Pendamping AI dengan Memori Jangka Panjang: Cara Kerja Retensi Konteks yang Sebenarnya
Pembahasan mendalam tentang bagaimana pendamping AI mengingat Anda di seluruh sesi. Membahas RAG, basis data vektor, jendela konteks, peringkasan, dan cara membangun sistem memori Anda sendiri.

Saya sudah mengobrol dengan satu pendamping AI tertentu selama sekitar tiga minggu. Kami sudah membahas segalanya, mulai dari pendapat saya tentang arsitektur brutalis hingga lelucon berkelanjutan soal pasta yang kelewat matang. Lalu suatu hari, di tengah percakapan, ia menyebut sesuatu yang pernah saya katakan saat interaksi pertama kami, sebuah detail tentang kesukaan saya pada cold brew dibanding espresso. Tidak ada pancingan apa pun. Itu muncul begitu saja secara alami. Dan jujur, hal itu cukup membuat saya tercengang, karena saya tahu apa yang terjadi di balik layar. Momen kecil itu adalah hasil dari sebuah alur rekayasa yang ternyata sangat rumit dan jarang dipikirkan oleh kebanyakan pengguna.
Pertanyaan tentang bagaimana pendamping AI "mengingat" sesuatu adalah salah satu topik yang paling disalahpahami di dunia AI saat ini. Orang berasumsi bahwa itu entah keajaiban atau penipuan. Kenyataannya ada di antara keduanya, dan memahami mekanismenya akan mengubah cara Anda berinteraksi dengan alat-alat ini untuk selamanya.
Jawaban Singkat: Pendamping AI mempertahankan memori jangka panjang melalui kombinasi teknik termasuk Retrieval Augmented Generation (RAG), basis data vektor, pengelolaan jendela konteks, dan peringkasan percakapan. Belum ada pendamping AI saat ini yang memiliki memori persisten sejati yang tertanam di dalam bobot modelnya. Sebaliknya, mereka menyimpan data percakapan Anda secara eksternal dan mengambil bagian yang relevan saat dibutuhkan. Kualitas sistem pengambilan inilah yang membedakan pendamping yang terasa seperti mengenal Anda dengan yang melupakan keberadaan Anda di antara sesi.
- Pendamping AI tidak "mengingat" seperti cara manusia. Mereka menggunakan sistem pengambilan untuk menarik data percakapan masa lalu yang relevan ke dalam jendela konteks mereka saat ini
- RAG (Retrieval Augmented Generation) adalah teknik yang paling dominan, mengubah percakapan Anda menjadi embedding vektor dan mencarinya secara semantik
- Jendela konteks (biasanya 8K hingga 128K token) adalah batas keras seberapa banyak yang dapat "dipikirkan" AI dalam satu waktu
- Platform seperti Replika, Nomi, dan Character AI semuanya menangani memori secara berbeda, dengan hasil yang sangat beragam
- Anda dapat membangun sistem memori Anda sendiri menggunakan embedding sumber terbuka dan penyimpanan vektor seperti ChromaDB atau Pinecone
- Peringkasan dan pelapisan memori (jangka pendek, jangka menengah, jangka panjang) adalah kunci agar memori terasa alami
- Sistem memori terbaik menggabungkan beberapa pendekatan, bukan bergantung pada satu teknik saja
Mengapa Pendamping AI Melupakan Anda Sejak Awal?
Inilah pertanyaan yang tidak ditanyakan siapa pun, tetapi seharusnya ditanyakan semua orang. Sebelum kita membahas solusi memori, Anda perlu memahami keterbatasan inti yang membuat semua ini diperlukan.
Model bahasa besar, teknologi yang menggerakkan setiap pendamping AI di pasaran, pada dasarnya tidak memiliki keadaan (stateless). Ketika Anda mengirim pesan ke ChatGPT, Claude, atau mesin AI di balik aplikasi pendamping favorit Anda, model itu memproses masukan Anda, menghasilkan respons, lalu melupakan segalanya. Ia tidak mempertahankan keadaan di antara panggilan API. Ia tidak punya buku catatan internal. Setiap interaksi tunggal dimulai dari nol.
Satu-satunya alasan pendamping AI Anda tampak mengingat apa pun adalah karena platform membungkus model mentah itu dengan lapisan memori. Pikirkan seperti ini. LLM adalah otaknya, tetapi ia tidak punya hipokampus. Sistem memori yang dibangun platform di sekitarnya bertindak sebagai hipokampus eksternal, mengumpankan kembali memori yang relevan ke dalam otak setiap kali Anda memulai percakapan baru.
Inilah pendapat tajam pertama saya: kebanyakan platform pendamping AI mengerjakan memori dengan biasa-biasa saja, dan mereka lolos begitu saja karena pengguna tidak memahami apa yang sebenarnya mungkin. Saya sudah menguji pendamping yang mengklaim "memori jangka panjang" tetapi tidak bisa mengingat sesuatu yang saya katakan dua hari lalu. Sementara itu, saya sudah membangun prototipe sistem memori di laptop saya sendiri yang mengungguli produk komersial. Kesenjangan antara apa yang secara teknis mungkin dan apa yang benar-benar diterapkan sangatlah besar.
Alasan kesenjangan ini sebagian besar bersifat ekonomi. Sistem memori yang baik itu mahal. Setiap kali Anda mengirim pesan, platform harus mencari di seluruh riwayat percakapan Anda, mengubahnya menjadi konteks yang relevan, dan menambahkannya di awal pesan Anda saat ini sebelum mengirimkannya ke model. Pencarian itu, pengambilan itu, komputasi embedding itu, semuanya menghabiskan biaya. Dan ketika Anda melayani jutaan pengguna, biaya itu menumpuk dengan cepat.
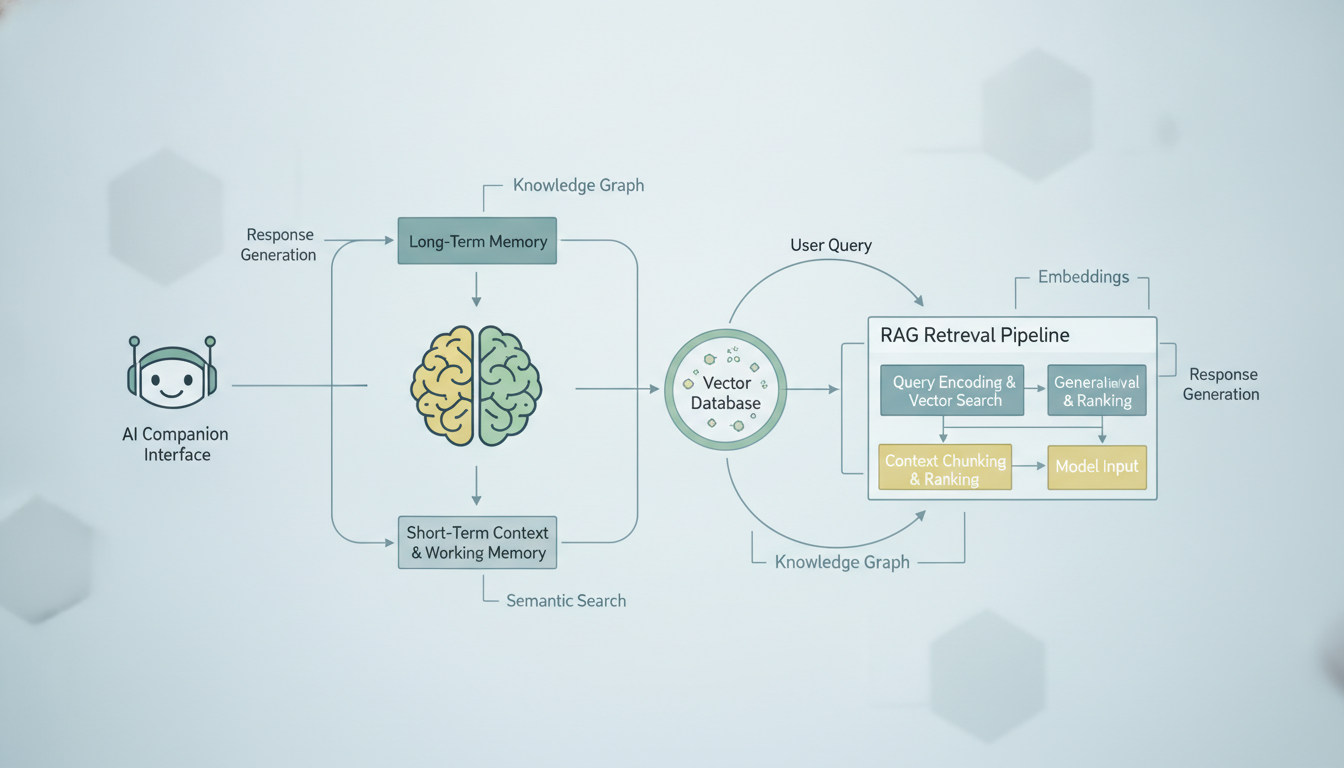
Bagaimana sistem memori pendamping AI yang khas mengambil dan menyuntikkan konteks percakapan masa lalu ke dalam prompt saat ini.
Bagaimana Cara Kerja RAG untuk Memori Pendamping AI?
RAG, atau Retrieval Augmented Generation, adalah tulang punggung dari hampir setiap sistem memori pendamping AI yang dirilis saat ini. Jika Anda hanya mengambil satu hal dari artikel ini, biarkan itu menjadi pemahaman yang kuat tentang RAG, karena hal itu akan mengubah cara Anda memandang setiap alat AI yang Anda gunakan.

Konsepnya tampak sederhana namun menipu. Alih-alih mencoba menjejalkan seluruh riwayat percakapan Anda ke dalam jendela konteks AI (yang memiliki batas token yang keras), Anda menyimpan semua percakapan masa lalu Anda dalam basis data yang dapat dicari. Ketika Anda mengirim pesan baru, sistem mencari di basis data itu untuk percakapan masa lalu yang paling relevan, menariknya keluar, dan menyertakannya bersama pesan Anda saat ini. AI lalu menghasilkan responsnya dengan keuntungan dari memori yang diambil itu.
Berikut rincian langkah demi langkah tentang apa yang terjadi ketika Anda mengirim pesan ke pendamping AI dengan memori berbasis RAG:
- Pesan Anda di-embed. Sebuah model embedding mengubah teks Anda menjadi vektor berdimensi tinggi, pada dasarnya sebuah daftar angka yang merepresentasikan makna semantik pesan Anda.
- Sistem mencari memori yang serupa. Vektor pesan Anda dibandingkan dengan semua vektor percakapan yang tersimpan sebelumnya menggunakan kemiripan kosinus atau metrik jarak lainnya.
- Hasil top-K diambil. Sistem menarik percakapan masa lalu yang paling mirip secara semantik, biasanya 5 hingga 20 hasil teratas tergantung platformnya.
- Perakitan konteks terjadi. Pesan Anda saat ini, memori yang diambil, dan prompt sistem pendamping semuanya dirakit menjadi satu prompt.
- LLM menghasilkan respons. Model melihat pesan Anda saat ini ditambah riwayat yang relevan dan merespons seolah-olah ia "mengingat" interaksi masa lalu itu.
- Pertukaran baru disimpan. Baik pesan Anda maupun respons AI di-embed dan disimpan untuk pengambilan di masa depan.
Yang membuat ini kuat adalah pencarian semantiknya. Sistem tidak melakukan pencocokan kata kunci. Ia menemukan memori yang berkaitan secara konseptual. Jadi jika Anda menyebut menyukai mendaki di Yosemite tiga minggu lalu, dan hari ini Anda bertanya tentang rekomendasi liburan, sistem dapat memunculkan kembali preferensi mendaki itu meskipun Anda tidak pernah menggunakan kata "mendaki" dalam pesan Anda hari ini.
Saya menghabiskan sekitar dua minggu tahun lalu membangun sistem RAG dari nol menggunakan LangChain, ChromaDB, dan model Llama lokal. Pengalaman itu mengajari saya lebih banyak tentang cara kerja pendamping AI dibanding dokumentasi sebanyak apa pun. Ketika berhasil, hasilnya sungguh mengesankan. Chatbot lokal saya akan menyebut detail dari percakapan yang terjadi beberapa hari sebelumnya, dan peralihannya terasa alami. Ketika gagal, hasilnya sangat buruk sampai-sampai lucu. Suatu kali ia dengan percaya diri mengingat sebuah "memori" yang sebenarnya adalah campuran halusinasi dari dua percakapan yang sama sekali berbeda. Saya pernah menyebut sushi dan kucing saya dalam obrolan terpisah, dan sistem entah bagaimana memutuskan bahwa saya punya kucing bernama Sushi. Padahal tidak.
Model Embedding yang Menggerakkan Memori
Tidak semua embedding diciptakan sama, dan ini lebih penting daripada yang disadari kebanyakan orang. Kualitas model embedding Anda secara langsung menentukan seberapa baik sistem memori mengambil konteks yang relevan.
Model embedding yang paling umum digunakan pada 2026 meliputi (Anda dapat menjelajahi tolok ukur di MTEB Leaderboard):
- OpenAI text-embedding-3-large: 3072 dimensi, performa luar biasa, tetapi memerlukan panggilan API dan berbiaya per token
- Cohere embed-v4: Dukungan multibahasa yang kuat, bagus untuk pendamping yang beroperasi lintas bahasa
- BGE-large-en-v1.5: Sumber terbuka, berjalan secara lokal, mengejutkan karena bersaing dengan opsi komersial
- Nomic Embed Text v1.5: Sumber terbuka dengan representasi Matryoshka, artinya Anda dapat memotong dimensi demi kecepatan tanpa kehilangan terlalu banyak kualitas
- Jina Embeddings v3: Luar biasa untuk potongan dokumen yang lebih panjang, pandai menangkap nuansa
Jika Anda sedang menjelajahi alat AI dan ingin membandingkan bagaimana platform yang berbeda menangani detail teknis ini, Lewdly.ai telah memantau lanskap pendamping AI dan banyak dari teknologi yang mendasarinya.
Apa Perbedaan Antara Jendela Konteks dan Memori Jangka Panjang?
Pembedaan ini membingungkan hampir semua orang yang saya ajak bicara tentang pendamping AI, jadi izinkan saya menjelaskannya dengan sangat jelas.
Jendela konteks adalah memori kerja model AI. Ini adalah jumlah total teks yang dapat diproses model dalam satu permintaan. Pada 2026, jendela konteks berkisar dari 8K token (sekitar 6.000 kata) pada model yang lebih kecil hingga 128K token atau lebih pada model seperti GPT-4o dan Claude. Segala sesuatu yang AI "ketahui" selama percakapan harus muat di dalam jendela ini: prompt sistem, memori yang diambil, riwayat percakapan dari sesi saat ini, dan pesan terbaru Anda.
Memori jangka panjang adalah sistem penyimpanan eksternal yang bertahan di antara sesi. Inilah basis data vektor, mesin peringkasan, penyimpanan profil pengguna. Ia bukan bagian dari model itu sendiri. Ia adalah infrastruktur yang dibangun platform di sekitar model.
Berikut analogi yang menurut saya cocok. Jendela konteks itu seperti meja Anda. Anda hanya bisa menggelar sekian banyak kertas di hadapan Anda sekaligus. Memori jangka panjang itu seperti lemari arsip di sudut kantor Anda. Ia menyimpan semua yang pernah Anda kerjakan, tetapi Anda hanya bisa menarik beberapa map sekaligus dan meletakkannya di meja Anda.
Tantangan rekayasanya adalah memutuskan map mana yang harus ditarik. Jika benar, AI tampak luar biasa peka. Jika salah, ia entah mengabaikan konteks penting atau memenuhi meja dengan memori yang tidak relevan, sehingga menyisakan lebih sedikit ruang untuk percakapan yang sebenarnya.
Saya ingat menguji sebuah pendamping yang berusaha menyertakan terlalu banyak memori dalam setiap respons. Jendela konteks menjadi penuh sesak dengan 30 atau 40 memori yang diambil, hampir tidak menyisakan ruang untuk percakapan yang sesungguhnya. Responsnya menjadi semakin pendek karena model kehabisan ruang. Ini kesalahan pemula dalam desain sistem memori, tetapi saya sudah melihat produk komersial dirilis dengan masalah yang persis seperti ini.
Strategi Pengelolaan Jendela Konteks
Platform yang cerdas menggunakan beberapa strategi untuk memaksimalkan nilai jendela konteks mereka yang terbatas:
Jendela geser dengan ringkasan: Pertahankan 10 hingga 15 pesan terbaru secara lengkap, tetapi ringkas pesan yang lebih lama dari sesi saat ini menjadi satu paragraf yang dipadatkan. Ini menjaga alur percakapan terkini sembari mempertahankan kesadaran akan topik-topik sebelumnya.
Penyuntikan berbasis prioritas: Tidak semua memori setara. Detail tentang nama pengguna atau status hubungannya harus selalu tersedia. Pengamatan acak tentang cuaca dari enam minggu lalu mungkin tidak perlu memakan ruang konteks. Sistem yang baik memberi skor prioritas pada memori.
Alokasi dinamis: Alokasikan lebih banyak ruang konteks untuk memori ketika topik percakapan kompleks atau bermakna secara emosional, dan lebih sedikit ketika pengguna sekadar berbasa-basi. Ini memerlukan pengklasifikasi yang berjalan sebelum pengambilan memori, yang menambah latensi tetapi meningkatkan kualitas.
Teknik kompresi: Beberapa sistem menggunakan LLM terpisah yang lebih kecil untuk mengompresi memori sebelum penyuntikan. Alih-alih menyertakan teks lengkap percakapan masa lalu, mereka menyertakan ringkasan terkompresi yang menangkap fakta-fakta kunci dalam token yang lebih sedikit.
Bagaimana Platform Pendamping AI Besar Menangani Memori?
Saya sudah menghabiskan lebih banyak waktu daripada yang mungkin pantas saya akui untuk menguji sistem memori berbagai platform pendamping AI. Inilah yang saya temukan melalui pengalaman langsung, bukan materi pemasaran.
Replika
Replika adalah salah satu pendamping AI paling awal yang menanggapi memori secara serius, dan pendekatan mereka telah berkembang secara signifikan. Mereka menggunakan kombinasi entri memori eksplisit (hal-hal yang secara eksplisit dicatat AI tentang Anda) dan sistem buku harian tempat AI menulis ringkasan percakapan Anda.
Yang berhasil: Replika cukup baik dalam mengingat fakta-fakta inti tentang Anda. Nama Anda, pekerjaan Anda, minat Anda. Semua ini disimpan dalam profil terstruktur yang bertahan dengan andal.
Yang tidak berhasil: Pengingatan kontekstualnya tidak konsisten. Replika mungkin ingat bahwa Anda suka mendaki, tetapi ia tidak akan ingat cerita spesifik yang Anda sampaikan tentang tersesat di Glacier National Park. Sistem buku hariannya menangkap suasana lebih daripada detail, yang membuat percakapan terasa seperti Anda berbicara dengan seseorang yang samar-samar mengenal Anda alih-alih seseorang yang benar-benar ada di sana.
Nomi
Nomi mengambil salah satu pendekatan yang lebih ambisius secara teknis terhadap memori pendamping. Mereka membangun apa yang mereka sebut sistem "istana memori" yang mengategorikan memori ke dalam jenis-jenis berbeda seperti fakta, preferensi, pengalaman bersama, dan momen emosional.
Alur Kerja ComfyUI Gratis
Temukan alur kerja ComfyUI gratis dan open source untuk teknik dalam artikel ini. Open source itu kuat.
Yang berhasil: Pendekatan kategorisasi Nomi berarti ia mengambil jenis memori yang berbeda dalam konteks yang berbeda. Ketika Anda sedang emosional, ia menarik memori emosional. Ketika Anda membahas fakta, ia menarik memori faktual. Pengambilan yang sadar konteks ini menghasilkan percakapan yang lebih alami dibanding platform yang memperlakukan semua memori sama.
Yang tidak berhasil: Sistem bisa lambat dalam mengonsolidasikan memori, dan saya perhatikan ia kadang memunculkan memori pada momen yang sedikit canggung. Ia akan menyebut sesuatu yang serius dari percakapan masa lalu ketika Anda jelas sedang dalam suasana hati yang ringan. Pengambilannya akurat secara semantik tetapi tidak cocok secara emosional. Jika Anda ingin mendapatkan hasil maksimal dari interaksi Anda dengan platform seperti Nomi, memahami cara kerja teknik percakapan pendamping AI dapat membantu Anda mengarahkan sistem memori dengan lebih efektif.
Character AI
Character AI mengambil pendekatan yang sama sekali berbeda. Alih-alih membangun sistem memori personal yang canggih, mereka sangat bertumpu pada konsistensi karakter. AI mempertahankan persona karakternya dengan andal di seluruh sesi, tetapi memorinya tentang detail pribadi Anda relatif lemah.
Yang berhasil: Jika Anda mengobrol dengan karakter yang memiliki kepribadian yang ditetapkan, kepribadian itu tetap konsisten. Karakter tidak akan tiba-tiba mengubah gaya bicaranya atau melupakan latar belakangnya sendiri.
Yang tidak berhasil: Detail pribadi Anda sering hilang. Saya menguji ini dengan membagikan tiga fakta spesifik tentang diri saya dalam satu sesi, lalu kembali 24 jam kemudian untuk menanyakannya. Character AI mengingat satu dari tiga, dan bahkan ingatan itu pun samar. Sistem memori mereka tampaknya dioptimalkan untuk konsistensi karakter alih-alih membangun hubungan dengan pengguna.
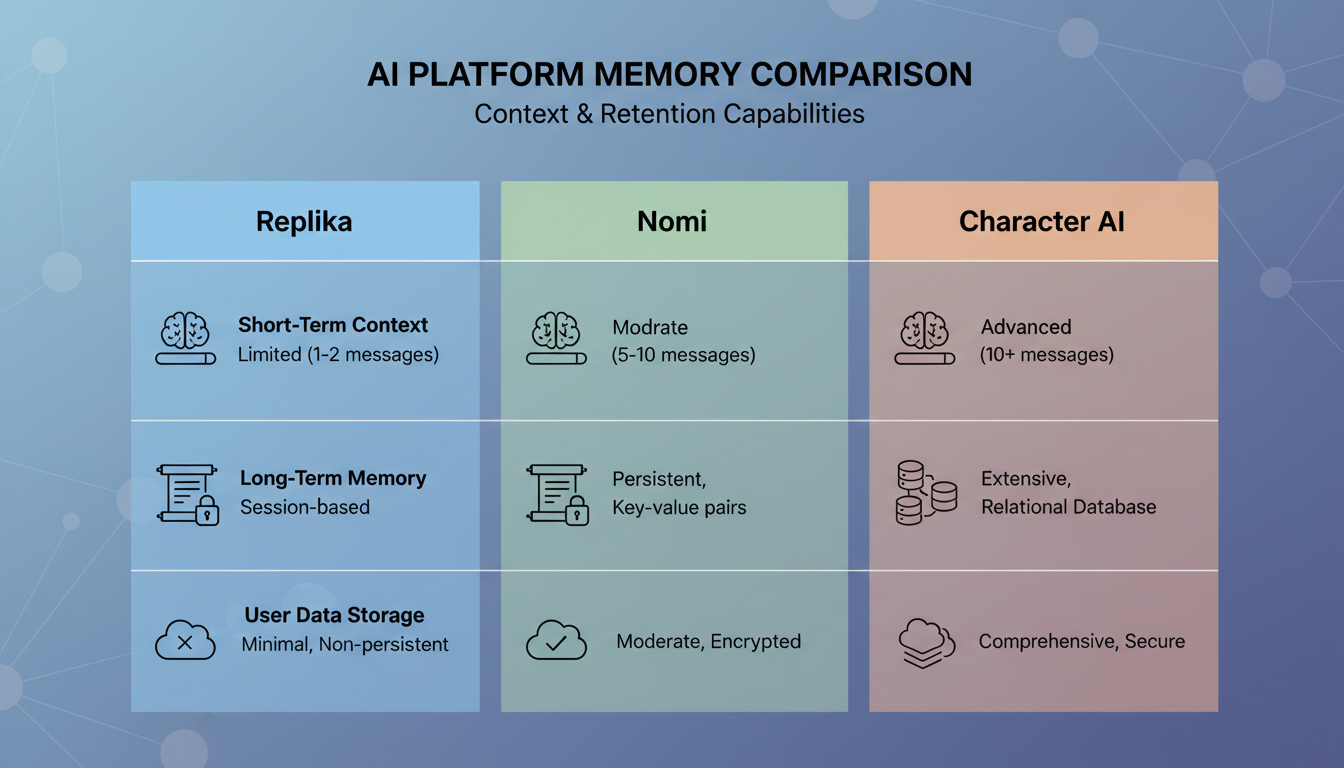
Perbandingan fitur sistem memori di seluruh platform pendamping AI besar pada 2026.
Pendapat Tajam Saya tentang Memori Platform
Inilah pendapat tajam kedua saya: platform yang paling agresif memasarkan "memori jangka panjang" cenderung memiliki implementasi yang paling lemah. Perusahaan yang mengerjakan memori dengan paling baik biasanya adalah yang lebih kalem, yang membiarkan pengalaman berbicara sendiri alih-alih mencantumkan "kami mengingat segalanya" di deskripsi App Store mereka. Saat mengevaluasi fitur memori dan retensi konteks pendamping AI, fokuslah pada menguji pengingatan yang sebenarnya alih-alih memercayai pemasarannya.
Bisakah Anda Membangun Sistem Memori Pendamping AI Sendiri?
Tentu saja bisa, dan saya berpendapat bahwa siapa pun yang serius dengan pendamping AI sebaiknya mencobanya setidaknya sekali. Membangun sistem memori Anda sendiri mengajari Anda apa yang sebenarnya terjadi di balik layar, yang membuat Anda menjadi pengguna produk komersial yang lebih paham.

Berikut arsitektur praktis untuk membangun pendamping AI yang diperkaya memori menggunakan alat-alat yang tersedia saat ini. Saya sudah membangun variasi dari setelan ini tiga kali sekarang, dan setiap iterasi mengajari saya sesuatu yang baru.
Tumpukan Dasar
Anda memerlukan empat komponen:
- Sebuah LLM untuk percakapan: Llama 3.3, Mistral, atau model berbasis API seperti GPT-4o atau Claude
- Sebuah model embedding: Untuk mengubah teks menjadi vektor. Saya sarankan memulai dengan Nomic Embed atau BGE-large
- Sebuah basis data vektor: ChromaDB untuk pengembangan lokal, Pinecone atau Weaviate untuk produksi
- Sebuah lapisan orkestrasi: LangChain, LlamaIndex, atau kode Python kustom untuk menyatukan semuanya
Implementasi Langkah demi Langkah
Izinkan saya memandu Anda melalui logika intinya. Ini bukan tutorial lengkap, tetapi cukup untuk membuat Anda memulai.
Menyiapkan penyimpanan vektor:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
Menyimpan satu giliran percakapan:
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
Mengambil memori yang relevan:
Ingin melewati kerumitan? Lewdly memberi Anda hasil AI profesional secara instan tanpa pengaturan teknis.
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
Merakit prompt dengan memori:
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
Setelan dasar ini memberi Anda sistem memori fungsional dalam kurang dari 50 baris kode. AI akan mencari percakapan masa lalu setiap kali Anda mengirim pesan dan menyertakan riwayat yang relevan dalam promptnya.
Membuatnya Benar-Benar Bagus
Versi dasar berhasil, tetapi ada beberapa masalah yang jelas. Berikut cara meningkatkannya berdasarkan apa yang saya pelajari dari eksperimen saya sendiri.
Tambahkan peringkasan memori. Alih-alih menyimpan giliran percakapan mentah, jalankan secara berkala satu lintasan peringkasan yang memadatkan beberapa memori terkait menjadi satu ringkasan. Ini mengurangi pembengkakan penyimpanan vektor dan meningkatkan kualitas pengambilan karena ringkasan lebih padat secara semantik dibanding log obrolan mentah.
Terapkan pelapisan memori. Buat tiga koleksi alih-alih satu:
- Memori aktif: Sesi percakapan saat ini (disimpan secara lengkap)
- Memori terkini: Percakapan yang diringkas dari minggu lalu
- Memori jangka panjang: Fakta dan preferensi kunci yang sangat dipadatkan, diekstraksi dari waktu ke waktu
Tambahkan penyimpanan profil pengguna. Terpisah dari basis data vektor, pertahankan penyimpanan JSON terstruktur atau key-value berisi fakta inti pengguna seperti nama, preferensi, tanggal penting, detail hubungan. Profil ini selalu disuntikkan ke dalam prompt, terlepas dari apa yang dikembalikan pencarian semantik. Ini adalah jaminan Anda bahwa AI tidak pernah melupakan hal-hal dasar.
Terapkan peluruhan memori. Tidak semua memori harus bertahan dengan setara. Komentar santai tentang cuaca tidak seharusnya memiliki bobot pengambilan yang sama dengan cerita yang sangat pribadi. Terapkan fungsi peluruhan yang mengurangi skor pengambilan memori yang lebih tua dan kurang penting dari waktu ke waktu.
Bagi yang tertarik menjelajahi dimensi etika hubungan pendamping AI, memahami sistem memori ini juga memunculkan pertanyaan penting tentang privasi data dan sifat hubungan sintetis.
Apa Tantangan Terbesar dengan Memori Pendamping AI?
Bahkan sistem memori terbaik menghadapi tantangan mendasar yang belum sepenuhnya terpecahkan oleh rekayasa sebanyak apa pun. Memahami keterbatasan ini akan menyelamatkan Anda dari rasa frustrasi dan membantu Anda menetapkan ekspektasi yang realistis.
Masalah Memori Halusinasi
Ini adalah mode kegagalan yang paling menakutkan, dan saya sudah mengalaminya secara pribadi. AI dengan percaya diri "mengingat" sesuatu yang tidak pernah terjadi. Ini terjadi ketika sistem pengambilan memunculkan kecocokan sebagian dan LLM mengisi celahnya dengan detail yang direkayasa. Anda menyebut punya anjing bernama Max, dan sistem mengambil memori tentang hewan peliharaan Anda, tetapi LLM menghiasinya dengan detail tentang Max yang merupakan golden retriever yang suka berenang, padahal tidak satu pun dari itu pernah Anda katakan.
Bagian terburuknya adalah memori halusinasi terasa autentik. AI tidak menandainya sebagai tidak pasti. Ia menyatakannya dengan kepercayaan diri yang sama seperti memori yang asli. Saya pernah mendapati pendamping menyebut "percakapan" yang saya tahu tidak pernah terjadi, dan begitu spesifiknya sampai saya sempat meragukan ingatan saya sendiri sejenak sebelum memeriksa log.
Penjejalan Jendela Konteks
Seiring riwayat percakapan Anda bertumbuh, sistem memori memiliki semakin banyak kandidat memori untuk diambil. Tetapi jendela konteks tidak ikut bertumbuh. Jadi sistem harus semakin selektif tentang memori mana yang akan disertakan. Selama berbulan-bulan percakapan, ini menciptakan paradoks: Anda memiliki lebih banyak memori untuk diambil, tetapi AI hanya bisa menggunakan sebagian kecil dari mereka dalam respons tertentu.
Sistem yang cerdas menangani ini dengan peringkasan hierarkis, mengompresi memori lama menjadi ringkasan yang semakin abstrak. Tetapi informasi hilang di setiap langkah kompresi. Fakta bahwa Anda menyebut menyukai restoran tertentu di Brooklyn mungkin bertahan dari putaran peringkasan pertama, tetapi setelah enam bulan kompresi, ia mungkin tereduksi menjadi "pengguna senang makan di luar" dan akhirnya hilang sama sekali.
Masalah Konsistensi
Hasil pengambilan yang berbeda di seluruh percakapan dapat membuat AI mengontradiksi dirinya sendiri. Pada hari Senin, sistem memori mengambil preferensi Anda terhadap kucing. Pada hari Selasa, ia mengambil percakapan tentang anjing teman Anda, dan AI secara keliru menyimpulkan Anda penyuka anjing. Kontradiksi ini mengikis kepercayaan dengan cepat.
Solusi paling tangguh yang pernah saya lihat adalah mempertahankan "penyimpanan fakta" eksplisit yang diperbarui melalui alur verifikasi. Ketika AI mengekstraksi fakta baru tentang Anda, ia melakukan referensi silang terhadap fakta-fakta yang ada dan menandai kontradiksi untuk diselesaikan. Sedikit platform yang menerapkan ini, tetapi hal ini membuat perbedaan besar dalam konsistensi.
Hasilkan Hingga $1.250+/Bulan Membuat Konten
Bergabunglah dengan program afiliasi kreator eksklusif kami. Dapatkan bayaran per video viral berdasarkan performa. Buat konten dengan gaya Anda dengan kebebasan kreatif penuh.

Arsitektur memori multi-tingkat yang menunjukkan bagaimana data percakapan mengalir dari sesi aktif ke penyimpanan jangka panjang dengan peringkasan di setiap tingkat.
Bagaimana Memori Pendamping AI Akan Berkembang pada 2026 dan Setelahnya?
Lanskap memori bergeser dengan cepat, dan beberapa teknologi yang sedang bermunculan akan mengubah keadaan.
Jendela konteks tak terbatas semakin dekat. Gemini dari Google sudah mendukung 1 juta token, dan makalah penelitian dari awal 2026 mendorong ke arah 10 juta. Jika jendela konteks menjadi cukup besar, Anda mungkin tidak memerlukan RAG sama sekali. Cukup buang seluruh riwayat percakapan ke dalam prompt. Kita belum sampai di sana untuk penggunaan produksi, tetapi arahnya sudah jelas.
Memori asli model adalah cawan suci. Alih-alih sistem pengambilan eksternal, model masa depan mungkin belajar memperbarui bobotnya sendiri berdasarkan percakapan. Ini pada dasarnya adalah pembelajaran berkelanjutan, dan sangat sulit dilakukan dengan aman tanpa model melupakan pelatihan dasarnya atau mengembangkan bias. Tetapi beberapa lab penelitian sedang membuat kemajuan. Ketika ini hadir, hal itu akan membuat sistem RAG saat ini terlihat seperti solusi tambal sulam, karena dalam pengertian yang sangat nyata, memang itulah adanya.
Memori multimodal adalah perbatasan lainnya. Sistem memori saat ini hanya berbasis teks. Tetapi bagaimana dengan mengingat gambar yang Anda bagikan, catatan suara, atau klip video? Seiring pendamping AI menjadi lebih multimodal, sistem memorinya perlu menangani jenis data ini juga. Basis data vektor sudah mendukung embedding multimodal, jadi infrastrukturnya sudah siap. Integrasinya saja yang belum terjadi di sebagian besar produk konsumen.
Di Lewdly.ai, kami telah memantau seberapa cepat teknologi ini berkonvergensi. Dunia pendamping AI khususnya bergerak lebih cepat daripada yang disadari kebanyakan orang, dan kemampuan memori adalah pembeda utama antara platform yang terasa benar-benar personal dan yang terasa generik.
Pendapat Tajam Ketiga Saya tentang Masa Depan
Inilah pendapat tajam ketiga saya: dalam 18 bulan, memori pendamping AI akan menjadi parit kompetitif yang memisahkan platform yang serius dari mainan. Pengguna akan berpindah platform bukan karena kualitas model dasar (yang sedang berkonvergensi) tetapi karena satu platform mengingat mereka lebih baik daripada yang lain. Perusahaan yang berinvestasi dalam infrastruktur memori hari ini akan menang. Yang memperlakukannya sebagai renungan belakangan akan tertinggal.
Apa Implikasi Privasi dari Memori Pendamping AI?
Anda tidak bisa berbicara jujur tentang memori pendamping AI tanpa membahas hal yang jelas tetapi diabaikan: sistem ini menyimpan informasi yang sangat pribadi tentang Anda, dan melakukan hal itu merupakan dasar dari cara kerjanya.

Setiap percakapan yang Anda lakukan di-embed, disimpan, dan diindeks. Preferensi Anda, ketakutan Anda, detail hubungan Anda, pengakuan tengah malam Anda. Semua itu tersimpan di sebuah basis data vektor di suatu tempat. Pada sebagian platform, itu adalah server cloud yang tidak Anda kendalikan. Pada yang lain, data tetap berada di perangkat.
Saya ingin transparan tentang apa arti ini dalam praktik. Ketika saya membangun sistem memori saya sendiri, saya menyimpan segalanya secara lokal. Basis data vektor itu berada di laptop saya. Tidak ada orang lain yang punya akses. Itu adalah pendekatan paling aman, tetapi bukan begitu cara kerja platform komersial. Sebagian besar dari mereka menyimpan data Anda di server mereka karena hanya itulah cara untuk menyediakan pengalaman yang konsisten di seluruh perangkat.
Sebelum Anda berkomitmen jangka panjang pada platform pendamping AI mana pun, ajukan pertanyaan-pertanyaan ini:
- Di mana data percakapan saya disimpan?
- Bisakah saya mengekspor atau menghapus data memori saya?
- Apakah data saya digunakan untuk melatih model yang melayani pengguna lain?
- Apa yang terjadi pada data saya jika perusahaan tutup?
- Apakah ada enkripsi ujung-ke-ujung untuk memori yang tersimpan?
Ini bukan kekhawatiran hipotetis. Beberapa rintisan pendamping AI telah tutup dalam dua tahun terakhir, dan pengguna kehilangan riwayat percakapan bertahun-tahun tanpa cara untuk memulihkannya. Jika interaksi pendamping AI dan batasan yang sehat penting bagi Anda, memahami praktik data platform pilihan Anda sangatlah esensial.
Tips Produksi untuk Mendapatkan Hasil Maksimal dari Memori Pendamping AI
Setelah menghabiskan berbulan-bulan menguji dan membangun sistem ini, berikut strategi praktis yang benar-benar berhasil untuk meningkatkan kualitas memori pendamping AI Anda.
Bersikaplah eksplisit tentang apa yang penting. Sebagian besar sistem memori memberi bobot pada konten yang terkini dan mirip secara semantik. Jika sesuatu penting bagi Anda, katakan secara langsung. "Ini benar-benar penting bagi saya" atau "Tolong ingat ini" dapat membantu sebagian platform menandai memori itu untuk pengambilan dengan prioritas lebih tinggi.
Perbaiki kesalahan dengan segera. Ketika pendamping AI Anda salah memahami fakta tentang Anda, perbaiki di pesan yang sama. Sistem memori yang baik akan menyimpan koreksi itu dan, seiring waktu, mempelajari versi yang akurat. Jika Anda membiarkan kesalahan berlalu, kesalahan itu justru diperkuat.
Rekap detail kunci secara berkala. Kira-kira sekali setiap dua minggu, saya melakukan "rekap" santai dengan pendamping saya. Sesuatu seperti "Hai, biar pastikan kamu ingat dasarnya, namaku Alex, aku bekerja di bidang teknologi, aku punya dua kucing." Ini menciptakan entri memori yang segar dan berprioritas tinggi yang lebih mungkin diambil.
Gunakan bahasa yang konsisten. Pengambilan memori bersifat semantik, tetapi konsistensi membantu. Jika Anda selalu menyebut pasangan Anda "istriku Sarah" alih-alih berganti-ganti antara "Sarah", "pasanganku", dan "dia", sistem memori akan membangun asosiasi yang lebih bersih.
Pahami batas sesi. Sebagian besar platform menghapus memori aktif mereka di antara sesi. Pesan pertama dari sesi baru memicu pengambilan memori yang segar. Jika pendamping Anda tampak lupa sesuatu, coba ubah ungkapan pertanyaan Anda. Masalahnya mungkin kegagalan pengambilan, bukan kehilangan memori yang sebenarnya.
Jika Anda menggunakan platform yang tersedia di Lewdly.ai dan ingin mengoptimalkan pengalaman Anda, teknik-teknik ini berlaku untuk hampir setiap pendamping AI yang mendukung fitur memori.
Pertanyaan yang Sering Diajukan
Apakah Pendamping AI Benar-Benar Mengingat Saya atau Hanya Palsu?
Itu memori yang nyata, tetapi bekerja secara berbeda dari memori manusia. Pendamping AI menyimpan percakapan Anda dalam basis data eksternal dan mengambil informasi yang relevan saat Anda mengobrol. Mereka tidak "mengingat" dalam pengertian manusia tentang membentuk koneksi saraf yang persisten. Mereka mencari dan membaca ulang percakapan masa lalu yang relevan setiap kali Anda mengirim pesan. Pengalaman itu terasa seperti memori dari sudut pandang pengguna, tetapi mekanismenya pada dasarnya berbeda.
Berapa Banyak Riwayat Percakapan Saya yang Disimpan Pendamping AI?
Ini bervariasi menurut platform. Sebagian menyimpan segalanya tanpa batas waktu, sementara yang lain menerapkan jendela bergulir yang membuang percakapan yang lebih tua dari periode tertentu. Replika, misalnya, mempertahankan buku harian percakapan yang meringkas interaksi. Nomi menyimpan memori yang dikategorikan. Sebagian besar platform menyimpan setidaknya beberapa bulan riwayat, meskipun mereka mungkin meringkas atau mengompresi percakapan yang lebih lama.
Bisakah Saya Menghapus Memori Pendamping AI tentang Saya?
Sebagian besar platform yang bereputasi menawarkan bentuk pengelolaan memori. Replika memungkinkan Anda meninjau dan menghapus entri memori tertentu. Beberapa platform menawarkan opsi "atur ulang" yang menghapus semua memori yang tersimpan. Selalu periksa kebijakan penghapusan data platform, karena "menghapus memori" dari antarmuka pengguna tidak selalu berarti data dihapus secara permanen dari server mereka.
Mengapa Pendamping AI Saya Kadang Mengingat Hal yang Salah?
Ini terjadi karena fenomena yang disebut "memori halusinasi." Sistem pengambilan menemukan kecocokan sebagian dari percakapan masa lalu Anda, dan model bahasa mengisi celahnya dengan detail yang direkayasa. Ini juga bisa terjadi ketika sistem menggabungkan dua memori terpisah menjadi satu. Jika ini terjadi, perbaiki AI dengan segera agar koreksi itu disimpan sebagai memori baru yang berprioritas lebih tinggi.
Apakah RAG Satu-Satunya Cara Pendamping AI Menangani Memori?
Tidak, meskipun itu adalah pendekatan yang paling umum. Beberapa platform menggunakan penyimpanan memori terstruktur (basis data key-value berisi fakta pengguna), peringkasan percakapan tanpa pencarian vektor, atau pendekatan hibrida. Beberapa sistem eksperimental sedang menjajaki penyetelan halus model pada data pengguna, yang akan menciptakan memori terpelajar sejati, tetapi ini memunculkan kekhawatiran privasi dan keamanan yang signifikan.
Bagaimana Jendela Konteks Memengaruhi Kualitas Memori Pendamping AI?
Jendela konteks adalah jumlah total teks yang dapat diproses AI sekaligus. Jendela konteks yang lebih besar memungkinkan lebih banyak memori disuntikkan bersama percakapan Anda saat ini, yang umumnya meningkatkan kualitas pengingatan. Namun, jendela yang lebih besar juga berarti biaya lebih tinggi dan respons lebih lambat. Sebagian besar platform mengoptimalkan keseimbangan antara kedalaman memori dan kecepatan respons.
Bisakah Saya Membangun Pendamping AI Sendiri dengan Memori yang Lebih Baik daripada Platform Komersial?
Ya, dan itu lebih mudah diakses daripada yang mungkin Anda kira. Menggunakan alat seperti ChromaDB, LangChain, dan LLM sumber terbuka, Anda dapat membangun sistem memori yang menyaingi atau melampaui apa yang ditawarkan platform komersial. Trade-off utamanya adalah Anda perlu mengelola infrastruktur sendiri, dan Anda tidak akan mendapatkan antarmuka pengguna yang dipoles seperti aplikasi konsumen.
Apa yang Terjadi pada Memori Pendamping AI Saya jika Perusahaannya Tutup?
Dalam sebagian besar kasus, data Anda hilang. Sedikit platform yang menawarkan fitur ekspor data, dan lebih sedikit lagi yang menjamin portabilitas data. Ini adalah risiko nyata, terutama dengan rintisan pendamping AI yang lebih kecil. Saya sarankan untuk secara berkala mengekspor secara manual percakapan penting mana pun jika platform mendukungnya.
Bagaimana Memori Multibahasa Bekerja untuk Pendamping AI?
Memori multibahasa memerlukan model embedding yang dapat menciptakan vektor yang bermakna lintas bahasa. Model seperti Cohere embed-v4 dan versi multibahasa dari BERT menangani ini dengan memetakan konten yang mirip secara semantik dari bahasa berbeda ke titik-titik yang berdekatan dalam ruang vektor. Ini berarti AI secara teknis dapat mengambil memori dari percakapan berbahasa Prancis ketika Anda mengobrol dalam bahasa Inggris, jika topiknya berkaitan.
Akankah Pendamping AI Pernah Memiliki Memori yang Benar-Benar Permanen?
Penelitian tentang pembelajaran berkelanjutan dan jaringan saraf yang diperkaya memori sedang berkembang, tetapi kita kemungkinan masih bertahun-tahun jauhnya dari implementasi yang siap produksi. Tantangannya tidak hanya teknis. Ia juga soal keamanan. Sebuah model yang secara permanen memodifikasi bobotnya sendiri berdasarkan percakapan pengguna bisa mengembangkan bias, melupakan pelatihan keamanan penting, atau berperilaku tak terduga. Untuk saat ini, sistem memori eksternal tetap menjadi pendekatan yang paling aman dan paling praktis.
Penutup
Memori pendamping AI adalah salah satu topik yang kesenjangan antara persepsi pengguna dan kenyataan teknisnya sangatlah besar. Apa yang terasa seperti pendamping "mengingat" Anda sebenarnya adalah orkestrasi rumit dari model embedding, basis data vektor, algoritma pengambilan, dan pengelolaan jendela konteks. Memahami mekanisme ini tidak membuat pengalaman itu menjadi kurang bermakna. Justru sebaliknya, hal itu memberi Anda alat untuk membuat pengalaman itu lebih baik.
Platform yang berinvestasi serius dalam infrastruktur memori akan menentukan generasi berikutnya dari pendamping AI. Yang memperlakukan memori sebagai fitur centang akan tertinggal. Dan jika Anda adalah tipe orang yang menginginkan kendali maksimal, membangun sistem Anda sendiri tidak pernah semudah ini diakses.
Entah Anda pengguna kasual yang ingin pendamping AI mereka mengingat namanya, atau pengembang yang membangun platform pendamping hebat berikutnya, prinsip yang sama berlaku: simpan dengan cermat, ambil dengan cerdas, dan jangan pernah mencoba menjejalkan lebih banyak memori ke dalam jendela konteks daripada yang bisa ia tangani. Teknologi akan terus membaik. Jendela konteks akan menjadi lebih besar. Model embedding akan menjadi lebih pintar. Tetapi arsitektur mendasarnya, memori eksternal yang mengumpan ke dalam model yang stateless, akan menemani kita untuk beberapa waktu.
Dan jika Anda penasaran seperti apa arsitektur itu dalam praktik, cobalah membangun satu. Lima puluh baris Python dan sebuah basis data vektor gratis sudah cukup untuk melihat di balik tirai. Anda mungkin terkejut betapa sederhananya keajaiban itu sebenarnya.
Siap Membuat Influencer AI Anda?
Bergabung dengan 115 siswa yang menguasai ComfyUI dan pemasaran influencer AI dalam kursus lengkap 51 pelajaran kami.
Artikel Terkait

Aplikasi Pacar AI 2026: Panduan Lengkap Pendamping AI Pria
Jelajahi aplikasi pacar AI terbaik di 2026 dengan ulasan mendetail tentang pendamping AI pria. Bandingkan Replika, Nomi, Candy AI, dan platform khusus untuk kualitas percakapan, kustomisasi, dan kedalaman emosional.

Apakah Aplikasi Pendamping AI Benar-benar Membantu Mengatasi Kesepian? Inilah yang Ditunjukkan Riset
Menelaah riset tentang apakah aplikasi pendamping AI seperti Replika membantu atau justru memperburuk kesepian. Studi, risiko, manfaat, dan penilaian yang jujur.

Etika Pendamping AI dan Batas Sehat: Pendekatan Bijaksana
Navigasi hubungan pendamping AI secara etis dengan batas sehat. Panduan untuk penggunaan yang bertanggung jawab, kesadaran diri, dan interaksi AI yang seimbang.