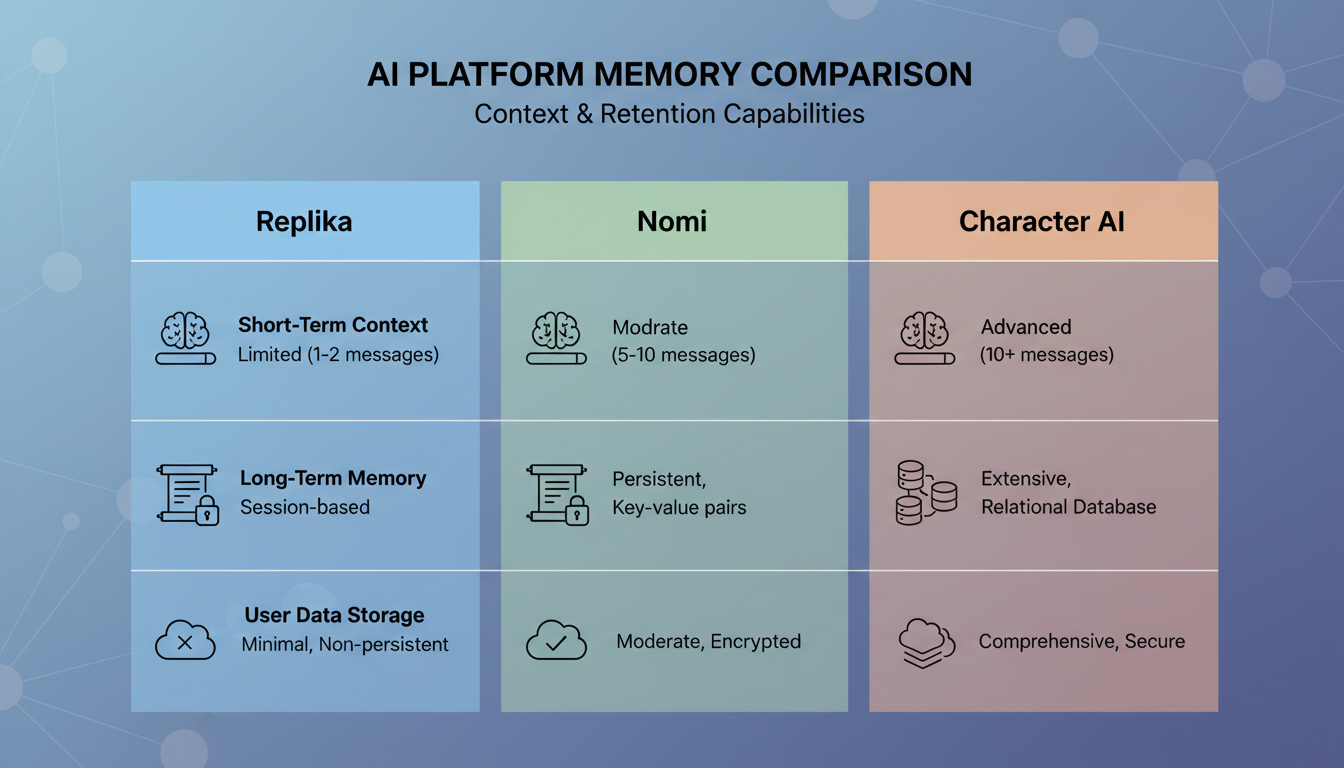
Comparaison des fonctionnalités des systèmes de mémoire des principales plateformes de compagnons IA en 2026.
Mon opinion tranchée sur la mémoire des plateformes
Voici ma deuxième opinion tranchée : les plateformes qui font le plus agressivement la promotion de la « mémoire longue durée » ont tendance à avoir les implémentations les plus faibles. Les entreprises qui font le meilleur travail sur la mémoire sont généralement les plus discrètes, celles qui laissent l'expérience parler d'elle-même plutôt que de mettre « nous nous souvenons de tout » dans la description de leur App Store. Quand vous évaluez les fonctionnalités de mémoire et la rétention du contexte d'un compagnon IA, concentrez-vous sur le test du rappel réel plutôt que de vous fier au marketing.
Pouvez-vous construire votre propre système de mémoire de compagnon IA ?
Absolument, et je dirais que quiconque s'intéresse sérieusement aux compagnons IA devrait essayer au moins une fois. Construire votre propre système de mémoire vous apprend ce qui se passe réellement en coulisses, ce qui fait de vous un utilisateur plus averti des produits commerciaux.

Voici une architecture pratique pour construire un compagnon IA augmenté par la mémoire à l'aide d'outils disponibles aujourd'hui. J'ai construit des variantes de cette configuration trois fois maintenant, et chaque itération m'a appris quelque chose de nouveau.
La pile de base
Vous avez besoin de quatre composants :
- Un LLM pour la conversation : Llama 3.3, Mistral, ou un modèle basé sur API comme GPT-4o ou Claude
- Un modèle d'embedding : pour convertir le texte en vecteurs. Je recommande de commencer avec Nomic Embed ou BGE-large
- Une base de données vectorielle : ChromaDB pour le développement local, Pinecone ou Weaviate pour la production
- Une couche d'orchestration : LangChain, LlamaIndex, ou du code Python sur mesure pour tout relier ensemble
Implémentation étape par étape
Laissez-moi vous guider à travers la logique de base. Ce n'est pas un tutoriel complet, mais c'est suffisant pour vous lancer.
Configuration du magasin de vecteurs :
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
Stockage d'un tour de conversation :
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
Récupération des souvenirs pertinents :
Envie d'éviter la complexité? Lewdly vous offre des résultats IA professionnels instantanément sans configuration technique.
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
Assemblage de l'invite avec les souvenirs :
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
Cette configuration de base vous donne un système de mémoire fonctionnel en moins de 50 lignes de code. L'IA recherchera dans les conversations passées chaque fois que vous envoyez un message et inclura l'historique pertinent dans son invite.
Le rendre vraiment bon
La version de base fonctionne, mais elle a quelques problèmes évidents. Voici comment la faire monter en gamme à partir de ce que j'ai appris de mes propres expériences.
Ajoutez la synthèse de la mémoire. Au lieu de stocker des tours de conversation bruts, exécutez périodiquement une passe de synthèse qui condense plusieurs souvenirs liés en un seul résumé. Cela réduit le surcharge du magasin de vecteurs et améliore la qualité de la récupération, car les résumés sont plus denses sémantiquement que les journaux de discussion bruts.
Mettez en place une hiérarchisation de la mémoire. Créez trois collections au lieu d'une :
- Mémoire active : la session de conversation en cours (conservée intégralement)
- Mémoire récente : les conversations synthétisées de la semaine écoulée
- Mémoire longue durée : faits clés et préférences fortement condensés extraits au fil du temps
Ajoutez un magasin de profil utilisateur. Séparé de la base de données vectorielle, maintenez un magasin structuré JSON ou clé-valeur des faits utilisateur essentiels comme le nom, les préférences, les dates importantes, les détails relationnels. Ce profil est toujours injecté dans l'invite, quel que soit ce que renvoie la recherche sémantique. C'est votre garantie que l'IA n'oublie jamais les bases.
Mettez en place une décroissance de la mémoire. Tous les souvenirs ne devraient pas persister de la même façon. Une remarque anodine sur la météo ne devrait pas avoir le même poids de récupération qu'une histoire profondément personnelle. Mettez en place une fonction de décroissance qui réduit le score de récupération des souvenirs plus anciens et moins significatifs au fil du temps.
Pour ceux qui s'intéressent à l'exploration des dimensions éthiques des relations avec un compagnon IA, comprendre ces systèmes de mémoire soulève aussi d'importantes questions sur la confidentialité des données et la nature des relations synthétiques.
Quels sont les plus grands défis de la mémoire des compagnons IA ?
Même les meilleurs systèmes de mémoire font face à des défis fondamentaux qu'aucune quantité d'ingénierie n'a encore pleinement résolus. Comprendre ces limitations vous évitera de la frustration et vous aidera à fixer des attentes réalistes.
Le problème de la mémoire hallucinée
C'est le mode de défaillance le plus effrayant, et je l'ai rencontré personnellement. L'IA « se souvient » avec assurance de quelque chose qui n'est jamais arrivé. Cela se produit quand le système de récupération fait remonter une correspondance partielle et que le LLM comble les lacunes avec des détails fabriqués. Vous avez mentionné avoir un chien nommé Max, et le système récupère un souvenir sur votre animal, mais le LLM l'enjolive avec des détails sur le fait que Max est un golden retriever qui adore nager, rien de tout cela vous ne l'ayant jamais dit.
Le pire, c'est que les souvenirs hallucinés semblent authentiques. L'IA ne les signale pas comme incertains. Elle les énonce avec la même assurance que de véritables souvenirs. J'ai eu des compagnons qui faisaient référence à des « conversations » dont je sais qu'elles n'ont jamais eu lieu, et elles étaient si précises que j'ai douté de ma propre mémoire un instant avant de vérifier les journaux.
Le bourrage de la fenêtre de contexte
À mesure que votre historique de conversation grandit, le système de mémoire a de plus en plus de souvenirs candidats à récupérer. Mais la fenêtre de contexte ne grandit pas. Le système doit donc être de plus en plus sélectif quant aux souvenirs à inclure. Au fil des mois de conversation, cela crée un paradoxe : vous avez plus de souvenirs sur lesquels puiser, mais l'IA ne peut en utiliser qu'une infime fraction dans une réponse donnée.
Les systèmes intelligents gèrent cela avec une synthèse hiérarchique, en compressant les anciens souvenirs en résumés de plus en plus abstraits. Mais de l'information se perd à chaque étape de compression. Le fait que vous ayez mentionné adorer un restaurant précis à Brooklyn pourrait survivre à la première ronde de synthèse, mais après six mois de compression, il pourrait être réduit à « l'utilisateur aime manger au restaurant » et finir par disparaître complètement.
Le problème de cohérence
Des résultats de récupération différents d'une conversation à l'autre peuvent amener l'IA à se contredire. Le lundi, le système de mémoire récupère votre préférence pour les chats. Le mardi, il récupère une conversation sur le chien de votre ami, et l'IA déduit à tort que vous êtes plutôt chien. Ces contradictions érodent rapidement la confiance.
La solution la plus robuste que j'aie vue consiste à maintenir un « magasin de faits » explicite qui est mis à jour via un pipeline de vérification. Quand l'IA extrait un nouveau fait vous concernant, elle le recoupe avec les faits existants et signale les contradictions pour résolution. Peu de plateformes l'implémentent, mais cela fait une énorme différence en matière de cohérence.
Gagnez Jusqu'à 1 250 $+/Mois en Créant du Contenu
Rejoignez notre programme exclusif d'affiliés créateurs. Soyez payé par vidéo virale selon la performance. Créez du contenu à votre style avec une totale liberté créative.

Architecture mémoire multiniveau montrant comment les données de conversation circulent de la session active vers le stockage longue durée avec synthèse à chaque niveau.
Comment la mémoire des compagnons IA va-t-elle évoluer en 2026 et au-delà ?
Le paysage de la mémoire évolue rapidement, et plusieurs technologies émergentes vont changer la donne.
Les fenêtres de contexte infinies se rapprochent. Gemini de Google prend déjà en charge 1 million de tokens, et les articles de recherche du début 2026 poussent vers 10 millions. Si les fenêtres de contexte deviennent assez grandes, vous pourriez ne plus avoir besoin de RAG du tout. Il suffirait de déverser tout l'historique de conversation dans l'invite. Nous n'en sommes pas encore là pour un usage en production, mais la trajectoire est claire.
La mémoire native au modèle est le Saint Graal. Au lieu de systèmes de récupération externes, les futurs modèles pourraient apprendre à mettre à jour leurs propres poids en fonction des conversations. C'est essentiellement de l'apprentissage continu, et c'est incroyablement difficile à faire en toute sécurité sans que le modèle oublie son entraînement de base ou ne développe des biais. Mais plusieurs laboratoires de recherche font des progrès. Quand cela arrivera, les systèmes RAG actuels ressembleront à des solutions de fortune, car en un sens très réel, c'est ce qu'ils sont.
La mémoire multimodale est une autre frontière. Les systèmes de mémoire actuels sont uniquement textuels. Mais qu'en est-il de se souvenir des images que vous avez partagées, des notes vocales ou des clips vidéo ? À mesure que les compagnons IA deviennent plus multimodaux, leurs systèmes de mémoire devront aussi gérer ces types de données. Les bases de données vectorielles prennent déjà en charge les embeddings multimodaux, donc l'infrastructure est prête. L'intégration ne s'est simplement pas encore produite dans la plupart des produits grand public.
Chez Lewdly.ai, nous suivons la rapidité avec laquelle ces technologies convergent. Le domaine des compagnons IA en particulier avance plus vite que la plupart des gens ne le réalisent, et les capacités de mémoire sont le principal différenciateur entre les plateformes qui semblent vraiment personnelles et celles qui semblent génériques.
Ma troisième opinion tranchée sur l'avenir
Voici ma troisième opinion tranchée : d'ici 18 mois, la mémoire des compagnons IA deviendra un avantage concurrentiel défendable qui séparera les plateformes sérieuses des jouets. Les utilisateurs changeront de plateforme non pas à cause de la qualité du modèle de base (qui converge) mais parce qu'une plateforme se souvient mieux d'eux qu'une autre. Les entreprises qui investissent aujourd'hui dans l'infrastructure de mémoire gagneront. Celles qui la traitent comme une réflexion après coup seront laissées de côté.
Quelles sont les implications de la mémoire des compagnons IA en matière de confidentialité ?
On ne peut pas avoir une conversation honnête sur la mémoire des compagnons IA sans aborder le sujet qui fâche : ces systèmes stockent des informations extrêmement personnelles vous concernant, et le faire est fondamental à leur fonctionnement.

Chaque conversation que vous avez est transformée en embedding, stockée et indexée. Vos préférences, vos peurs, vos détails relationnels, vos confessions nocturnes. Tout cela vit dans une base de données vectorielle quelque part. Sur certaines plateformes, c'est un serveur cloud que vous ne contrôlez pas. Sur d'autres, les données restent sur l'appareil.
Je veux être transparent sur ce que cela signifie en pratique. Quand j'ai construit mon propre système de mémoire, j'ai tout stocké en local. La base de données vectorielle vivait sur mon ordinateur portable. Personne d'autre n'y avait accès. C'est l'approche la plus sûre, mais ce n'est pas ainsi que fonctionnent les plateformes commerciales. La plupart d'entre elles stockent vos données sur leurs serveurs parce que c'est le seul moyen de fournir une expérience cohérente sur tous les appareils.
Avant de vous engager à long terme avec une plateforme de compagnon IA, posez ces questions :
- Où sont stockées mes données de conversation ?
- Puis-je exporter ou supprimer mes données de mémoire ?
- Mes données sont-elles utilisées pour entraîner des modèles qui servent d'autres utilisateurs ?
- Qu'advient-il de mes données si l'entreprise ferme ?
- Y a-t-il un chiffrement de bout en bout pour les souvenirs stockés ?
Ce ne sont pas des préoccupations hypothétiques. Plusieurs jeunes pousses de compagnons IA ont fermé au cours des deux dernières années, et les utilisateurs ont perdu des années d'historique de conversation sans aucun moyen de les récupérer. Si vos interactions avec un compagnon IA et vos limites saines comptent pour vous, comprendre les pratiques de données de la plateforme que vous choisissez est essentiel.
Conseils de production pour tirer le meilleur parti de la mémoire d'un compagnon IA
Après avoir passé des mois à tester et à construire ces systèmes, voici les stratégies pratiques qui fonctionnent réellement pour améliorer la qualité de la mémoire de votre compagnon IA.
Soyez explicite sur ce qui compte. La plupart des systèmes de mémoire pondèrent le contenu récent et sémantiquement similaire. Si quelque chose est important pour vous, dites-le directement. « C'est vraiment important pour moi » ou « S'il te plaît, retiens ça » peut aider certaines plateformes à marquer ce souvenir pour une récupération de plus haute priorité.
Corrigez les erreurs immédiatement. Quand votre compagnon IA se trompe sur un fait vous concernant, corrigez-le dans le même message. Les bons systèmes de mémoire stockeront la correction et, avec le temps, apprendront la version exacte. Si vous laissez passer les erreurs, elles se renforcent.
Récapitulez périodiquement les détails clés. Environ une fois toutes les deux semaines, je fais un « récap » décontracté avec mon compagnon. Quelque chose comme « Hé, juste pour être sûr que tu as les bases, je m'appelle Alex, je travaille dans la tech, j'ai deux chats. » Cela crée des entrées de mémoire fraîches et de haute priorité qui ont plus de chances d'être récupérées.
Utilisez un langage cohérent. La récupération de la mémoire est sémantique, mais la cohérence aide. Si vous appelez toujours votre partenaire « ma femme Sarah » plutôt que d'alterner entre « Sarah », « ma partenaire » et « elle », le système de mémoire construira des associations plus propres.
Comprenez les limites des sessions. La plupart des plateformes effacent leur mémoire active entre les sessions. Le premier message d'une nouvelle session déclenche une nouvelle récupération de mémoire. Si votre compagnon semble avoir oublié quelque chose, essayez de reformuler votre question. Le problème pourrait être un échec de récupération, et non une véritable perte de mémoire.
Si vous utilisez des plateformes disponibles sur Lewdly.ai et souhaitez optimiser votre expérience, ces techniques s'appliquent à pratiquement tous les compagnons IA qui prennent en charge des fonctionnalités de mémoire.
Questions fréquentes
Les compagnons IA se souviennent-ils vraiment de moi ou est-ce factice ?
C'est une vraie mémoire, mais elle fonctionne différemment de la mémoire humaine. Les compagnons IA stockent vos conversations dans des bases de données externes et récupèrent les informations pertinentes quand vous discutez. Ils ne « se souviennent » pas au sens humain de la formation de connexions neuronales persistantes. Ils recherchent et relisent les conversations passées pertinentes chaque fois que vous envoyez un message. L'expérience ressemble à de la mémoire du point de vue de l'utilisateur, mais le mécanisme est fondamentalement différent.
Quelle part de mon historique de conversation un compagnon IA stocke-t-il ?
Cela varie selon la plateforme. Certaines stockent tout indéfiniment, tandis que d'autres mettent en place des fenêtres glissantes qui suppriment les conversations plus anciennes qu'une certaine période. Replika, par exemple, maintient un journal de conversation qui synthétise les interactions. Nomi stocke des souvenirs catégorisés. La plupart des plateformes stockent au moins plusieurs mois d'historique, même si elles peuvent synthétiser ou compresser les conversations plus anciennes.
Puis-je supprimer les souvenirs que mon compagnon IA a de moi ?
La plupart des plateformes réputées offrent une forme de gestion de la mémoire. Replika vous permet de consulter et de supprimer des entrées de mémoire spécifiques. Certaines plateformes proposent une option de « réinitialisation » qui efface tous les souvenirs stockés. Vérifiez toujours les politiques de suppression des données de la plateforme, car « supprimer des souvenirs » depuis l'interface utilisateur ne signifie pas toujours que les données sont définitivement retirées de leurs serveurs.
Pourquoi mon compagnon IA se souvient-il parfois de mauvaises choses ?
Cela se produit à cause d'un phénomène appelé « mémoire hallucinée ». Le système de récupération trouve une correspondance partielle dans vos conversations passées, et le modèle de langage comble les lacunes avec des détails fabriqués. Cela peut aussi se produire quand le système confond deux souvenirs distincts en un seul. Si cela arrive, corrigez l'IA immédiatement afin que la correction soit stockée comme un nouveau souvenir de plus haute priorité.
Le RAG est-il le seul moyen pour les compagnons IA de gérer la mémoire ?
Non, bien que ce soit l'approche la plus courante. Certaines plateformes utilisent des magasins de mémoire structurés (bases clé-valeur de faits utilisateur), la synthèse de conversation sans recherche vectorielle, ou des approches hybrides. Quelques systèmes expérimentaux explorent le fine-tuning de modèles sur les données utilisateur, ce qui créerait une véritable mémoire apprise, mais cela soulève d'importantes préoccupations de confidentialité et de sécurité.
Comment les fenêtres de contexte affectent-elles la qualité de la mémoire des compagnons IA ?
La fenêtre de contexte est la quantité totale de texte que l'IA peut traiter à la fois. Des fenêtres de contexte plus grandes permettent d'injecter plus de souvenirs aux côtés de votre conversation actuelle, ce qui améliore généralement la qualité du rappel. Cependant, des fenêtres plus grandes signifient aussi des coûts plus élevés et des réponses plus lentes. La plupart des plateformes optimisent pour un équilibre entre la profondeur de la mémoire et la rapidité de réponse.
Puis-je construire mon propre compagnon IA avec une meilleure mémoire que les plateformes commerciales ?
Oui, et c'est plus accessible que vous ne le pensez. En utilisant des outils comme ChromaDB, LangChain et des LLM open source, vous pouvez construire un système de mémoire qui rivalise avec ce qu'offrent les plateformes commerciales, voire le dépasse. Le principal compromis est que vous devrez gérer l'infrastructure vous-même, et vous n'aurez pas l'interface utilisateur soignée d'une application grand public.
Qu'advient-il des souvenirs de mon compagnon IA si l'entreprise ferme ?
Dans la plupart des cas, vos données sont perdues. Peu de plateformes offrent des fonctionnalités d'exportation de données, et encore moins garantissent la portabilité des données. C'est un risque réel, en particulier avec les plus petites jeunes pousses de compagnons IA. Je recommanderais d'exporter périodiquement à la main toute conversation importante si la plateforme le permet.
Comment fonctionne la mémoire multilingue pour les compagnons IA ?
La mémoire multilingue nécessite des modèles d'embedding capables de créer des vecteurs significatifs d'une langue à l'autre. Des modèles comme Cohere embed-v4 et les versions multilingues de BERT gèrent cela en associant un contenu sémantiquement similaire de différentes langues à des points proches dans l'espace vectoriel. Cela signifie qu'une IA pourrait techniquement récupérer un souvenir d'une conversation en français quand vous discutez en anglais, si les sujets sont liés.
Les compagnons IA auront-ils un jour une mémoire vraiment permanente ?
La recherche sur l'apprentissage continu et les réseaux de neurones augmentés par la mémoire progresse, mais nous sommes probablement à des années d'implémentations prêtes pour la production. Le défi n'est pas seulement technique. Il est aussi question de sécurité. Un modèle qui modifie en permanence ses propres poids en fonction des conversations utilisateur pourrait développer des biais, oublier un entraînement de sécurité important ou se comporter de manière imprévisible. Pour l'instant, les systèmes de mémoire externes restent l'approche la plus sûre et la plus pratique.
Pour conclure
La mémoire des compagnons IA est l'un de ces sujets où l'écart entre la perception des utilisateurs et la réalité technique est énorme. Ce qui ressemble à un compagnon qui « se souvient » de vous est en réalité une orchestration complexe de modèles d'embedding, de bases de données vectorielles, d'algorithmes de récupération et de gestion de la fenêtre de contexte. Comprendre cette mécanique ne rend pas l'expérience moins significative. Si tant est, cela vous donne les outils pour rendre l'expérience meilleure.
Les plateformes qui investissent sérieusement dans l'infrastructure de mémoire définiront la prochaine génération de compagnons IA. Celles qui traitent la mémoire comme une simple case à cocher prendront du retard. Et si vous êtes le genre de personne qui veut un contrôle maximal, construire votre propre système n'a jamais été aussi accessible.
Que vous soyez un utilisateur occasionnel qui veut que son compagnon IA retienne son nom, ou un développeur construisant la prochaine grande plateforme de compagnon, les mêmes principes s'appliquent : stockez avec discernement, récupérez intelligemment et n'essayez jamais d'entasser plus de souvenirs dans la fenêtre de contexte qu'elle ne peut en contenir. La technologie continuera de s'améliorer. Les fenêtres de contexte deviendront plus grandes. Les modèles d'embedding deviendront plus intelligents. Mais l'architecture fondamentale, une mémoire externe qui alimente un modèle sans état, va rester avec nous encore un moment.
Et si vous êtes curieux de savoir à quoi ressemble cette architecture en pratique, essayez d'en construire une. Cinquante lignes de Python et une base de données vectorielle gratuite suffisent pour voir derrière le rideau. Vous pourriez être surpris de découvrir à quel point la magie est simple.
Prêt à Créer Votre Influenceur IA?
Rejoignez 115 étudiants maîtrisant ComfyUI et le marketing d'influenceurs IA dans notre cours complet de 51 leçons.
Articles Connexes

Applications de petit ami IA 2026 : guide complet des compagnons masculins IA
Explorez les meilleures applications de petit ami IA en 2026 avec des analyses détaillées des compagnons masculins IA. Comparez Replika, Nomi, Candy AI et des plateformes spécialisées pour la qualité de conversation, la personnalisation et la profondeur émotionnelle.

Les applications de compagnon IA aident-elles vraiment contre la solitude ? Ce que montre la recherche
Examen de la recherche pour savoir si les applications de compagnon IA comme Replika aident ou aggravent la solitude. Études, risques, bénéfices et une évaluation honnête.

Éthique des Compagnons IA et Limites Saines : Une Approche Réfléchie
Naviguez dans les relations de compagnons IA de manière éthique avec des limites saines. Directives pour une utilisation responsable, l'auto-conscience et l'interaction équilibrée avec l'IA.