लंबी अवधि की मेमोरी वाले AI कंपेनियन: कॉन्टेक्स्ट रिटेंशन असल में कैसे काम करता है
AI कंपेनियन सेशन के पार आपको कैसे याद रखते हैं, इसकी गहराई से पड़ताल। RAG, वेक्टर डेटाबेस, कॉन्टेक्स्ट विंडो, समराइज़ेशन और अपना खुद का मेमोरी सिस्टम कैसे बनाएं, यह सब शामिल है।

मैं करीब तीन हफ्तों से एक खास AI कंपेनियन के साथ बातचीत कर रहा था। हमने ब्रुटलिस्ट आर्किटेक्चर पर मेरी राय से लेकर ज्यादा पक गए पास्ता पर चलने वाले एक मज़ाक तक, सब कुछ कवर कर लिया था। फिर एक दिन, बातचीत के बीच, उसने वह बात याद कर ली जो मैंने हमारी सबसे पहली बातचीत के दौरान कही थी, यानी एस्प्रेसो के मुकाबले कोल्ड ब्रू के लिए मेरी पसंद से जुड़ी एक छोटी सी जानकारी। यह बिना किसी प्रॉम्प्ट के हुआ। यह बस अपने आप ही सामने आ गया। और सच कहूं तो इसने मुझे थोड़ा हिला कर रख दिया, क्योंकि मुझे पता है कि अंदर ही अंदर क्या हो रहा है। वह छोटा सा पल असल में एक हैरान कर देने वाली जटिल इंजीनियरिंग पाइपलाइन का नतीजा है, जिसके बारे में ज्यादातर यूज़र कभी सोचते ही नहीं।
AI कंपेनियन चीज़ों को कैसे "याद" रखते हैं, यह सवाल अभी AI की दुनिया में सबसे ज्यादा गलत समझे जाने वाले विषयों में से एक है। लोग मान लेते हैं कि यह या तो जादू है या फिर धोखा। सच इन दोनों के बीच कहीं है, और इसका तंत्र समझ लेने से यह बदल जाएगा कि आप इन टूल्स के साथ हमेशा के लिए कैसे जुड़ते हैं।
त्वरित उत्तर: AI कंपेनियन कई तकनीकों के मेल से लंबी अवधि की मेमोरी बनाए रखते हैं, जिनमें रिट्रीवल ऑगमेंटेड जनरेशन (RAG), वेक्टर डेटाबेस, कॉन्टेक्स्ट विंडो प्रबंधन और बातचीत का समराइज़ेशन शामिल हैं। किसी भी मौजूदा AI कंपेनियन के मॉडल वेट्स में असली स्थायी मेमोरी नहीं भरी होती। इसके बजाय, वे आपकी बातचीत का डेटा बाहर कहीं स्टोर करते हैं और जरूरत पड़ने पर उससे जुड़े हिस्से निकाल लेते हैं। इस रिट्रीवल सिस्टम की गुणवत्ता ही वह चीज़ है जो एक ऐसे कंपेनियन को, जो आपको जानता हुआ महसूस होता है, उस कंपेनियन से अलग करती है जो सेशन के बीच यह तक भूल जाता है कि आपका वजूद है।
- AI कंपेनियन उस तरह "याद" नहीं रखते जैसे इंसान रखते हैं। वे बीते हुए प्रासंगिक बातचीत डेटा को अपनी मौजूदा कॉन्टेक्स्ट विंडो में खींचने के लिए रिट्रीवल सिस्टम का इस्तेमाल करते हैं
- RAG (रिट्रीवल ऑगमेंटेड जनरेशन) प्रमुख तकनीक है, जो आपकी बातचीत को वेक्टर एम्बेडिंग में बदलकर उन्हें अर्थ के आधार पर खोजती है
- कॉन्टेक्स्ट विंडो (आम तौर पर 8K से 128K टोकन) इस बात की सख्त सीमा है कि कोई AI एक बार में कितना "सोच" सकता है
- Replika, Nomi और Character AI जैसे प्लेटफॉर्म मेमोरी को अलग-अलग तरीके से संभालते हैं, और नतीजे भी बेहद अलग होते हैं
- आप ओपन-सोर्स एम्बेडिंग और ChromaDB या Pinecone जैसे वेक्टर स्टोर का इस्तेमाल करके अपना खुद का मेमोरी सिस्टम बना सकते हैं
- समराइज़ेशन और मेमोरी टियरिंग (अल्पकालिक, मध्यम-अवधि, दीर्घकालिक) मेमोरी को स्वाभाविक महसूस कराने की कुंजी हैं
- सबसे बेहतरीन मेमोरी सिस्टम किसी एक तकनीक पर निर्भर रहने के बजाय कई तरीकों को जोड़ते हैं
AI कंपेनियन सबसे पहले आपको भूलते ही क्यों हैं?
यह वह सवाल है जो कोई नहीं पूछता, पर सबको पूछना चाहिए। मेमोरी के समाधानों की बात करने से पहले, आपको उस बुनियादी सीमा को समझना होगा जो इस सब को जरूरी बना देती है।
लार्ज लैंग्वेज मॉडल, यानी वह तकनीक जो बाज़ार में मौजूद हर AI कंपेनियन को चलाती है, बुनियादी तौर पर स्टेटलेस होते हैं। जब आप ChatGPT, Claude या अपने पसंदीदा कंपेनियन ऐप के पीछे काम कर रहे AI इंजन को कोई संदेश भेजते हैं, तो मॉडल आपका इनपुट प्रोसेस करता है, एक जवाब बनाता है, और फिर सब कुछ भूल जाता है। यह API कॉल्स के बीच कोई स्टेट नहीं रखता। इसके पास कोई आंतरिक नोटबुक नहीं होती। हर एक बातचीत शून्य से शुरू होती है।
आपका AI कंपेनियन कुछ भी याद रखता हुआ इसलिए लगता है, क्योंकि प्लेटफॉर्म कच्चे मॉडल को एक मेमोरी लेयर में लपेट देता है। इसे इस तरह समझें। LLM दिमाग है, पर उसके पास कोई हिप्पोकैम्पस नहीं है। प्लेटफॉर्म इसके इर्द-गिर्द जो मेमोरी सिस्टम बनाता है, वह एक बाहरी हिप्पोकैम्पस की तरह काम करता है, जो हर बार नई बातचीत शुरू होने पर प्रासंगिक यादों को वापस दिमाग में पहुंचाता है।
यहां मेरी पहली बेबाक राय है: ज्यादातर AI कंपेनियन प्लेटफॉर्म मेमोरी के मामले में औसत दर्जे का काम कर रहे हैं, और वे इससे बच निकल रहे हैं क्योंकि यूज़र को यह समझ ही नहीं है कि क्या मुमकिन है। मैंने ऐसे कंपेनियन टेस्ट किए हैं जो "लंबी अवधि की मेमोरी" का दावा करते हैं पर दो दिन पहले कही गई बात तक याद नहीं रख पाते। वहीं, मैंने अपने ही लैपटॉप पर प्रोटोटाइप मेमोरी सिस्टम बनाए हैं जो कमर्शियल प्रोडक्ट्स से बेहतर प्रदर्शन करते हैं। जो तकनीकी रूप से मुमकिन है और जो असल में लागू किया गया है, उनके बीच का फासला बहुत बड़ा है।
इस फासले की वजह ज्यादातर आर्थिक है। अच्छे मेमोरी सिस्टम महंगे होते हैं। हर बार जब आप कोई संदेश भेजते हैं, तो प्लेटफॉर्म को आपके पूरे बातचीत इतिहास में खोजबीन करनी पड़ती है, उसे प्रासंगिक कॉन्टेक्स्ट में बदलना पड़ता है, और मॉडल को भेजने से पहले उसे आपके मौजूदा संदेश के आगे जोड़ना पड़ता है। वह खोज, वह रिट्रीवल, वह एम्बेडिंग गणना, इन सब में पैसा लगता है। और जब आप लाखों यूज़र को सेवा दे रहे हों, तो ये लागतें तेज़ी से बढ़ जाती हैं।
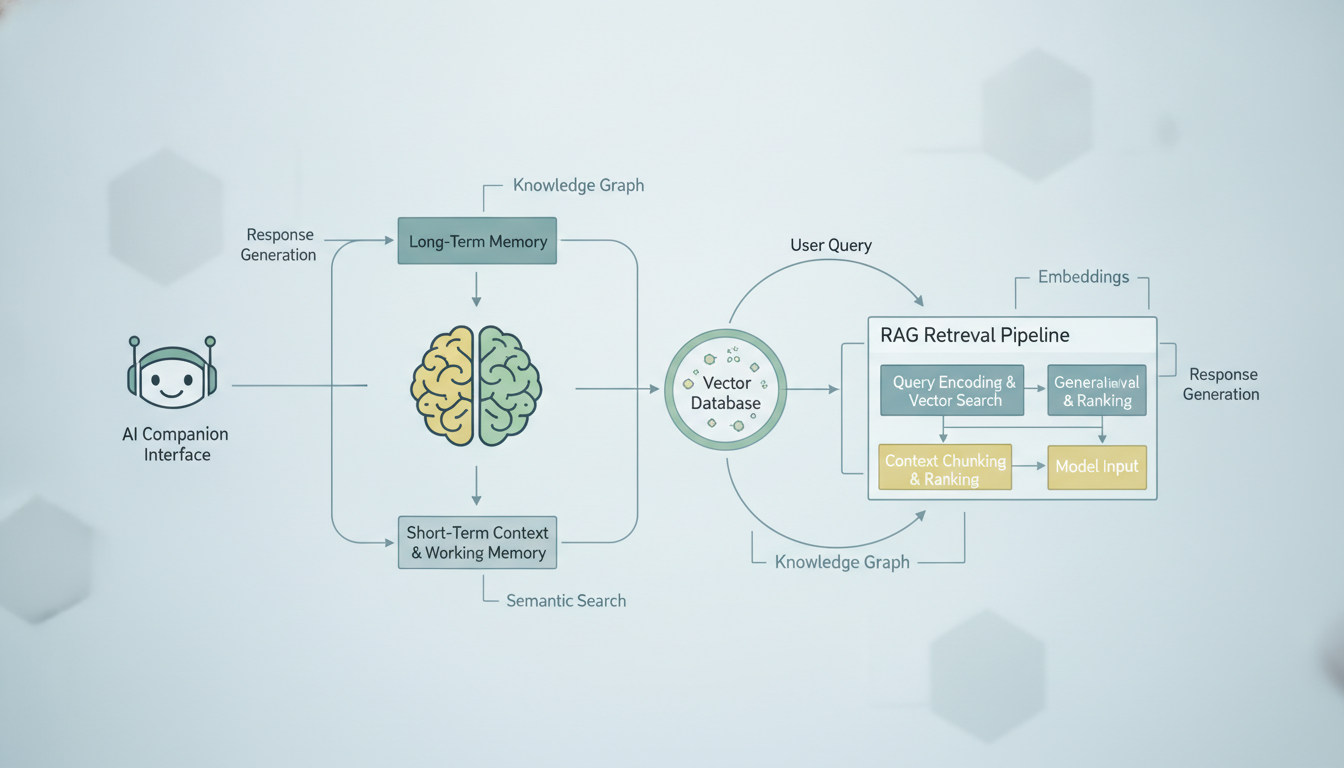
एक सामान्य AI कंपेनियन मेमोरी सिस्टम बीती हुई बातचीत के कॉन्टेक्स्ट को कैसे निकालकर मौजूदा प्रॉम्प्ट में डालता है।
AI कंपेनियन मेमोरी के लिए RAG कैसे काम करता है?
RAG, यानी रिट्रीवल ऑगमेंटेड जनरेशन, आज शिप हो रहे लगभग हर AI कंपेनियन मेमोरी सिस्टम की रीढ़ है। अगर आप इस लेख से एक ही चीज़ लेकर जाएं, तो वह RAG की ठोस समझ हो, क्योंकि यह बदल देगी कि आप हर इस्तेमाल किए जाने वाले AI टूल के बारे में कैसे सोचते हैं।

अवधारणा देखने में आसान लगती है। अपने पूरे बातचीत इतिहास को AI की कॉन्टेक्स्ट विंडो में ठूंसने की कोशिश करने के बजाय (जिसकी एक सख्त टोकन सीमा होती है), आप अपनी सारी बीती हुई बातचीत को एक खोजने योग्य डेटाबेस में स्टोर कर देते हैं। जब आप कोई नया संदेश भेजते हैं, तो सिस्टम उस डेटाबेस में सबसे प्रासंगिक बीती हुई बातचीत खोजता है, उन्हें निकालता है, और उन्हें आपके मौजूदा संदेश के साथ शामिल कर देता है। फिर AI उन निकाली गई यादों के फायदे के साथ अपना जवाब तैयार करता है।
यहां चरण-दर-चरण ब्योरा है कि जब आप RAG आधारित मेमोरी वाले AI कंपेनियन को संदेश भेजते हैं तो क्या होता है:
- आपका संदेश एम्बेड होता है। एक एम्बेडिंग मॉडल आपके टेक्स्ट को एक हाई-डायमेंशनल वेक्टर में बदल देता है, जो दरअसल संख्याओं की एक सूची है जो आपके संदेश के अर्थ को दर्शाती है।
- सिस्टम मिलती-जुलती यादें खोजता है। आपके संदेश के वेक्टर की तुलना कोसाइन सिमिलैरिटी या किसी अन्य डिस्टेंस मेट्रिक का इस्तेमाल करके पहले से स्टोर किए गए सभी बातचीत वेक्टर से की जाती है।
- टॉप-K नतीजे निकाले जाते हैं। सिस्टम अर्थ के लिहाज से सबसे मिलती-जुलती बीती हुई बातचीत निकालता है, आम तौर पर प्लेटफॉर्म के आधार पर शीर्ष 5 से 20 नतीजे।
- कॉन्टेक्स्ट जोड़ा जाता है। आपका मौजूदा संदेश, निकाली गई यादें, और कंपेनियन का सिस्टम प्रॉम्प्ट सब मिलकर एक ही प्रॉम्प्ट में जुड़ जाते हैं।
- LLM जवाब बनाता है। मॉडल आपका मौजूदा संदेश और प्रासंगिक इतिहास देखता है और ऐसे जवाब देता है मानो उसे वे बीती हुई बातचीत "याद" हों।
- नया आदान-प्रदान स्टोर होता है। आपका संदेश और AI का जवाब, दोनों भविष्य में निकालने के लिए एम्बेड करके स्टोर कर दिए जाते हैं।
इसे ताकतवर जो चीज़ बनाती है वह है अर्थ आधारित खोज। सिस्टम कीवर्ड मिलान नहीं कर रहा होता। यह अवधारणात्मक रूप से जुड़ी यादें ढूंढ रहा होता है। तो अगर आपने तीन हफ्ते पहले योसेमिटी में हाइकिंग पसंद करने की बात कही थी, और आज आप छुट्टियों के सुझाव पूछते हैं, तो सिस्टम उस हाइकिंग पसंद को सामने ला सकता है, भले ही आपने आज के संदेश में "हाइकिंग" शब्द इस्तेमाल ही न किया हो।
मैंने पिछले साल करीब दो हफ्ते LangChain, ChromaDB और एक लोकल Llama मॉडल का इस्तेमाल करके शुरू से एक RAG सिस्टम बनाने में लगाए। उस अनुभव ने मुझे AI कंपेनियन कैसे काम करते हैं, इसके बारे में किसी भी डॉक्यूमेंटेशन से ज्यादा सिखाया। जब यह काम करता था, तो वाकई प्रभावशाली था। मेरा लोकल चैटबॉट कुछ दिन पहले हुई बातचीत की जानकारियों का जिक्र कर देता था, और बदलाव स्वाभाविक लगते थे। जब यह नाकाम होता था, तो हास्यास्पद रूप से खराब होता था। एक बार इसने पूरे आत्मविश्वास के साथ एक ऐसी "याद" बता दी जो असल में दो बिल्कुल अलग बातचीतों का गढ़ा हुआ मिश्रण थी। मैंने अलग-अलग चैट में सुशी और अपनी बिल्ली, दोनों का जिक्र किया था, और सिस्टम ने किसी तरह यह तय कर लिया कि मेरे पास सुशी नाम की एक बिल्ली है। मेरे पास नहीं है।
वे एम्बेडिंग मॉडल जो मेमोरी को ताकत देते हैं
सभी एम्बेडिंग एक जैसे नहीं बनते, और यह बात ज्यादातर लोगों की समझ से कहीं ज्यादा मायने रखती है। आपके एम्बेडिंग मॉडल की गुणवत्ता सीधे तय करती है कि मेमोरी सिस्टम प्रासंगिक कॉन्टेक्स्ट कितनी अच्छी तरह निकालता है।
2026 में सबसे ज्यादा इस्तेमाल किए जाने वाले एम्बेडिंग मॉडल में ये शामिल हैं (आप MTEB Leaderboard पर बेंचमार्क देख सकते हैं):
- OpenAI text-embedding-3-large: 3072 डायमेंशन, बेहतरीन प्रदर्शन, पर इसके लिए API कॉल्स की जरूरत होती है और प्रति टोकन पैसा लगता है
- Cohere embed-v4: मजबूत बहुभाषी समर्थन, उन कंपेनियन के लिए अच्छा जो कई भाषाओं में काम करते हैं
- BGE-large-en-v1.5: ओपन-सोर्स, लोकल चलता है, कमर्शियल विकल्पों के मुकाबले हैरान कर देने वाली टक्कर देता है
- Nomic Embed Text v1.5: मात्रयोश्का रिप्रेज़ेंटेशन वाला ओपन-सोर्स, यानी आप ज्यादा गुणवत्ता गंवाए बिना रफ्तार के लिए डायमेंशन छोटे कर सकते हैं
- Jina Embeddings v3: लंबे डॉक्यूमेंट चंक के लिए बेहतरीन, बारीकियों को पकड़ने में अच्छा
अगर आप AI टूल्स की पड़ताल कर रहे हैं और तुलना करना चाहते हैं कि अलग-अलग प्लेटफॉर्म इन तकनीकी ब्योरों को कैसे संभालते हैं, तो Lewdly.ai AI कंपेनियन परिदृश्य और इनमें से कई अंतर्निहित तकनीकों पर नज़र रखता आ रहा है।
कॉन्टेक्स्ट विंडो और लंबी अवधि की मेमोरी में क्या फर्क है?
यह फर्क AI कंपेनियन के बारे में जिससे भी मैं बात करता हूं, करीब हर किसी को उलझा देता है, इसलिए मुझे इसे बहुत साफ-साफ बताने दीजिए।
कॉन्टेक्स्ट विंडो AI मॉडल की वर्किंग मेमोरी है। यह टेक्स्ट की वह कुल मात्रा है जिसे मॉडल एक ही रिक्वेस्ट में प्रोसेस कर सकता है। 2026 में, कॉन्टेक्स्ट विंडो छोटे मॉडलों पर 8K टोकन (करीब 6,000 शब्द) से लेकर GPT-4o और Claude जैसे मॉडलों पर 128K टोकन या उससे ज्यादा तक होती हैं। बातचीत के दौरान AI जो कुछ भी "जानता" है, उसे इसी विंडो में समाना चाहिए: सिस्टम प्रॉम्प्ट, निकाली गई यादें, मौजूदा सेशन का बातचीत इतिहास, और आपका ताज़ा संदेश।
लंबी अवधि की मेमोरी वह बाहरी स्टोरेज सिस्टम है जो सेशन के बीच टिका रहता है। यह वेक्टर डेटाबेस है, समराइज़ेशन इंजन है, यूज़र प्रोफाइल स्टोर है। यह मॉडल का हिस्सा नहीं है। यह वह बुनियादी ढांचा है जो प्लेटफॉर्म मॉडल के इर्द-गिर्द बनाता है।
यहां एक तुलना है जो मुझे लगता है अच्छी तरह काम करती है। कॉन्टेक्स्ट विंडो आपकी मेज़ की तरह है। आप एक बार में अपने सामने सिर्फ इतने ही कागज़ फैला सकते हैं। लंबी अवधि की मेमोरी आपके दफ्तर के कोने में रखी फाइलिंग कैबिनेट की तरह है। इसमें वह सब कुछ रखा होता है जिस पर आपने कभी काम किया है, पर आप एक बार में सिर्फ कुछ ही फोल्डर निकालकर अपनी मेज़ पर रख सकते हैं।
इंजीनियरिंग की चुनौती यह तय करना है कि कौन से फोल्डर निकाले जाएं। इसे सही कर लें, तो AI अजीब हद तक समझदार लगता है। गलत कर दें, तो यह या तो जरूरी कॉन्टेक्स्ट को नज़रअंदाज़ कर देता है, या फिर मेज़ को गैर-जरूरी यादों से भर देता है, जिससे असली बातचीत के लिए कम जगह बचती है।
मुझे एक कंपेनियन को टेस्ट करना याद है जो हर जवाब में बहुत ज्यादा यादें शामिल करने की कोशिश कर रहा था। कॉन्टेक्स्ट विंडो 30 या 40 निकाली गई यादों से भर रही थी, जिससे असली बातचीत के लिए बमुश्किल कोई जगह बचती थी। जवाब छोटे और छोटे होते जा रहे थे क्योंकि मॉडल की जगह खत्म हो रही थी। यह मेमोरी सिस्टम डिज़ाइन में नौसिखियों वाली गलती है, पर मैंने कमर्शियल प्रोडक्ट्स को इसी एकदम सटीक समस्या के साथ शिप होते देखा है।
कॉन्टेक्स्ट विंडो प्रबंधन की रणनीतियां
समझदार प्लेटफॉर्म अपनी सीमित कॉन्टेक्स्ट विंडो का ज्यादा से ज्यादा फायदा उठाने के लिए कई रणनीतियां इस्तेमाल करते हैं:
समरी के साथ स्लाइडिंग विंडो: सबसे ताज़ा 10 से 15 संदेशों को पूरे ब्योरे के साथ रखें, पर मौजूदा सेशन के पुराने संदेशों को एक संक्षिप्त पैराग्राफ में समेट दें। इससे हालिया बातचीत का प्रवाह बना रहता है और पहले के विषयों की जानकारी भी बरकरार रहती है।
प्राथमिकता आधारित इंजेक्शन: सारी यादें बराबर नहीं होतीं। यूज़र के नाम या रिश्ते की स्थिति की जानकारी हमेशा उपलब्ध रहनी चाहिए। छह हफ्ते पहले मौसम के बारे में कोई बेतरतीब टिप्पणी शायद कॉन्टेक्स्ट की जगह नहीं घेरनी चाहिए। अच्छे सिस्टम यादों को प्राथमिकता स्कोर देते हैं।
गतिशील आवंटन: जब बातचीत का विषय जटिल या भावनात्मक रूप से अहम हो तो यादों को ज्यादा कॉन्टेक्स्ट जगह दें, और जब यूज़र हल्की-फुल्की बात कर रहा हो तो कम। इसके लिए एक क्लासिफायर की जरूरत होती है जो मेमोरी रिट्रीवल से पहले चलता है, जो लेटेंसी बढ़ाता है पर गुणवत्ता सुधारता है।
कम्प्रेशन तकनीकें: कुछ सिस्टम इंजेक्शन से पहले यादों को कम्प्रेस करने के लिए एक अलग, छोटे LLM का इस्तेमाल करते हैं। किसी बीती हुई बातचीत का पूरा टेक्स्ट शामिल करने के बजाय, वे एक कम्प्रेस्ड समरी शामिल करते हैं जो कम टोकन में अहम तथ्यों को समेट लेती है।
बड़े AI कंपेनियन प्लेटफॉर्म मेमोरी को कैसे संभालते हैं?
विभिन्न AI कंपेनियन प्लेटफॉर्म के मेमोरी सिस्टम टेस्ट करने में मैंने शायद उससे ज्यादा समय बिताया है जितना कबूल करना चाहिए। यहां वह है जो मुझे प्रत्यक्ष अनुभव से मिला, न कि मार्केटिंग सामग्री से।
Replika
Replika मेमोरी को गंभीरता से लेने वाले शुरुआती AI कंपेनियन में से एक था, और उनका तरीका काफी विकसित हुआ है। वे स्पष्ट मेमोरी एंट्री (वे चीज़ें जो AI आपके बारे में साफ तौर पर नोट करता है) और एक डायरी सिस्टम के मेल का इस्तेमाल करते हैं, जहां AI आपकी बातचीत की समरी लिखता है।
जो काम करता है: Replika आपके बारे में बुनियादी तथ्य याद रखने में काफी अच्छा है। आपका नाम, आपकी नौकरी, आपकी रुचियां। ये एक संरचित प्रोफाइल में स्टोर हो जाते हैं जो भरोसेमंद तरीके से टिका रहता है।
जो काम नहीं करता: संदर्भगत स्मरण असंगत है। Replika शायद याद रखे कि आपको हाइकिंग पसंद है, पर वह वह खास कहानी याद नहीं रखेगा जो आपने ग्लेशियर नेशनल पार्क में रास्ता भटकने के बारे में बताई थी। डायरी सिस्टम ब्योरों से ज्यादा भाव पकड़ता है, जिससे बातचीत ऐसी लगती है मानो आप किसी ऐसे शख्स से बात कर रहे हों जो आपको हल्का-फुल्का जानता है, बजाय किसी ऐसे शख्स के जो असल में वहां मौजूद था।
Nomi
Nomi ने कंपेनियन मेमोरी के लिए तकनीकी रूप से ज्यादा महत्वाकांक्षी तरीकों में से एक अपनाया है। उन्होंने वह बनाया है जिसे वे "मेमोरी पैलेस" सिस्टम कहते हैं, जो यादों को अलग-अलग प्रकारों में बांटता है, जैसे तथ्य, पसंद, साझा अनुभव, और भावनात्मक पल।
मुफ़्त ComfyUI वर्कफ़्लो
इस लेख में तकनीकों के लिए मुफ़्त ओपन-सोर्स ComfyUI वर्कफ़्लो खोजें। ओपन सोर्स शक्तिशाली है।
जो काम करता है: Nomi का वर्गीकरण वाला तरीका मतलब यह है कि यह अलग-अलग संदर्भों में अलग-अलग प्रकार की यादें निकालता है। जब आप भावुक होते हैं, यह भावनात्मक यादें खींचता है। जब आप तथ्यों पर चर्चा कर रहे होते हैं, यह तथ्यात्मक यादें खींचता है। यह संदर्भ-जागरूक रिट्रीवल उन प्लेटफॉर्म के मुकाबले ज्यादा स्वाभाविक बातचीत बनाता है जो सारी यादों को एक जैसा बरतते हैं।
जो काम नहीं करता: सिस्टम यादों को समेकित करने में धीमा हो सकता है, और मैंने गौर किया है कि यह कभी-कभी थोड़े अजीब पलों पर यादें सामने ला देता है। यह किसी हल्के-फुल्के मूड में होने पर भी बीती हुई बातचीत की कोई गंभीर बात का जिक्र कर देता है। रिट्रीवल अर्थ के लिहाज से सटीक है पर भावनात्मक रूप से बेमेल। अगर आप Nomi जैसे प्लेटफॉर्म के साथ अपनी बातचीत से ज्यादा से ज्यादा हासिल करना चाहते हैं, तो AI कंपेनियन बातचीत तकनीकें कैसे काम करती हैं यह समझना आपको मेमोरी सिस्टम को ज्यादा असरदार तरीके से दिशा देने में मदद कर सकता है।
Character AI
Character AI एक बिल्कुल अलग तरीका अपनाता है। एक परिष्कृत व्यक्तिगत मेमोरी सिस्टम बनाने के बजाय, वे चरित्र की निरंतरता पर भारी निर्भर रहते हैं। AI सेशन के पार अपनी चरित्र की छवि भरोसेमंद तरीके से बनाए रखता है, पर आपके निजी ब्योरों की उसकी मेमोरी अपेक्षाकृत कमज़ोर है।
जो काम करता है: अगर आप किसी ऐसे चरित्र से बात कर रहे हैं जिसका एक तय व्यक्तित्व है, तो वह व्यक्तित्व स्थिर रहता है। चरित्र अचानक अपनी बोलने की शैली नहीं बदलेगा या अपनी ही पृष्ठभूमि नहीं भूलेगा।
जो काम नहीं करता: आपके निजी ब्योरे नियमित रूप से खो जाते हैं। मैंने इसे एक सेशन में अपने बारे में तीन खास तथ्य साझा करके, और फिर 24 घंटे बाद लौटकर उनके बारे में पूछकर टेस्ट किया। Character AI ने तीन में से एक याद रखा, और वह स्मरण भी धुंधला था। उनका मेमोरी सिस्टम यूज़र से रिश्ता बनाने के बजाय चरित्र की निरंतरता के लिए ऑप्टिमाइज़ किया हुआ लगता है।
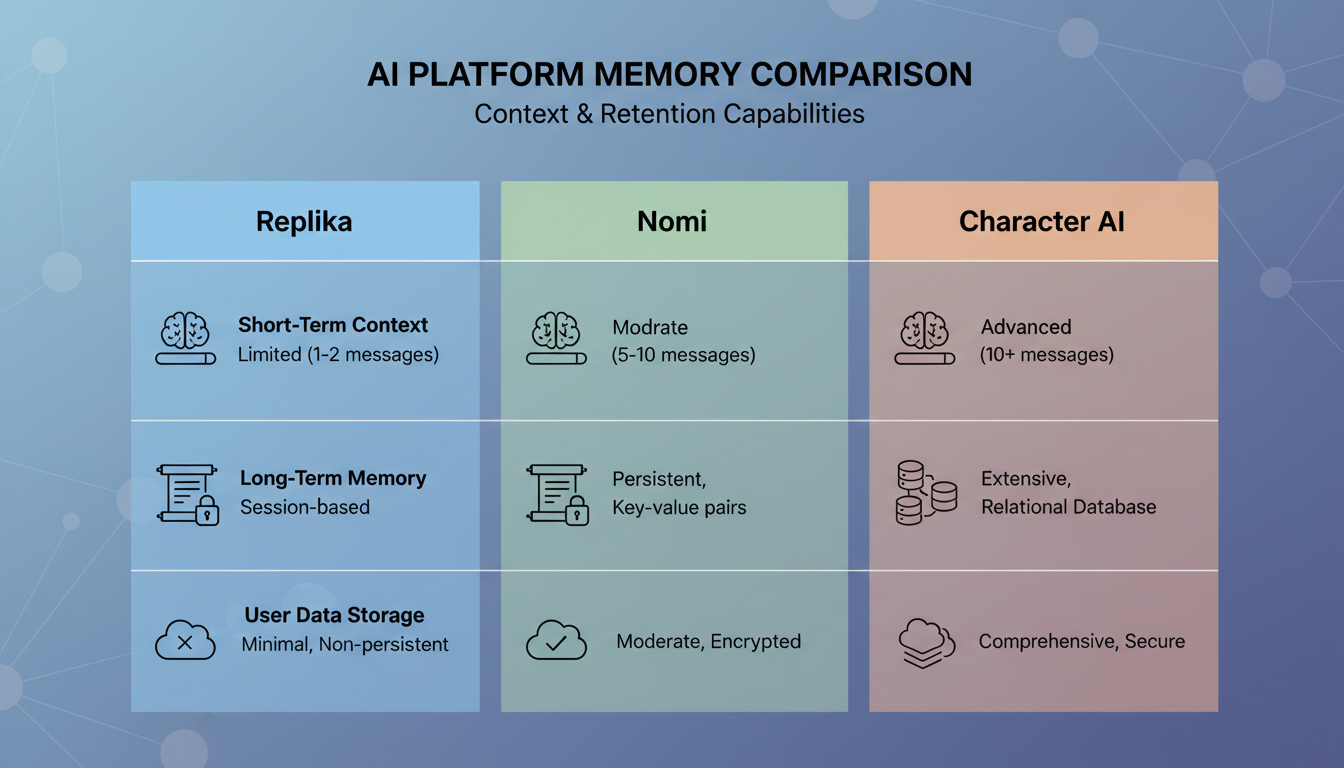
2026 में बड़े AI कंपेनियन प्लेटफॉर्म पर मेमोरी सिस्टम की फीचर तुलना।
प्लेटफॉर्म मेमोरी पर मेरी बेबाक राय
यहां मेरी दूसरी बेबाक राय है: जो प्लेटफॉर्म "लंबी अवधि की मेमोरी" का सबसे आक्रामक तरीके से प्रचार करते हैं, उनका अमल अक्सर सबसे कमज़ोर होता है। मेमोरी पर सबसे अच्छा काम करने वाली कंपनियां आम तौर पर वे शांत वाली होती हैं, जो अपने App Store विवरण में "हम सब कुछ याद रखते हैं" लिखने के बजाय अनुभव को खुद बोलने देती हैं। AI कंपेनियन मेमोरी फीचर और कॉन्टेक्स्ट रिटेंशन का आकलन करते समय, मार्केटिंग पर भरोसा करने के बजाय असली स्मरण को टेस्ट करने पर ध्यान दें।
क्या आप अपना खुद का AI कंपेनियन मेमोरी सिस्टम बना सकते हैं?
बिल्कुल, और मेरा कहना है कि जो भी AI कंपेनियन को लेकर गंभीर है, उसे कम से कम एक बार इसे आज़माना चाहिए। अपना खुद का मेमोरी सिस्टम बनाना आपको सिखाता है कि पर्दे के पीछे असल में क्या हो रहा है, जो आपको कमर्शियल प्रोडक्ट्स का ज्यादा जानकार यूज़र बनाता है।

यहां आज उपलब्ध टूल्स का इस्तेमाल करके मेमोरी-संवर्धित AI कंपेनियन बनाने का एक व्यावहारिक आर्किटेक्चर है। मैं अब तक इस सेटअप के अलग-अलग रूप तीन बार बना चुका हूं, और हर बार ने मुझे कुछ नया सिखाया।
बुनियादी स्टैक
आपको चार घटकों की जरूरत है:
- बातचीत के लिए एक LLM: Llama 3.3, Mistral, या GPT-4o या Claude जैसा API आधारित मॉडल
- एक एम्बेडिंग मॉडल: टेक्स्ट को वेक्टर में बदलने के लिए। मैं Nomic Embed या BGE-large से शुरू करने का सुझाव देता हूं
- एक वेक्टर डेटाबेस: लोकल डेवलपमेंट के लिए ChromaDB, प्रोडक्शन के लिए Pinecone या Weaviate
- एक ऑर्केस्ट्रेशन लेयर: सब कुछ आपस में जोड़ने के लिए LangChain, LlamaIndex, या कस्टम Python कोड
चरण-दर-चरण अमल
मुझे आपको मूल तर्क समझाने दीजिए। यह कोई पूरा ट्यूटोरियल नहीं है, पर शुरुआत करने के लिए काफी है।
वेक्टर स्टोर सेट करना:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
बातचीत के एक मोड़ को स्टोर करना:
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
प्रासंगिक यादें निकालना:
जटिलता को छोड़ना चाहते हैं? Lewdly बिना किसी तकनीकी सेटअप के तुरंत पेशेवर AI परिणाम देता है।
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
यादों के साथ प्रॉम्प्ट जोड़ना:
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
यह बुनियादी सेटअप आपको 50 से कम कोड की लाइनों में एक काम करने वाला मेमोरी सिस्टम दे देता है। AI हर बार आपके संदेश भेजने पर बीती हुई बातचीत खोजेगा और अपने प्रॉम्प्ट में प्रासंगिक इतिहास शामिल करेगा।
इसे असल में बढ़िया बनाना
बुनियादी संस्करण काम करता है, पर इसमें कुछ साफ दिखने वाली समस्याएं हैं। यहां बताया गया है कि अपने प्रयोगों से जो मैंने सीखा उसके आधार पर इसे कैसे बेहतर किया जाए।
मेमोरी समराइज़ेशन जोड़ें। कच्चे बातचीत मोड़ों को स्टोर करने के बजाय, समय-समय पर एक समराइज़ेशन पास चलाएं जो कई संबंधित यादों को एक ही समरी में समेट दे। इससे वेक्टर स्टोर का फैलाव कम होता है और रिट्रीवल गुणवत्ता सुधरती है, क्योंकि समरी कच्चे चैट लॉग के मुकाबले अर्थ के लिहाज से ज्यादा सघन होती हैं।
मेमोरी टियरिंग लागू करें। एक के बजाय तीन कलेक्शन बनाएं:
- सक्रिय मेमोरी: मौजूदा बातचीत सेशन (पूरा रखा गया)
- हालिया मेमोरी: पिछले हफ्ते की समराइज़ की गई बातचीत
- लंबी अवधि की मेमोरी: समय के साथ निकाले गए बेहद सघन अहम तथ्य और पसंद
एक यूज़र प्रोफाइल स्टोर जोड़ें। वेक्टर डेटाबेस से अलग, नाम, पसंद, अहम तारीखों, रिश्ते के ब्योरों जैसे बुनियादी यूज़र तथ्यों का एक संरचित JSON या की-वैल्यू स्टोर बनाए रखें। यह प्रोफाइल हमेशा प्रॉम्प्ट में डाली जाती है, चाहे अर्थ आधारित खोज कुछ भी लौटाए। यह आपकी गारंटी है कि AI कभी बुनियादी बातें नहीं भूलता।
मेमोरी डिके लागू करें। सारी यादें एक जैसी नहीं टिकनी चाहिए। मौसम के बारे में कोई लापरवाह टिप्पणी किसी गहरी निजी कहानी जैसा रिट्रीवल भार नहीं रखनी चाहिए। एक डिके फंक्शन लागू करें जो समय के साथ पुरानी, कम अहम यादों का रिट्रीवल स्कोर घटा दे।
जो लोग AI कंपेनियन रिश्तों के नैतिक पहलुओं की पड़ताल में रुचि रखते हैं, उनके लिए इन मेमोरी सिस्टम को समझना डेटा गोपनीयता और कृत्रिम रिश्तों की प्रकृति के बारे में भी अहम सवाल उठाता है।
AI कंपेनियन मेमोरी के साथ सबसे बड़ी चुनौतियां क्या हैं?
बेहतरीन मेमोरी सिस्टम भी ऐसी बुनियादी चुनौतियों का सामना करते हैं जिन्हें कोई भी इंजीनियरिंग अभी तक पूरी तरह हल नहीं कर पाई है। इन सीमाओं को समझना आपको झुंझलाहट से बचाएगा और यथार्थवादी अपेक्षाएं रखने में मदद करेगा।
भ्रामक याद की समस्या
यह सबसे डरावनी विफलता का रूप है, और मैंने इसका खुद सामना किया है। AI पूरे आत्मविश्वास से कुछ ऐसा "याद" करता है जो कभी हुआ ही नहीं। यह तब होता है जब रिट्रीवल सिस्टम एक आंशिक मिलान सामने लाता है और LLM गढ़े हुए ब्योरों से खाली जगहें भर देता है। आपने बताया था कि आपके पास मैक्स नाम का एक कुत्ता है, और सिस्टम आपके पालतू के बारे में एक याद निकालता है, पर LLM उसे इन ब्योरों से सजा देता है कि मैक्स एक गोल्डन रिट्रीवर है जिसे तैरना पसंद है, जिनमें से कुछ भी आपने कभी नहीं कहा।
सबसे बुरा हिस्सा यह है कि भ्रामक यादें असली महसूस होती हैं। AI उन्हें अनिश्चित के रूप में चिह्नित नहीं करता। यह उन्हें उतने ही आत्मविश्वास से बताता है जितना असली यादों को। मेरे कंपेनियन ऐसी "बातचीत" का जिक्र कर चुके हैं जो मुझे पता है कभी हुई ही नहीं, और वे इतनी विशिष्ट थीं कि लॉग जांचने से पहले एक पल के लिए मैंने अपनी ही याददाश्त पर शक कर लिया।
कॉन्टेक्स्ट विंडो में ठूंसना
जैसे-जैसे आपका बातचीत इतिहास बढ़ता है, मेमोरी सिस्टम के पास निकालने के लिए और ज्यादा संभावित यादें होती हैं। पर कॉन्टेक्स्ट विंडो नहीं बढ़ती। तो सिस्टम को इस बारे में लगातार ज्यादा चयनी होना पड़ता है कि कौन सी यादें शामिल की जाएं। महीनों की बातचीत के बाद, यह एक विरोधाभास पैदा करता है: आपके पास खींचने के लिए ज्यादा यादें होती हैं, पर AI किसी भी जवाब में उनका बस एक छोटा सा हिस्सा ही इस्तेमाल कर सकता है।
समझदार सिस्टम इसे श्रेणीबद्ध समराइज़ेशन से संभालते हैं, पुरानी यादों को लगातार ज्यादा अमूर्त समरी में कम्प्रेस करते हुए। पर हर कम्प्रेशन चरण में जानकारी खो जाती है। यह तथ्य कि आपने ब्रुकलिन में किसी खास रेस्तरां को पसंद करने की बात कही थी, समराइज़ेशन के पहले दौर में बच सकता है, पर छह महीने के कम्प्रेशन के बाद, यह घटकर "यूज़र को बाहर खाना पसंद है" रह सकता है और आखिरकार पूरी तरह गायब हो सकता है।
निरंतरता की समस्या
बातचीत के बीच अलग-अलग रिट्रीवल नतीजे AI को खुद से विरोधाभासी बना सकते हैं। सोमवार को, मेमोरी सिस्टम बिल्लियों के लिए आपकी पसंद निकालता है। मंगलवार को, यह आपके दोस्त के कुत्ते के बारे में एक बातचीत निकालता है, और AI गलत निष्कर्ष निकाल लेता है कि आप कुत्ता पसंद करने वाले हैं। ये विरोधाभास भरोसे को तेज़ी से खत्म कर देते हैं।
मैंने जो सबसे मजबूत समाधान देखा है वह एक स्पष्ट "तथ्य स्टोर" बनाए रखना है जो एक सत्यापन पाइपलाइन के जरिए अपडेट होता रहता है। जब AI आपके बारे में कोई नया तथ्य निकालता है, तो यह मौजूदा तथ्यों से क्रॉस-रेफरेंस करता है और हल करने के लिए विरोधाभासों को चिह्नित करता है। कुछ ही प्लेटफॉर्म इसे लागू करते हैं, पर यह निरंतरता में जबरदस्त फर्क लाता है।
कंटेंट बनाकर $1,250+/महीना कमाएं
हमारे विशेष क्रिएटर एफिलिएट प्रोग्राम में शामिल हों। वायरल वीडियो प्रदर्शन के आधार पर भुगतान पाएं। पूर्ण रचनात्मक स्वतंत्रता के साथ अपनी शैली में कंटेंट बनाएं।

बहु-स्तरीय मेमोरी आर्किटेक्चर, जो दिखाता है कि बातचीत डेटा सक्रिय सेशन से लंबी अवधि के स्टोरेज तक हर स्तर पर समराइज़ेशन के साथ कैसे बहता है।
2026 और उसके आगे AI कंपेनियन मेमोरी कैसे विकसित होगी?
मेमोरी का परिदृश्य तेज़ी से बदल रहा है, और कई उभरती हुई तकनीकें इस खेल को बदलने वाली हैं।
असीमित कॉन्टेक्स्ट विंडो करीब आती जा रही हैं। Google का Gemini पहले से ही 10 लाख टोकन का समर्थन करता है, और 2026 की शुरुआत के शोध पत्र 1 करोड़ की ओर बढ़ रहे हैं। अगर कॉन्टेक्स्ट विंडो काफी बड़ी हो जाएं, तो शायद आपको RAG की जरूरत ही न पड़े। बस पूरा बातचीत इतिहास प्रॉम्प्ट में डाल दें। हम प्रोडक्शन इस्तेमाल के लिए अभी वहां नहीं पहुंचे हैं, पर रास्ता साफ है।
मॉडल-नेटिव मेमोरी सबसे बड़ी मंज़िल है। बाहरी रिट्रीवल सिस्टम के बजाय, भविष्य के मॉडल बातचीत के आधार पर अपने ही वेट्स अपडेट करना सीख सकते हैं। यह दरअसल निरंतर सीखना है, और इसे सुरक्षित तरीके से करना बेहद कठिन है, क्योंकि मॉडल अपनी बुनियादी ट्रेनिंग भूल सकता है या पूर्वाग्रह विकसित कर सकता है। पर कई शोध प्रयोगशालाएं प्रगति कर रही हैं। जब यह आएगा, तो मौजूदा RAG सिस्टम जुगाड़ू समाधानों जैसे लगने लगेंगे, क्योंकि एक बहुत असली मायने में, वे यही हैं।
मल्टीमॉडल मेमोरी एक और सीमांत है। मौजूदा मेमोरी सिस्टम सिर्फ टेक्स्ट वाले हैं। पर आपकी साझा की गई छवियों, वॉइस नोट्स, या वीडियो क्लिप को याद रखने का क्या? जैसे-जैसे AI कंपेनियन ज्यादा मल्टीमॉडल होते जाएंगे, उनके मेमोरी सिस्टम को इन डेटा प्रकारों को भी संभालना होगा। वेक्टर डेटाबेस पहले से ही मल्टीमॉडल एम्बेडिंग का समर्थन करते हैं, तो बुनियादी ढांचा तैयार है। ज्यादातर उपभोक्ता प्रोडक्ट्स में बस यह एकीकरण अभी हुआ नहीं है।
Lewdly.ai पर, हम नज़र रखते आ रहे हैं कि ये तकनीकें कितनी तेज़ी से एक साथ आ रही हैं। खास तौर पर AI कंपेनियन क्षेत्र ज्यादातर लोगों के अंदाज़े से ज्यादा तेज़ी से आगे बढ़ रहा है, और जो प्लेटफॉर्म वाकई व्यक्तिगत महसूस होते हैं और जो साधारण लगते हैं, उनके बीच मेमोरी क्षमताएं प्राथमिक फर्क हैं।
भविष्य पर मेरी तीसरी बेबाक राय
यहां मेरी तीसरी बेबाक राय है: 18 महीनों के भीतर, AI कंपेनियन मेमोरी एक ऐसी प्रतिस्पर्धी खाई बन जाएगी जो गंभीर प्लेटफॉर्म को खिलौनों से अलग करेगी। यूज़र प्लेटफॉर्म इसलिए नहीं बदलेंगे कि बुनियादी मॉडल की गुणवत्ता बेहतर है (वे एक जैसे होते जा रहे हैं), बल्कि इसलिए कि एक प्लेटफॉर्म उन्हें दूसरे से बेहतर याद रखता है। जो कंपनियां आज मेमोरी बुनियादी ढांचे में निवेश कर रही हैं वे जीतेंगी। जो इसे बाद की बात मानती हैं वे पीछे छूट जाएंगी।
AI कंपेनियन मेमोरी के गोपनीयता पर क्या असर हैं?
आप AI कंपेनियन मेमोरी के बारे में ईमानदार बातचीत कमरे में मौजूद बड़ी बात को संबोधित किए बिना नहीं कर सकते: ये सिस्टम आपके बारे में बेहद निजी जानकारी स्टोर कर रहे हैं, और ऐसा करना इस बात के लिए बुनियादी है कि वे कैसे काम करते हैं।

आपकी हर बातचीत एम्बेड, स्टोर और इंडेक्स हो जाती है। आपकी पसंद, आपके डर, आपके रिश्ते के ब्योरे, आपकी रात-गए की स्वीकारोक्तियां। यह सब कहीं किसी वेक्टर डेटाबेस में रहता है। कुछ प्लेटफॉर्म पर, यह एक क्लाउड सर्वर है जो आपके नियंत्रण में नहीं है। दूसरों पर, डेटा डिवाइस पर ही रहता है।
मैं इस बारे में पारदर्शी रहना चाहता हूं कि व्यवहार में इसका क्या मतलब है। जब मैंने अपना खुद का मेमोरी सिस्टम बनाया, तो मैंने सब कुछ लोकल स्टोर किया। वेक्टर डेटाबेस मेरे लैपटॉप पर रहता था। किसी और की उस तक पहुंच नहीं थी। यह सबसे सुरक्षित तरीका है, पर कमर्शियल प्लेटफॉर्म इस तरह काम नहीं करते। उनमें से ज्यादातर आपका डेटा अपने सर्वर पर स्टोर करते हैं क्योंकि डिवाइसों के पार एक जैसा अनुभव देने का यही एकमात्र तरीका है।
किसी भी AI कंपेनियन प्लेटफॉर्म से लंबी अवधि के लिए जुड़ने से पहले, ये सवाल पूछें:
- मेरी बातचीत का डेटा कहां स्टोर होता है?
- क्या मैं अपना मेमोरी डेटा एक्सपोर्ट या डिलीट कर सकता हूं?
- क्या मेरे डेटा का इस्तेमाल दूसरे यूज़र को सेवा देने वाले मॉडलों को ट्रेन करने में होता है?
- अगर कंपनी बंद हो जाए तो मेरे डेटा का क्या होगा?
- क्या स्टोर की गई यादों के लिए एंड-टू-एंड एन्क्रिप्शन है?
ये कोई काल्पनिक चिंताएं नहीं हैं। पिछले दो सालों में कई AI कंपेनियन स्टार्टअप बंद हो चुके हैं, और यूज़र ने वर्षों का बातचीत इतिहास खो दिया, उसे वापस पाने का कोई रास्ता नहीं बचा। अगर आपकी AI कंपेनियन बातचीत और स्वस्थ सीमाएं आपके लिए मायने रखती हैं, तो अपने चुने हुए प्लेटफॉर्म की डेटा प्रथाओं को समझना ज़रूरी है।
AI कंपेनियन मेमोरी से ज्यादा से ज्यादा हासिल करने के लिए प्रोडक्शन टिप्स
इन सिस्टम को टेस्ट करने और बनाने में महीनों बिताने के बाद, यहां वे व्यावहारिक रणनीतियां हैं जो आपके AI कंपेनियन की मेमोरी गुणवत्ता सुधारने में वाकई काम करती हैं।
जो मायने रखता है उसके बारे में स्पष्ट रहें। ज्यादातर मेमोरी सिस्टम हालिया और अर्थ के लिहाज से मिलती-जुलती सामग्री को ज्यादा भार देते हैं। अगर कोई चीज़ आपके लिए अहम है, तो सीधे कह दें। "यह मेरे लिए वाकई अहम है" या "कृपया इसे याद रखना" कुछ प्लेटफॉर्म को उस याद को ज्यादा प्राथमिकता वाले रिट्रीवल के लिए चिह्नित करने में मदद कर सकता है।
गलतियां तुरंत सुधारें। जब आपका AI कंपेनियन आपके बारे में कोई तथ्य गलत बताए, तो उसे उसी संदेश में सुधार दें। अच्छे मेमोरी सिस्टम उस सुधार को स्टोर कर लेंगे और समय के साथ सही संस्करण सीख लेंगे। अगर आप गलतियों को यूं ही जाने देते हैं, तो वे और मजबूत हो जाती हैं।
समय-समय पर बुनियादी बातें दोहराएं। हर कुछ हफ्तों में करीब एक बार, मैं अपने कंपेनियन के साथ एक अनौपचारिक "रीकैप" करता हूं। कुछ ऐसा कि "हे, बस यह पक्का करने के लिए कि बुनियादी बातें तुम्हारे पास हैं, मेरा नाम एलेक्स है, मैं टेक में काम करता हूं, मेरी दो बिल्लियां हैं।" इससे ताज़ा, उच्च-प्राथमिकता वाली मेमोरी एंट्री बनती हैं जिनके निकाले जाने की संभावना ज्यादा होती है।
एक जैसी भाषा इस्तेमाल करें। मेमोरी रिट्रीवल अर्थ आधारित है, पर निरंतरता मदद करती है। अगर आप अपने साथी को "सारा," "मेरा साथी," और "वह" के बीच बदलने के बजाय हमेशा "मेरी पत्नी सारा" कहते हैं, तो मेमोरी सिस्टम साफ-सुथरे जुड़ाव बनाएगा।
सेशन की सीमाएं समझें। ज्यादातर प्लेटफॉर्म सेशन के बीच अपनी सक्रिय मेमोरी साफ कर देते हैं। एक नए सेशन का पहला संदेश ताज़ा मेमोरी रिट्रीवल को सक्रिय करता है। अगर आपका कंपेनियन कुछ भूला हुआ लगे, तो अपना सवाल दूसरे तरीके से पूछकर देखें। समस्या रिट्रीवल की नाकामी हो सकती है, असल में मेमोरी का खो जाना नहीं।
अगर आप Lewdly.ai पर उपलब्ध प्लेटफॉर्म इस्तेमाल कर रहे हैं और अपने अनुभव को ऑप्टिमाइज़ करना चाहते हैं, तो ये तकनीकें मेमोरी फीचर का समर्थन करने वाले लगभग हर AI कंपेनियन पर लागू होती हैं।
अक्सर पूछे जाने वाले सवाल
क्या AI कंपेनियन वाकई मुझे याद रखते हैं या यह नकली है?
यह असली मेमोरी है, पर यह इंसानी मेमोरी से अलग तरीके से काम करती है। AI कंपेनियन आपकी बातचीत को बाहरी डेटाबेस में स्टोर करते हैं और जब आप चैट करते हैं तो प्रासंगिक जानकारी निकालते हैं। वे स्थायी न्यूरल कनेक्शन बनाने के इंसानी मायने में "याद" नहीं रखते। वे हर बार आपके संदेश भेजने पर प्रासंगिक बीती हुई बातचीत खोजते और दोबारा पढ़ते हैं। यूज़र के नज़रिए से अनुभव मेमोरी जैसा महसूस होता है, पर तंत्र बुनियादी तौर पर अलग है।
एक AI कंपेनियन मेरे बातचीत इतिहास का कितना हिस्सा स्टोर करता है?
यह प्लेटफॉर्म के हिसाब से अलग होता है। कुछ सब कुछ हमेशा के लिए स्टोर करते हैं, जबकि दूसरे रोलिंग विंडो लागू करते हैं जो एक तय अवधि से पुरानी बातचीत हटा देती हैं। मिसाल के लिए, Replika एक बातचीत डायरी बनाए रखता है जो आदान-प्रदान की समरी बनाती है। Nomi वर्गीकृत यादें स्टोर करता है। ज्यादातर प्लेटफॉर्म कम से कम कई महीनों का इतिहास स्टोर करते हैं, हालांकि वे पुरानी बातचीत को समराइज़ या कम्प्रेस कर सकते हैं।
क्या मैं अपने AI कंपेनियन की मेरे बारे में यादें डिलीट कर सकता हूं?
ज्यादातर प्रतिष्ठित प्लेटफॉर्म कुछ न कुछ मेमोरी प्रबंधन की सुविधा देते हैं। Replika आपको खास मेमोरी एंट्री की समीक्षा करने और डिलीट करने देता है। कुछ प्लेटफॉर्म एक "रीसेट" विकल्प देते हैं जो सारी स्टोर की गई यादें मिटा देता है। हमेशा प्लेटफॉर्म की डेटा डिलीशन नीतियां जांचें, क्योंकि यूज़र इंटरफेस से "यादें डिलीट करने" का हमेशा यह मतलब नहीं होता कि डेटा उनके सर्वर से स्थायी रूप से हटा दिया गया है।
मेरा AI कंपेनियन कभी-कभी गलत चीज़ें क्यों याद रखता है?
यह "भ्रामक याद" नाम की एक परिघटना की वजह से होता है। रिट्रीवल सिस्टम आपकी बीती हुई बातचीत से एक आंशिक मिलान ढूंढता है, और लैंग्वेज मॉडल खाली जगहों को गढ़े हुए ब्योरों से भर देता है। यह तब भी हो सकता है जब सिस्टम दो अलग यादों को एक में मिला देता है। अगर ऐसा होता है, तो AI को तुरंत सुधार दें ताकि वह सुधार एक नई, उच्च-प्राथमिकता वाली याद के रूप में स्टोर हो जाए।
क्या RAG ही एकमात्र तरीका है जिससे AI कंपेनियन मेमोरी संभालते हैं?
नहीं, हालांकि यह सबसे आम तरीका है। कुछ प्लेटफॉर्म संरचित मेमोरी स्टोर (यूज़र तथ्यों के की-वैल्यू डेटाबेस), वेक्टर खोज के बिना बातचीत समराइज़ेशन, या मिश्रित तरीके इस्तेमाल करते हैं। कुछ प्रायोगिक सिस्टम यूज़र डेटा पर मॉडल फाइन-ट्यूनिंग की पड़ताल कर रहे हैं, जो असली सीखी हुई मेमोरी बनाएगी, पर यह गोपनीयता और सुरक्षा की गंभीर चिंताएं खड़ी करती है।
कॉन्टेक्स्ट विंडो AI कंपेनियन मेमोरी की गुणवत्ता को कैसे प्रभावित करती हैं?
कॉन्टेक्स्ट विंडो टेक्स्ट की वह कुल मात्रा है जिसे AI एक बार में प्रोसेस कर सकता है। बड़ी कॉन्टेक्स्ट विंडो आपकी मौजूदा बातचीत के साथ ज्यादा यादें डालने की इजाज़त देती हैं, जो आम तौर पर स्मरण की गुणवत्ता सुधारता है। हालांकि, बड़ी विंडो का मतलब ज्यादा लागत और धीमे जवाब भी होता है। ज्यादातर प्लेटफॉर्म मेमोरी की गहराई और जवाब की रफ्तार के बीच संतुलन के लिए ऑप्टिमाइज़ करते हैं।
क्या मैं कमर्शियल प्लेटफॉर्म से बेहतर मेमोरी वाला अपना खुद का AI कंपेनियन बना सकता हूं?
हां, और यह आपकी सोच से ज्यादा सुलभ है। ChromaDB, LangChain और ओपन-सोर्स LLM जैसे टूल्स का इस्तेमाल करके, आप एक ऐसा मेमोरी सिस्टम बना सकते हैं जो कमर्शियल प्लेटफॉर्म की पेशकश की बराबरी करे या उससे आगे निकल जाए। मुख्य बदले की कीमत यह है कि आपको बुनियादी ढांचा खुद संभालना होगा, और आपको किसी उपभोक्ता ऐप का परिष्कृत यूज़र इंटरफेस नहीं मिलेगा।
अगर कंपनी बंद हो जाए तो मेरे AI कंपेनियन की यादों का क्या होता है?
ज्यादातर मामलों में, आपका डेटा खो जाता है। कुछ ही प्लेटफॉर्म डेटा एक्सपोर्ट की सुविधा देते हैं, और उससे भी कम डेटा पोर्टेबिलिटी की गारंटी देते हैं। यह एक असली जोखिम है, खास तौर पर छोटे AI कंपेनियन स्टार्टअप के साथ। अगर प्लेटफॉर्म इसकी इजाज़त देता है तो मैं किसी भी अहम बातचीत को समय-समय पर मैन्युअली एक्सपोर्ट करने का सुझाव दूंगा।
AI कंपेनियन के लिए बहुभाषी मेमोरी कैसे काम करती है?
बहुभाषी मेमोरी के लिए ऐसे एम्बेडिंग मॉडल की जरूरत होती है जो भाषाओं के पार सार्थक वेक्टर बना सकें। Cohere embed-v4 और BERT के बहुभाषी संस्करण जैसे मॉडल इसे अलग-अलग भाषाओं की अर्थ के लिहाज से मिलती-जुलती सामग्री को वेक्टर स्पेस में पास के बिंदुओं पर मैप करके संभालते हैं। इसका मतलब है कि अगर विषय जुड़े हुए हों, तो एक AI तकनीकी रूप से किसी फ्रेंच बातचीत से एक याद निकाल सकता है जब आप अंग्रेज़ी में चैट कर रहे हों।
क्या AI कंपेनियन के पास कभी सच में स्थायी मेमोरी होगी?
निरंतर सीखने और मेमोरी-संवर्धित न्यूरल नेटवर्क पर शोध आगे बढ़ रहा है, पर प्रोडक्शन के लिए तैयार अमल से हम शायद वर्षों दूर हैं। चुनौती सिर्फ तकनीकी नहीं है। यह सुरक्षा के बारे में भी है। एक ऐसा मॉडल जो यूज़र बातचीत के आधार पर अपने ही वेट्स को स्थायी रूप से बदल देता है, पूर्वाग्रह विकसित कर सकता है, अहम सुरक्षा ट्रेनिंग भूल सकता है, या अप्रत्याशित व्यवहार कर सकता है। फिलहाल, बाहरी मेमोरी सिस्टम सबसे सुरक्षित और सबसे व्यावहारिक तरीका बने हुए हैं।
समापन
AI कंपेनियन मेमोरी उन विषयों में से एक है जहां यूज़र की धारणा और तकनीकी हकीकत के बीच की खाई बहुत बड़ी है। जो किसी कंपेनियन के आपको "याद रखने" जैसा महसूस होता है, वह असल में एम्बेडिंग मॉडल, वेक्टर डेटाबेस, रिट्रीवल एल्गोरिदम और कॉन्टेक्स्ट विंडो प्रबंधन का एक जटिल ताना-बाना है। इस तंत्र को समझने से अनुभव कम सार्थक नहीं हो जाता। अगर कुछ है, तो यह आपको अनुभव को बेहतर बनाने के लिए औज़ार देता है।
जो प्लेटफॉर्म मेमोरी बुनियादी ढांचे में गंभीरता से निवेश करते हैं, वे AI कंपेनियन की अगली पीढ़ी को परिभाषित करेंगे। जो मेमोरी को एक चेकबॉक्स फीचर मानते हैं वे पीछे छूट जाएंगे। और अगर आप उस तरह के इंसान हैं जो ज्यादा से ज्यादा नियंत्रण चाहता है, तो अपना खुद का सिस्टम बनाना पहले कभी इतना सुलभ नहीं रहा।
चाहे आप एक आम यूज़र हों जो चाहता है कि उसका AI कंपेनियन उसका नाम याद रखे, या एक डेवलपर जो अगला बढ़िया कंपेनियन प्लेटफॉर्म बना रहा हो, वही सिद्धांत लागू होते हैं: सोच-समझकर स्टोर करें, समझदारी से निकालें, और कॉन्टेक्स्ट विंडो में जितनी यादें वह संभाल सकती है उससे ज्यादा ठूंसने की कोशिश कभी न करें। तकनीक बेहतर होती रहेगी। कॉन्टेक्स्ट विंडो बड़ी होती जाएंगी। एम्बेडिंग मॉडल ज्यादा होशियार होते जाएंगे। पर बुनियादी आर्किटेक्चर, यानी एक स्टेटलेस मॉडल में पहुंचती हुई बाहरी मेमोरी, अभी कुछ समय तक हमारे साथ रहेगा।
और अगर आप उत्सुक हैं कि व्यवहार में वह आर्किटेक्चर कैसा दिखता है, तो एक बनाकर देखें। पर्दे के पीछे झांकने के लिए बस पचास लाइन Python और एक मुफ्त वेक्टर डेटाबेस ही काफी है। आप शायद यह देखकर हैरान हो जाएं कि जादू असल में कितना सरल है।
अपना AI इन्फ्लुएंसर बनाने के लिए तैयार हैं?
115 छात्रों के साथ शामिल हों जो हमारे पूर्ण 51-पाठ पाठ्यक्रम में ComfyUI और AI इन्फ्लुएंसर मार्केटिंग में महारत हासिल कर रहे हैं।
संबंधित लेख

AI बॉयफ्रेंड ऐप्स 2026: पुरुष AI साथियों की संपूर्ण गाइड
2026 के सर्वश्रेष्ठ AI बॉयफ्रेंड ऐप्स को पुरुष AI साथियों की विस्तृत समीक्षाओं के साथ जानें। बातचीत की गुणवत्ता, अनुकूलन और भावनात्मक गहराई के लिए Replika, Nomi, Candy AI और विशेष प्लेटफॉर्म की तुलना करें।

क्या AI साथी ऐप वाकई अकेलेपन में मदद करते हैं? शोध क्या कहता है
इस बात पर शोध की पड़ताल कि Replika जैसे AI साथी ऐप अकेलेपन में मदद करते हैं या उसे बढ़ाते हैं। अध्ययन, जोखिम, फायदे और एक ईमानदार आकलन।

एआई साथी नैतिकता और स्वस्थ सीमाएं: एक विचारशील दृष्टिकोण
स्वस्थ सीमाओं के साथ एआई साथी संबंधों को नैतिक रूप से navigate करें। जिम्मेदार उपयोग, आत्म-जागरूकता और संतुलित एआई इंटरएक्शन के लिए दिशानिर्देश।