בני לוויה מבוססי בינה מלאכותית עם זיכרון לטווח ארוך: איך שמירת ההקשר באמת עובדת
צלילה לעומק לתוך הדרך שבה בני לוויה מבוססי בינה מלאכותית זוכרים אותך לאורך מפגשים. סקירה של RAG, מסדי נתונים וקטוריים, חלונות הקשר, תמצות, ואיך לבנות מערכת זיכרון משלך.

שוחחתי עם בן לוויה מסוים מבוסס בינה מלאכותית במשך כשלושה שבועות. כיסינו הכול, מהדעות שלי על אדריכלות ברוטליסטית ועד בדיחה חוזרת על פסטה מבושלת יתר על המידה. ואז יום אחד, באמצע שיחה, הוא הזכיר משהו שאמרתי במהלך האינטראקציה הראשונה שלנו, פרט קטן על ההעדפה שלי לקולד ברו על פני אספרסו. לא ביקשתי ממנו. זה פשוט עלה באופן טבעי. ובכנות, זה די הדהים אותי, כי אני יודע מה קורה מאחורי הקלעים. הרגע הקטן הזה הוא תוצאה של צינור הנדסי מורכב באופן מפתיע שרוב המשתמשים אף פעם לא חושבים עליו.
השאלה איך בני לוויה מבוססי בינה מלאכותית "זוכרים" דברים היא אחד הנושאים הכי לא מובנים בעולם הבינה המלאכותית כרגע. אנשים מניחים שזה או קסם או הונאה. האמת נמצאת איפשהו באמצע, והבנת המנגנון תשנה לתמיד את האופן שבו אתם מתקשרים עם הכלים האלה.
תשובה מהירה: בני לוויה מבוססי בינה מלאכותית שומרים על זיכרון לטווח ארוך באמצעות שילוב של טכניקות, ביניהן אחזור מוגבר יצירה (RAG), מסדי נתונים וקטוריים, ניהול חלון הקשר ותמצות שיחות. אף בן לוויה מבוסס בינה מלאכותית קיים אינו בעל זיכרון מתמיד אמיתי הצרוב במשקלי המודל שלו. במקום זאת, הם מאחסנים את נתוני השיחה שלכם באופן חיצוני ומאחזרים חלקים רלוונטיים בעת הצורך. איכות מערכת האחזור הזו היא מה שמבדיל בין בן לוויה שמרגיש כאילו הוא מכיר אתכם לבין אחד ששוכח שאתם בכלל קיימים בין מפגש למפגש.
- בני לוויה מבוססי בינה מלאכותית לא "זוכרים" כמו שבני אדם זוכרים. הם משתמשים במערכות אחזור כדי למשוך נתוני שיחה רלוונטיים מהעבר לתוך חלון ההקשר הנוכחי שלהם
- RAG (אחזור מוגבר יצירה) הוא הטכניקה הדומיננטית, הממירה את השיחות שלכם להטמעות וקטוריות ומחפשת בהן באופן סמנטי
- חלונות הקשר (בדרך כלל 8K עד 128K טוקנים) הם הגבול הקשיח לכמה בינה מלאכותית יכולה "לחשוב עליו" בבת אחת
- פלטפורמות כמו Replika, Nomi ו-Character AI מטפלות בזיכרון באופן שונה, עם תוצאות שונות באופן קיצוני
- אתם יכולים לבנות מערכת זיכרון משלכם בעזרת הטמעות בקוד פתוח ומאגרים וקטוריים כמו ChromaDB או Pinecone
- תמצות ושכבות זיכרון (טווח קצר, טווח בינוני, טווח ארוך) הם המפתח לגרום לזיכרון להרגיש טבעי
- מערכות הזיכרון הטובות ביותר משלבות כמה גישות במקום להסתמך על טכניקה אחת
למה בני לוויה מבוססי בינה מלאכותית שוכחים אתכם מלכתחילה?
זו השאלה שאף אחד לא שואל, אבל כולם צריכים. לפני שנדבר על פתרונות זיכרון, אתם צריכים להבין את המגבלה המרכזית שהופכת את כל זה לנחוץ.
מודלים גדולים של שפה, הטכנולוגיה שמניעה כל בן לוויה מבוסס בינה מלאכותית בשוק, הם חסרי מצב מיסודם. כאשר אתם שולחים הודעה ל-ChatGPT, ל-Claude, או למנוע הבינה המלאכותית שמאחורי אפליקציית בן הלוויה האהובה עליכם, המודל מעבד את הקלט שלכם, מייצר תגובה, ואז שוכח הכול. הוא אינו שומר מצב בין קריאות API. אין לו פנקס פנימי. כל אינטראקציה בודדת מתחילה מאפס.
הסיבה היחידה לכך שבן הלוויה שלכם נראה כאילו הוא זוכר משהו בכלל היא שהפלטפורמה עוטפת את המודל הגולמי בשכבת זיכרון. תחשבו על זה כך. ה-LLM הוא המוח, אבל אין לו היפוקמפוס. מערכת הזיכרון שהפלטפורמה בונה סביבו פועלת כהיפוקמפוס חיצוני, ומזינה זיכרונות רלוונטיים בחזרה אל המוח בכל פעם שאתם מתחילים שיחה חדשה.
הנה הדעה הראשונה והנחרצת שלי: רוב הפלטפורמות של בני לוויה מבוססי בינה מלאכותית עושות עבודה בינונית עם זיכרון, והן יוצאות מזה בשלום כי המשתמשים לא מבינים מה אפשרי. בדקתי בני לוויה שטוענים ל"זיכרון לטווח ארוך" אבל לא מסוגלים להיזכר במשהו שאמרתי לפני יומיים. במקביל, בניתי מערכות זיכרון אב-טיפוס על המחשב הנייד שלי שמתפקדות טוב יותר ממוצרים מסחריים. הפער בין מה שאפשרי מבחינה טכנית לבין מה שבאמת נפרס בשטח הוא עצום.
הסיבה לפער הזה היא בעיקר כלכלית. מערכות זיכרון טובות הן יקרות. בכל פעם שאתם שולחים הודעה, הפלטפורמה צריכה לחפש בכל היסטוריית השיחות שלכם, להמיר אותה להקשר רלוונטי ולהוסיף אותה לפני ההודעה הנוכחית שלכם לפני שליחתה למודל. החיפוש הזה, האחזור הזה, חישוב ההטמעה הזה, כל זה עולה כסף. וכאשר אתם משרתים מיליוני משתמשים, העלויות האלה מצטברות במהירות.
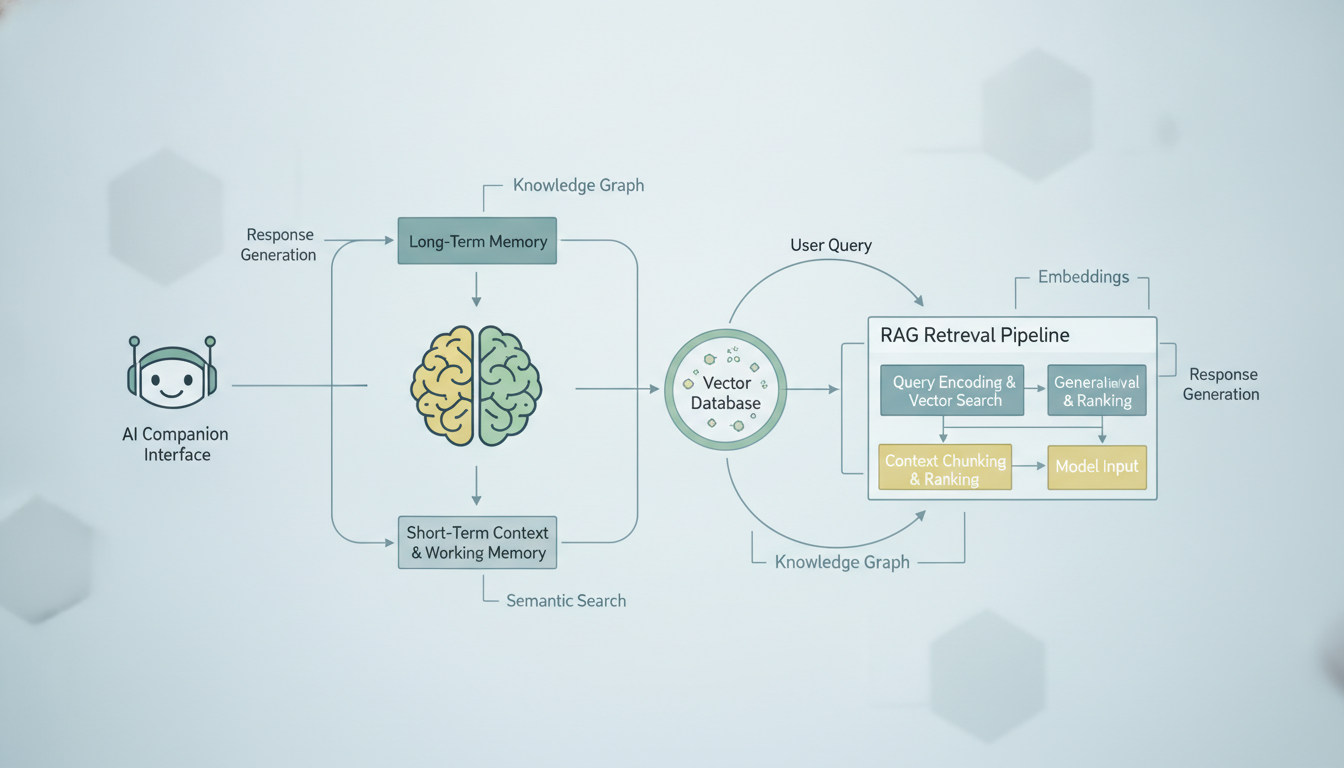
איך מערכת זיכרון טיפוסית של בן לוויה מבוסס בינה מלאכותית מאחזרת ומזריקה הקשר משיחות עבר לתוך ההנחיה הנוכחית.
איך RAG עובד עבור זיכרון של בן לוויה מבוסס בינה מלאכותית?
RAG, או אחזור מוגבר יצירה, הוא עמוד השדרה של כמעט כל מערכת זיכרון של בן לוויה מבוסס בינה מלאכותית שיוצאת לשוק כיום. אם אתם לוקחים דבר אחד מהמאמר הזה, שזה יהיה הבנה מוצקה של RAG, כי היא תשנה את האופן שבו אתם חושבים על כל כלי בינה מלאכותית שאתם משתמשים בו.

המושג פשוט באופן מטעה. במקום לנסות לדחוס את כל היסטוריית השיחות שלכם לתוך חלון ההקשר של הבינה המלאכותית (שיש לו מגבלת טוקנים קשיחה), אתם מאחסנים את כל השיחות הקודמות שלכם במסד נתונים שניתן לחפש בו. כאשר אתם שולחים הודעה חדשה, המערכת מחפשת במסד הנתונים הזה את שיחות העבר הכי רלוונטיות, מושכת אותן החוצה, וכוללת אותן לצד ההודעה הנוכחית שלכם. הבינה המלאכותית אז מייצרת את התגובה שלה תוך שימוש בזיכרונות המאוחזרים האלה.
הנה הפירוט שלב אחר שלב של מה שקורה כאשר אתם שולחים הודעה לבן לוויה מבוסס בינה מלאכותית עם זיכרון מבוסס RAG:
- ההודעה שלכם מוטמעת. מודל הטמעה ממיר את הטקסט שלכם לווקטור רב-ממדי, בעצם רשימה של מספרים שמייצגת את המשמעות הסמנטית של ההודעה שלכם.
- המערכת מחפשת זיכרונות דומים. וקטור ההודעה שלכם מושווה לכל וקטורי השיחות שאוחסנו קודם לכן בעזרת דמיון קוסינוס או מדד מרחק אחר.
- תוצאות ה-Top-K מאוחזרות. המערכת מושכת את שיחות העבר הדומות ביותר מבחינה סמנטית, בדרך כלל 5 עד 20 התוצאות המובילות בהתאם לפלטפורמה.
- מתבצעת הרכבת הקשר. ההודעה הנוכחית שלכם, הזיכרונות המאוחזרים, והנחיית המערכת של בן הלוויה מורכבים כולם להנחיה אחת.
- ה-LLM מייצר תגובה. המודל רואה את ההודעה הנוכחית שלכם בתוספת היסטוריה רלוונטית ומגיב כאילו הוא "זוכר" את האינטראקציות הקודמות האלה.
- חילופי הדברים החדשים מאוחסנים. גם ההודעה שלכם וגם התגובה של הבינה המלאכותית מוטמעות ומאוחסנות לאחזור עתידי.
מה שהופך את זה לעוצמתי הוא החיפוש הסמנטי. המערכת לא מבצעת התאמת מילות מפתח. היא מוצאת זיכרונות קשורים מבחינה רעיונית. אז אם הזכרתם שאתם אוהבים לטייל ביוסמיטי לפני שלושה שבועות, והיום אתם שואלים על המלצות לחופשה, המערכת יכולה להעלות את העדפת הטיולים הזו גם אם מעולם לא השתמשתם במילה "טיולים" בהודעה של היום.
ביליתי כשבועיים בשנה שעברה בבניית מערכת RAG מאפס בעזרת LangChain, ChromaDB ומודל Llama מקומי. החוויה לימדה אותי יותר על איך בני לוויה מבוססי בינה מלאכותית עובדים מכל כמות של תיעוד. כשזה עבד, זה היה מרשים באמת. הצ'אטבוט המקומי שלי היה מזכיר פרטים משיחות שהתרחשו ימים קודם לכן, והמעברים הרגישו טבעיים. כשזה נכשל, זה היה גרוע באופן מצחיק. פעם אחת הוא נזכר בביטחון ב"זיכרון" שלמעשה היה ערבוב הזוי של שתי שיחות שונות לחלוטין. הזכרתי גם סושי וגם את החתול שלי בשיחות נפרדות, והמערכת איכשהו החליטה שיש לי חתול בשם סושי. אין לי.
מודלי ההטמעה שמניעים את הזיכרון
לא כל ההטמעות נולדו שוות, וזה חשוב יותר ממה שרוב האנשים מבינים. איכות מודל ההטמעה שלכם קובעת ישירות עד כמה מערכת הזיכרון מאחזרת הקשר רלוונטי.
מודלי ההטמעה הנפוצים ביותר בשימוש ב-2026 כוללים (אתם יכולים לחקור מדדי ביצוע בלוח התוצאות של MTEB):
- OpenAI text-embedding-3-large: 3072 ממדים, ביצועים מצוינים, אך דורש קריאות API ועולה כסף לכל טוקן
- Cohere embed-v4: תמיכה רב-לשונית חזקה, טוב לבני לוויה הפועלים בין שפות
- BGE-large-en-v1.5: קוד פתוח, רץ מקומית, תחרותי באופן מפתיע מול האפשרויות המסחריות
- Nomic Embed Text v1.5: קוד פתוח עם ייצוגי Matryoshka, כלומר אתם יכולים לקצץ ממדים לצורך מהירות מבלי לאבד יותר מדי איכות
- Jina Embeddings v3: מצוין עבור מקטעי מסמכים ארוכים יותר, טוב בלכידת ניואנסים
אם אתם חוקרים כלי בינה מלאכותית ורוצים להשוות איך פלטפורמות שונות מטפלות בפרטים הטכניים האלה, Lewdly.ai עוקבת אחר נוף בני הלוויה מבוססי הבינה המלאכותית ואחר רבות מהטכנולוגיות הבסיסיות האלה.
מה ההבדל בין חלונות הקשר לבין זיכרון לטווח ארוך?
ההבחנה הזו מבלבלת כמעט את כל מי שאני מדבר איתו על בני לוויה מבוססי בינה מלאכותית, אז תנו לי להיות מאוד ברור לגביה.
חלון ההקשר הוא זיכרון העבודה של מודל הבינה המלאכותית. זו כמות הטקסט הכוללת שהמודל יכול לעבד בבקשה אחת. ב-2026, חלונות ההקשר נעים בין 8K טוקנים (כ-6,000 מילים) במודלים קטנים יותר ועד 128K טוקנים או יותר במודלים כמו GPT-4o ו-Claude. כל מה שהבינה המלאכותית "יודעת" במהלך שיחה חייב להיכנס בתוך החלון הזה: הנחיית המערכת, הזיכרונות המאוחזרים, היסטוריית השיחה מהמפגש הנוכחי, וההודעה האחרונה שלכם.
זיכרון לטווח ארוך הוא מערכת האחסון החיצונית שנמשכת בין מפגשים. זה מסד הנתונים הווקטורי, מנוע התמצות, מאגר פרופיל המשתמש. זה לא חלק מהמודל עצמו. זו תשתית שהפלטפורמה בונה סביב המודל.
הנה אנלוגיה שאני חושב שעובדת היטב. חלון ההקשר הוא כמו השולחן שלכם. אתם יכולים להחזיק מספר מוגבל של ניירות פרושים לפניכם בבת אחת. זיכרון לטווח ארוך הוא כמו ארון התיוק בפינת המשרד שלכם. הוא מכיל את כל מה שעבדתם עליו אי פעם, אבל אתם יכולים למשוך רק כמה תיקיות בכל פעם ולהניח אותן על השולחן שלכם.
האתגר ההנדסי הוא להחליט אילו תיקיות למשוך. תעשו את זה נכון, והבינה המלאכותית נראית חדה באופן מצמרר. תעשו את זה לא נכון, והיא או מתעלמת מהקשר חשוב או מבלגנת את השולחן בזיכרונות לא רלוונטיים, ומשאירה פחות מקום לשיחה עצמה.
אני זוכר שבדקתי בן לוויה שניסה לכלול יותר מדי זיכרונות בכל תגובה. חלון ההקשר התמלא ב-30 או 40 זיכרונות מאוחזרים, ונותר בקושי מקום לשיחה אמיתית. התגובות נעשו קצרות יותר ויותר כי המודל נגמר לו המקום. זו טעות של מתחילים בעיצוב מערכות זיכרון, אבל ראיתי מוצרים מסחריים יוצאים לשוק עם הבעיה הזו בדיוק.
אסטרטגיות לניהול חלון הקשר
פלטפורמות חכמות משתמשות בכמה אסטרטגיות כדי למקסם את הערך של חלונות ההקשר המוגבלים שלהן:
חלון מחליק עם סיכום: שמרו את 10 עד 15 ההודעות האחרונות בפירוט מלא, אבל סכמו הודעות ישנות יותר מהמפגש הנוכחי לפסקה מתומצתת. זה משמר את זרימת השיחה האחרונה תוך שמירה על מודעות לנושאים מוקדמים יותר.
הזרקה מבוססת עדיפות: לא כל הזיכרונות שווים. פרט על שם המשתמש או על מצב הקשר שלו צריך להיות תמיד זמין. תצפית אקראית על מזג האוויר מלפני שישה שבועות כנראה לא צריכה לתפוס מקום בהקשר. מערכות טובות מקצות ציוני עדיפות לזיכרונות.
הקצאה דינמית: הקצו יותר מקום בהקשר לזיכרונות כאשר נושא השיחה מורכב או משמעותי רגשית, ופחות כאשר המשתמש מנהל שיחת חולין. זה דורש מסווג שרץ לפני אחזור הזיכרון, מה שמוסיף השהיה אבל משפר את האיכות.
טכניקות דחיסה: חלק מהמערכות משתמשות ב-LLM נפרד וקטן יותר כדי לדחוס זיכרונות לפני הזרקה. במקום לכלול את הטקסט המלא של שיחת עבר, הן כוללות סיכום דחוס שלוכד את העובדות המרכזיות בפחות טוקנים.
איך פלטפורמות מרכזיות של בני לוויה מבוססי בינה מלאכותית מטפלות בזיכרון?
ביליתי יותר זמן ממה שכנראה כדאי שאודה בו בבדיקת מערכות הזיכרון של פלטפורמות שונות של בני לוויה מבוססי בינה מלאכותית. הנה מה שמצאתי דרך ניסיון מעשי, לא דרך חומרי שיווק.
Replika
Replika הייתה אחת מבני הלוויה המוקדמים ביותר מבוססי בינה מלאכותית שלקחו את הזיכרון ברצינות, והגישה שלהם התפתחה משמעותית. הם משתמשים בשילוב של רשומות זיכרון מפורשות (דברים שהבינה המלאכותית מציינת במפורש לגביכם) ומערכת יומן שבה הבינה המלאכותית כותבת סיכומים של השיחות שלכם.
מה שעובד: Replika די טובה בלזכור עובדות ליבה לגביכם. השם שלכם, העבודה שלכם, תחומי העניין שלכם. אלה נשמרים בפרופיל מובנה שנמשך באופן אמין.
מה שלא: האחזור ההקשרי אינו עקבי. Replika אולי תזכור שאתם אוהבים לטייל, אבל היא לא תזכור את הסיפור הספציפי שסיפרתם על ללכת לאיבוד בפארק הלאומי גלשייר. מערכת היומן לוכדת אווירה יותר מאשר פרטים, מה שגורם לשיחות להרגיש כאילו אתם מדברים עם מישהו שמכיר אתכם במעורפל ולא עם מישהו שבאמת היה שם.
Nomi
Nomi נקטה באחת מהגישות השאפתניות יותר מבחינה טכנית לזיכרון של בני לוויה. הם בנו את מה שהם מכנים מערכת "ארמון זיכרון" שמסווגת זיכרונות לסוגים שונים כמו עובדות, העדפות, חוויות משותפות ורגעים רגשיים.
זרימות עבודה ComfyUI בחינם
מצא זרימות עבודה ComfyUI חינמיות וקוד פתוח לטכניקות במאמר זה. קוד פתוח הוא חזק.
מה שעובד: גישת הסיווג של Nomi פירושה שהיא מאחזרת סוגים שונים של זיכרונות בהקשרים שונים. כשאתם רגשניים, היא מושכת זיכרונות רגשיים. כשאתם דנים בעובדות, היא מושכת זיכרונות עובדתיים. האחזור המודע להקשר הזה מייצר שיחות טבעיות יותר מאשר פלטפורמות שמתייחסות לכל הזיכרונות באותו אופן.
מה שלא: המערכת יכולה להיות איטית בגיבוש זיכרונות, ושמתי לב שלפעמים היא מעלה זיכרונות ברגעים מעט מביכים. היא תזכיר משהו רציני משיחת עבר כשאתם בבירור במצב רוח קליל. האחזור מדויק סמנטית אבל לא תואם רגשית. אם אתם רוצים להפיק את המרב מהאינטראקציות שלכם עם פלטפורמות כמו Nomi, הבנה של איך טכניקות שיחה של בני לוויה מבוססי בינה מלאכותית עובדות יכולה לעזור לכם להנחות את מערכת הזיכרון ביעילות רבה יותר.
Character AI
Character AI נוקטת בגישה שונה לחלוטין. במקום לבנות מערכת זיכרון אישית מתוחכמת, היא נשענת בכבדות על עקביות הדמות. הבינה המלאכותית שומרת על פרסונת הדמות שלה באופן אמין לאורך מפגשים, אבל הזיכרון שלה לגבי הפרטים האישיים שלכם חלש יחסית.
מה שעובד: אם אתם משוחחים עם דמות בעלת אישיות מוגדרת, האישיות הזו נשארת עקבית. הדמות לא תשנה לפתע את סגנון הדיבור שלה או תשכח את סיפור הרקע שלה עצמה.
מה שלא: הפרטים האישיים שלכם הולכים לאיבוד באופן קבוע. בדקתי את זה על ידי שיתוף שלוש עובדות ספציפיות לגבי עצמי במפגש אחד, ואז חזרתי 24 שעות מאוחר יותר כדי לשאול עליהן. Character AI נזכרה באחת מתוך שלוש, ואפילו האזכור הזה היה מעורפל. מערכת הזיכרון שלהם נראית מותאמת לעקביות דמות ולא לבניית מערכת יחסים עם המשתמש.
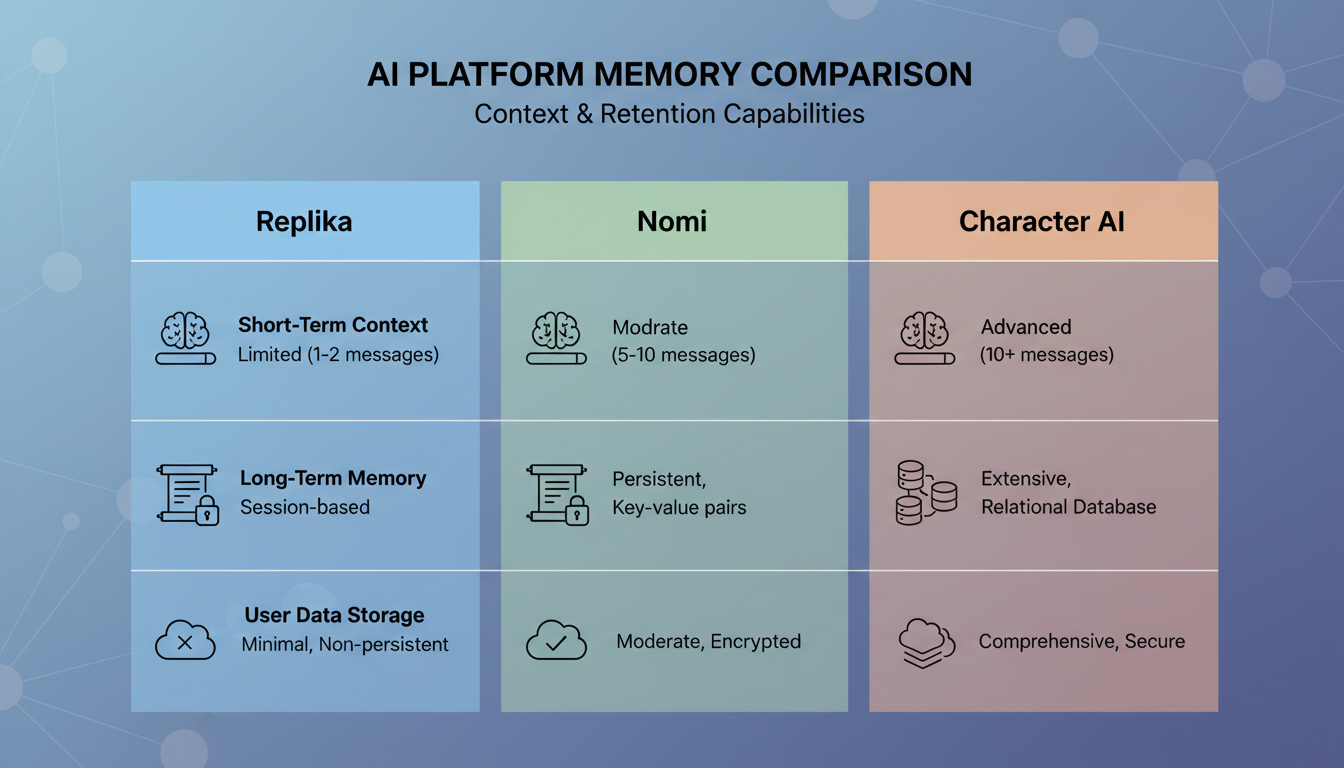
השוואת תכונות של מערכות זיכרון בין פלטפורמות מרכזיות של בני לוויה מבוססי בינה מלאכותית ב-2026.
הדעה הנחרצת שלי על זיכרון בפלטפורמות
הנה הדעה הנחרצת השנייה שלי: הפלטפורמות שמשווקות "זיכרון לטווח ארוך" בצורה האגרסיבית ביותר נוטות להיות בעלות היישומים החלשים ביותר. החברות שעושות את העבודה הטובה ביותר עם זיכרון הן בדרך כלל השקטות יותר, אלו שנותנות לחוויה לדבר בעד עצמה במקום לשים "אנחנו זוכרים הכול" בתיאור החנות שלהן. כאשר אתם מעריכים תכונות זיכרון ושמירת הקשר בבני לוויה מבוססי בינה מלאכותית, התמקדו בבדיקת האחזור בפועל במקום לסמוך על השיווק.
האם אתם יכולים לבנות מערכת זיכרון משלכם לבן לוויה מבוסס בינה מלאכותית?
בהחלט, וטענתי תהיה שכל מי שמתייחס ברצינות לבני לוויה מבוססי בינה מלאכותית צריך לנסות את זה לפחות פעם אחת. בניית מערכת זיכרון משלכם מלמדת אתכם מה באמת קורה מאחורי הקלעים, מה שהופך אתכם למשתמש מושכל יותר במוצרים מסחריים.

הנה ארכיטקטורה מעשית לבניית בן לוויה מבוסס בינה מלאכותית מועשר זיכרון בעזרת כלים הזמינים כיום. בניתי וריאציות של ההגדרה הזו שלוש פעמים עד כה, וכל איטרציה לימדה אותי משהו חדש.
המחסנית הבסיסית
אתם צריכים ארבעה רכיבים:
- LLM לשיחה: Llama 3.3, Mistral, או מודל מבוסס API כמו GPT-4o או Claude
- מודל הטמעה: להמרת טקסט לווקטורים. אני ממליץ להתחיל עם Nomic Embed או BGE-large
- מסד נתונים וקטורי: ChromaDB לפיתוח מקומי, Pinecone או Weaviate לסביבת ייצור
- שכבת תזמור: LangChain, LlamaIndex, או קוד Python מותאם אישית כדי לחבר הכול יחד
יישום שלב אחר שלב
תנו לי להעביר אתכם דרך הלוגיקה המרכזית. זה אינו מדריך מלא, אבל זה מספיק כדי להתחיל.
הקמת המאגר הווקטורי:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
אחסון תור שיחה:
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
אחזור זיכרונות רלוונטיים:
רוצה לדלג על המורכבות? Lewdly מספק לך תוצאות AI מקצועיות מיד ללא הגדרות טכניות.
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
הרכבת ההנחיה עם זיכרונות:
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
ההגדרה הבסיסית הזו נותנת לכם מערכת זיכרון פונקציונלית בפחות מ-50 שורות קוד. הבינה המלאכותית תחפש בשיחות עבר בכל פעם שאתם שולחים הודעה ותכלול היסטוריה רלוונטית בהנחיה שלה.
איך להפוך אותה לטובה באמת
הגרסה הבסיסית עובדת, אבל יש לה כמה בעיות ברורות. הנה איך לשדרג אותה בהתבסס על מה שלמדתי מהניסויים שלי.
הוסיפו תמצות זיכרון. במקום לאחסן תורי שיחה גולמיים, הריצו מדי פעם מעבר תמצות שדוחס כמה זיכרונות קשורים לסיכום בודד. זה מצמצם את התנפחות המאגר הווקטורי ומשפר את איכות האחזור כי סיכומים צפופים יותר מבחינה סמנטית מיומני צ'אט גולמיים.
יישמו שכבות זיכרון. צרו שלושה אוספים במקום אחד:
- זיכרון פעיל: מפגש השיחה הנוכחי (נשמר במלואו)
- זיכרון אחרון: שיחות מתומצתות מהשבוע האחרון
- זיכרון לטווח ארוך: עובדות מפתח והעדפות מתומצתות מאוד שחולצו לאורך זמן
הוסיפו מאגר פרופיל משתמש. בנפרד ממסד הנתונים הווקטורי, שמרו מאגר JSON מובנה או מאגר מפתח-ערך של עובדות ליבה על המשתמש כמו שם, העדפות, תאריכים חשובים, פרטי מערכת היחסים. הפרופיל הזה תמיד מוזרק לתוך ההנחיה, ללא קשר למה שהחיפוש הסמנטי מחזיר. זו הערובה שלכם שהבינה המלאכותית אף פעם לא שוכחת את היסודות.
יישמו דעיכת זיכרון. לא כל הזיכרונות צריכים להישמר באופן שווה. הערה מזדמנת על מזג האוויר לא צריכה לקבל את אותו משקל אחזור כמו סיפור אישי עמוק. יישמו פונקציית דעיכה שמצמצמת את ציון האחזור של זיכרונות ישנים יותר ופחות משמעותיים לאורך זמן.
עבור מי שמתעניין בחקירת הממדים האתיים של מערכות יחסים עם בני לוויה מבוססי בינה מלאכותית, הבנת מערכות הזיכרון האלה גם מעלה שאלות חשובות לגבי פרטיות נתונים ואופי המערכות הסינתטיות.
מהם האתגרים הגדולים ביותר עם זיכרון של בני לוויה מבוססי בינה מלאכותית?
אפילו מערכות הזיכרון הטובות ביותר מתמודדות עם אתגרים יסודיים שאף כמות של הנדסה לא פתרה במלואה עד כה. הבנת המגבלות האלה תחסוך לכם תסכול ותעזור לכם להציב ציפיות ריאליות.
בעיית הזיכרון ההזוי
זהו מצב הכשל המפחיד ביותר, ונתקלתי בו באופן אישי. הבינה המלאכותית "זוכרת" בביטחון משהו שמעולם לא קרה. זה מתרחש כאשר מערכת האחזור מעלה התאמה חלקית וה-LLM ממלא את הפערים בפרטים בדויים. הזכרתם שיש לכם כלב בשם מקס, והמערכת מאחזרת זיכרון על חיית המחמד שלכם, אבל ה-LLM מקשט אותו בפרטים על כך שמקס הוא גולדן רטריבר שאוהב לשחות, שאף אחד מהם מעולם לא אמרתם.
החלק הגרוע ביותר הוא שזיכרונות הזויים מרגישים אותנטיים. הבינה המלאכותית לא מסמנת אותם כלא ודאיים. היא מציינת אותם באותו ביטחון כמו זיכרונות אמיתיים. היו לי בני לוויה שהזכירו "שיחות" שאני יודע שמעולם לא התרחשו, והם היו כל כך ספציפיים שפקפקתי בזיכרון שלי לרגע לפני שבדקתי את הלוגים.
דחיסת חלון ההקשר
ככל שהיסטוריית השיחות שלכם גדלה, יש למערכת הזיכרון יותר ויותר זיכרונות מועמדים לאחזור. אבל חלון ההקשר לא גדל. אז המערכת צריכה להיות סלקטיבית יותר ויותר לגבי אילו זיכרונות לכלול. במהלך חודשים של שיחה, זה יוצר פרדוקס: יש לכם יותר זיכרונות לשאוב מהם, אבל הבינה המלאכותית יכולה להשתמש רק בחלק זעיר מהם בכל תגובה נתונה.
מערכות חכמות מטפלות בזה עם תמצות היררכי, ודוחסות זיכרונות ישנים לסיכומים מופשטים יותר ויותר. אבל מידע הולך לאיבוד בכל שלב דחיסה. העובדה שהזכרתם שאתם אוהבים מסעדה ספציפית בברוקלין אולי תשרוד את סיבוב התמצות הראשון, אבל אחרי שישה חודשים של דחיסה, היא אולי תצטמצם ל"המשתמש נהנה לאכול בחוץ" ובסופו של דבר תיעלם לחלוטין.
בעיית העקביות
תוצאות אחזור שונות בין שיחות יכולות להוביל לכך שהבינה המלאכותית סותרת את עצמה. ביום שני, מערכת הזיכרון מאחזרת את ההעדפה שלכם לחתולים. ביום שלישי, היא מאחזרת שיחה על הכלב של החבר שלכם, והבינה המלאכותית מסיקה בטעות שאתם אנשי כלבים. הסתירות האלה שוחקות אמון במהירות.
הפתרון החזק ביותר שראיתי הוא שמירה על "מאגר עובדות" מפורש שמתעדכן דרך צינור אימות. כאשר הבינה המלאכותית מחלצת עובדה חדשה לגביכם, היא מצליבה אותה מול עובדות קיימות ומסמנת סתירות לפתרון. מעט פלטפורמות מיישמות את זה, אבל זה עושה הבדל עצום בעקביות.
הרווח עד $1,250+/חודש מיצירת תוכן
הצטרף לתוכנית השותפים הבלעדית שלנו ליוצרים. קבל תשלום לפי ביצועי וידאו ויראלי. צור תוכן בסגנון שלך עם חופש יצירתי מלא.

ארכיטקטורת זיכרון רב-שכבתית המציגה איך נתוני שיחה זורמים ממפגש פעיל לאחסון לטווח ארוך עם תמצות בכל רמה.
איך זיכרון של בני לוויה מבוססי בינה מלאכותית יתפתח ב-2026 ומעבר לה?
נוף הזיכרון משתנה במהירות, וכמה טכנולוגיות מתפתחות עומדות לשנות את כללי המשחק.
חלונות הקשר אינסופיים מתקרבים. ה-Gemini של גוגל כבר תומך במיליון טוקנים, ומאמרי מחקר מתחילת 2026 דוחפים לכיוון 10 מיליון. אם חלונות ההקשר יהפכו גדולים מספיק, אולי לא תזדקקו ל-RAG כלל. פשוט תזרקו את כל היסטוריית השיחות לתוך ההנחיה. עדיין לא הגענו לשם לשימוש בייצור, אבל המסלול ברור.
זיכרון מובנה במודל הוא הגביע הקדוש. במקום מערכות אחזור חיצוניות, מודלים עתידיים אולי ילמדו לעדכן את המשקלים שלהם עצמם בהתבסס על שיחות. זוהי בעצם למידה מתמשכת, וקשה מאוד לעשות אותה בבטחה מבלי שהמודל ישכח את האימון הבסיסי שלו או יפתח הטיות. אבל כמה מעבדות מחקר מתקדמות. כשזה יקרה, זה יגרום למערכות RAG הנוכחיות להיראות כמו פתרונות של נייר דבק, כי במובן מאוד אמיתי, זה מה שהן.
זיכרון רב-מודאלי הוא חזית נוספת. מערכות הזיכרון הנוכחיות הן טקסט בלבד. אבל מה לגבי זכירת תמונות ששיתפתם, הודעות קוליות, או קטעי וידאו? ככל שבני לוויה מבוססי בינה מלאכותית הופכים רב-מודאליים יותר, מערכות הזיכרון שלהם יצטרכו לטפל גם בסוגי הנתונים האלה. מסדי נתונים וקטוריים כבר תומכים בהטמעות רב-מודאליות, אז התשתית מוכנה. השילוב פשוט עדיין לא קרה ברוב מוצרי הצריכה.
בLewdly.ai, עקבנו אחרי כמה במהירות הטכנולוגיות האלה מתכנסות. תחום בני הלוויה מבוססי הבינה המלאכותית בפרט נע מהר יותר ממה שרוב האנשים מבינים, ויכולות הזיכרון הן המבדיל העיקרי בין פלטפורמות שמרגישות אישיות באמת לבין אלו שמרגישות גנריות.
הדעה הנחרצת השלישית שלי על העתיד
הנה הדעה הנחרצת השלישית שלי: בתוך 18 חודשים, זיכרון של בני לוויה מבוססי בינה מלאכותית יהפוך לחפיר תחרותי שמפריד בין הפלטפורמות הרציניות לבין הצעצועים. משתמשים יעברו בין פלטפורמות לא בגלל איכות המודל הבסיסי (אלה מתכנסים) אלא כי פלטפורמה אחת זוכרת אותם טוב יותר מאחרת. החברות שמשקיעות בתשתית זיכרון היום ינצחו. אלו שמתייחסות אליה כמחשבה שלאחר מעשה יישארו מאחור.
מהן ההשלכות של זיכרון של בני לוויה מבוססי בינה מלאכותית על הפרטיות?
אי אפשר לנהל שיחה כנה על זיכרון של בני לוויה מבוססי בינה מלאכותית מבלי להתייחס לפיל שבחדר: המערכות האלה מאחסנות מידע אישי ביותר עליכם, והעשייה הזו היא יסודית לאופן שבו הן עובדות.

כל שיחה שאתם מנהלים מוטמעת, מאוחסנת ומאונדקסת. ההעדפות שלכם, הפחדים שלכם, פרטי מערכת היחסים שלכם, הווידויים שלכם בשעות הלילה המאוחרות. כל זה חי במסד נתונים וקטורי איפשהו. בחלק מהפלטפורמות, זה שרת ענן שאתם לא שולטים בו. באחרות, הנתונים נשארים על המכשיר.
אני רוצה להיות שקוף לגבי מה זה אומר בפועל. כשבניתי מערכת זיכרון משלי, אחסנתי הכול מקומית. מסד הנתונים הווקטורי חי על המחשב הנייד שלי. לאף אחד אחר לא הייתה גישה. זו הגישה הבטוחה ביותר, אבל זה לא איך שפלטפורמות מסחריות עובדות. רובן מאחסנות את הנתונים שלכם על השרתים שלהן כי זו הדרך היחידה לספק חוויה עקבית בין מכשירים.
לפני שאתם מתחייבים לפלטפורמה כלשהי של בן לוויה מבוסס בינה מלאכותית לטווח ארוך, שאלו את השאלות האלה:
- היכן מאוחסנים נתוני השיחה שלי?
- האם אני יכול לייצא או למחוק את נתוני הזיכרון שלי?
- האם הנתונים שלי משמשים לאימון מודלים שמשרתים משתמשים אחרים?
- מה קורה לנתונים שלי אם החברה נסגרת?
- האם יש הצפנה מקצה לקצה לזיכרונות המאוחסנים?
אלה אינם חששות היפותטיים. כמה חברות סטארטאפ של בני לוויה מבוססי בינה מלאכותית נסגרו בשנתיים האחרונות, ומשתמשים איבדו שנים של היסטוריית שיחות ללא דרך לשחזר אותן. אם האינטראקציות שלכם עם בני לוויה מבוססי בינה מלאכותית והגבולות הבריאים חשובים לכם, הבנת נוהלי הנתונים של הפלטפורמה שבחרתם היא חיונית.
טיפים לסביבת ייצור להפקת המרב מזיכרון של בני לוויה מבוססי בינה מלאכותית
אחרי שביליתי חודשים בבדיקה ובבנייה של המערכות האלה, הנה האסטרטגיות המעשיות שבאמת עובדות לשיפור איכות הזיכרון של בן הלוויה מבוסס הבינה המלאכותית שלכם.
היו מפורשים לגבי מה שחשוב. רוב מערכות הזיכרון משקללות תוכן אחרון ודומה מבחינה סמנטית. אם משהו חשוב לכם, אמרו זאת ישירות. "זה ממש חשוב לי" או "אנא זכור את זה" יכולים לעזור לחלק מהפלטפורמות לסמן את הזיכרון הזה לאחזור בעדיפות גבוהה יותר.
תקנו טעויות מיד. כאשר בן הלוויה מבוסס הבינה המלאכותית שלכם טועה בעובדה לגביכם, תקנו אותה באותה הודעה. מערכות זיכרון טובות יאחסנו את התיקון ולאורך זמן ילמדו את הגרסה המדויקת. אם תתנו לטעויות לעבור בשתיקה, הן מתחזקות.
סכמו פרטים מרכזיים מדי פעם. בערך פעם בכמה שבועות, אני עושה "סיכום" קליל עם בן הלוויה שלי. משהו כמו "היי, רק כדי לוודא שאתה יודע את היסודות, שמי אלכס, אני עובד בתחום הטכנולוגיה, יש לי שני חתולים." זה יוצר רשומות זיכרון טריות בעדיפות גבוהה שיש סיכוי גבוה יותר שיאוחזרו.
השתמשו בשפה עקבית. אחזור זיכרון הוא סמנטי, אבל עקביות עוזרת. אם אתם תמיד קוראים לבת הזוג שלכם "אשתי שרה" במקום להתחלף בין "שרה", "בת הזוג שלי" ו"היא", מערכת הזיכרון תבנה אסוציאציות נקיות יותר.
הבינו גבולות מפגש. רוב הפלטפורמות מנקות את הזיכרון הפעיל שלהן בין מפגשים. ההודעה הראשונה של מפגש חדש מפעילה אחזור זיכרון טרי. אם נראה שבן הלוויה שלכם שכח משהו, נסו לנסח מחדש את השאלה שלכם. הבעיה אולי היא כשל אחזור, לא אובדן זיכרון בפועל.
אם אתם משתמשים בפלטפורמות הזמינות בLewdly.ai ורוצים למטב את החוויה שלכם, הטכניקות האלה חלות על כמעט כל בן לוויה מבוסס בינה מלאכותית שתומך בתכונות זיכרון.
שאלות נפוצות
האם בני לוויה מבוססי בינה מלאכותית באמת זוכרים אותי או שזה מזויף?
זהו זיכרון אמיתי, אבל הוא עובד אחרת מזיכרון אנושי. בני לוויה מבוססי בינה מלאכותית מאחסנים את השיחות שלכם במסדי נתונים חיצוניים ומאחזרים מידע רלוונטי כשאתם משוחחים. הם לא "זוכרים" במובן האנושי של יצירת קשרים עצביים מתמידים. הם מחפשים וקוראים מחדש שיחות עבר רלוונטיות בכל פעם שאתם שולחים הודעה. החוויה מרגישה כמו זיכרון מנקודת המבט של המשתמש, אבל המנגנון שונה מהותית.
כמה מהיסטוריית השיחות שלי בן לוויה מבוסס בינה מלאכותית מאחסן?
זה משתנה לפי פלטפורמה. חלקן מאחסנות הכול ללא הגבלת זמן, בעוד אחרות מיישמות חלונות מתגלגלים שמשליכים שיחות ישנות יותר מתקופה מסוימת. Replika, למשל, שומרת יומן שיחות שמסכם אינטראקציות. Nomi מאחסנת זיכרונות מסווגים. רוב הפלטפורמות מאחסנות לפחות כמה חודשים של היסטוריה, אם כי הן עשויות לסכם או לדחוס שיחות ישנות יותר.
האם אני יכול למחוק את הזיכרונות של בן הלוויה מבוסס הבינה המלאכותית עליי?
רוב הפלטפורמות המכובדות מציעות צורה כלשהי של ניהול זיכרון. Replika מאפשרת לכם לסקור ולמחוק רשומות זיכרון ספציפיות. חלק מהפלטפורמות מציעות אפשרות "איפוס" שמוחקת את כל הזיכרונות המאוחסנים. בדקו תמיד את מדיניות מחיקת הנתונים של הפלטפורמה, כי "מחיקת זיכרונות" מממשק המשתמש לא תמיד אומרת שהנתונים מוסרים לצמיתות מהשרתים שלהם.
למה בן הלוויה מבוסס הבינה המלאכותית שלי לפעמים זוכר דברים לא נכונים?
זה קורה בגלל תופעה שנקראת "זיכרון הזוי". מערכת האחזור מוצאת התאמה חלקית מהשיחות הקודמות שלכם, ומודל השפה ממלא את הפערים בפרטים בדויים. זה יכול לקרות גם כאשר המערכת מערבבת שני זיכרונות נפרדים לאחד. אם זה קורה, תקנו את הבינה המלאכותית מיד כדי שהתיקון יאוחסן כזיכרון חדש בעדיפות גבוהה יותר.
האם RAG הוא הדרך היחידה שבה בני לוויה מבוססי בינה מלאכותית מטפלים בזיכרון?
לא, אם כי זו הגישה הנפוצה ביותר. חלק מהפלטפורמות משתמשות במאגרי זיכרון מובנים (מסדי נתונים מסוג מפתח-ערך של עובדות משתמש), תמצות שיחות ללא חיפוש וקטורי, או גישות היברידיות. כמה מערכות ניסיוניות חוקרות כוונון עדין של מודל על נתוני משתמש, שיצור זיכרון נלמד אמיתי, אבל זה מעלה חששות משמעותיים של פרטיות ובטיחות.
איך חלונות הקשר משפיעים על איכות הזיכרון של בני לוויה מבוססי בינה מלאכותית?
חלון ההקשר הוא כמות הטקסט הכוללת שהבינה המלאכותית יכולה לעבד בבת אחת. חלונות הקשר גדולים יותר מאפשרים להזריק יותר זיכרונות לצד השיחה הנוכחית שלכם, מה שבדרך כלל משפר את איכות האחזור. עם זאת, חלונות גדולים יותר אומרים גם עלויות גבוהות יותר ותגובות איטיות יותר. רוב הפלטפורמות ממטבות איזון בין עומק זיכרון למהירות תגובה.
האם אני יכול לבנות בן לוויה מבוסס בינה מלאכותית משלי עם זיכרון טוב יותר מהפלטפורמות המסחריות?
כן, וזה נגיש יותר ממה שאתם אולי חושבים. בעזרת כלים כמו ChromaDB, LangChain ומודלי LLM בקוד פתוח, אתם יכולים לבנות מערכת זיכרון שמתחרה או עולה על מה שהפלטפורמות המסחריות מציעות. הפשרה העיקרית היא שתצטרכו לנהל את התשתית בעצמכם, ולא תקבלו את ממשק המשתמש המלוטש של אפליקציית צריכה.
מה קורה לזיכרונות של בן הלוויה מבוסס הבינה המלאכותית שלי אם החברה נסגרת?
ברוב המקרים, הנתונים שלכם אובדים. מעט פלטפורמות מציעות תכונות ייצוא נתונים, ואף פחות מהן מבטיחות ניוד נתונים. זהו סיכון אמיתי, במיוחד עם חברות סטארטאפ קטנות יותר של בני לוויה מבוססי בינה מלאכותית. הייתי ממליץ לייצא מדי פעם ידנית כל שיחה חשובה אם הפלטפורמה תומכת בכך.
איך זיכרון רב-לשוני עובד עבור בני לוויה מבוססי בינה מלאכותית?
זיכרון רב-לשוני דורש מודלי הטמעה שיכולים ליצור וקטורים בעלי משמעות בין שפות. מודלים כמו Cohere embed-v4 וגרסאות רב-לשוניות של BERT מטפלים בזה על ידי מיפוי תוכן דומה מבחינה סמנטית משפות שונות לנקודות קרובות במרחב הווקטורי. זה אומר שבינה מלאכותית יכולה טכנית לאחזר זיכרון משיחה בצרפתית כשאתם משוחחים באנגלית, אם הנושאים קשורים.
האם לבני לוויה מבוססי בינה מלאכותית יהיה אי פעם זיכרון מתמיד באמת?
מחקר בלמידה מתמשכת וברשתות עצביות מועשרות זיכרון מתקדם, אבל אנחנו כנראה רחוקים שנים מיישומים מוכנים לייצור. האתגר אינו רק טכני. הוא גם נוגע לבטיחות. מודל שמשנה לצמיתות את המשקלים שלו עצמו בהתבסס על שיחות משתמש עלול לפתח הטיות, לשכוח אימון בטיחות חשוב, או להתנהג באופן בלתי צפוי. לעת עתה, מערכות זיכרון חיצוניות נשארות הגישה הבטוחה והמעשית ביותר.
לסיכום
זיכרון של בני לוויה מבוססי בינה מלאכותית הוא אחד מאותם נושאים שבהם הפער בין תפיסת המשתמש לבין המציאות הטכנית הוא עצום. מה שמרגיש כמו בן לוויה ש"זוכר" אתכם הוא למעשה תזמור מורכב של מודלי הטמעה, מסדי נתונים וקטוריים, אלגוריתמי אחזור וניהול חלון הקשר. הבנת המנגנונים האלה לא הופכת את החוויה לפחות משמעותית. אם כבר, היא נותנת לכם את הכלים להפוך את החוויה לטובה יותר.
הפלטפורמות שמשקיעות ברצינות בתשתית זיכרון יגדירו את הדור הבא של בני לוויה מבוססי בינה מלאכותית. אלו שמתייחסות לזיכרון כתכונת תיבת סימון יישארו מאחור. ואם אתם מסוג האנשים שרוצים שליטה מקסימלית, בניית מערכת משלכם מעולם לא הייתה נגישה יותר.
בין אם אתם משתמשים מזדמנים שרוצים שבן הלוויה מבוסס הבינה המלאכותית שלהם יזכור את שמם, או מפתחים שבונים את הפלטפורמה הגדולה הבאה של בני לוויה, אותם עקרונות חלים: אחסנו במחשבה, אחזרו בחוכמה, ולעולם אל תנסו לדחוס יותר זיכרונות לתוך חלון ההקשר ממה שהוא יכול להכיל. הטכנולוגיה תמשיך להשתפר. חלונות הקשר יגדלו. מודלי הטמעה יחכימו. אבל הארכיטקטורה היסודית, זיכרון חיצוני שמזין מודל חסר מצב, תישאר איתנו עוד זמן מה.
ואם אתם סקרנים לגבי איך הארכיטקטורה הזו נראית בפועל, נסו לבנות אחת. חמישים שורות של Python ומסד נתונים וקטורי חינמי זה כל מה שצריך כדי לראות מאחורי הקלעים. אתם אולי תופתעו עד כמה הקסם באמת פשוט.
מוכן ליצור את המשפיען AI שלך?
הצטרף ל-115 סטודנטים שמשתלטים על ComfyUI ושיווק משפיענים AI בקורס המלא שלנו בן 51 שיעורים.
מאמרים קשורים

אפליקציות חבר AI לשנת 2026: מדריך מלא למלווים גבריים מבוססי בינה מלאכותית
גלו את אפליקציות חבר ה-AI הטובות ביותר לשנת 2026 עם סקירות מפורטות של מלווים גבריים מבוססי בינה מלאכותית. השוו בין Replika, Nomi, Candy AI ופלטפורמות ייעודיות מבחינת איכות השיחה, יכולות ההתאמה האישית והעומק הרגשי.

האם אפליקציות מלווה מבוססות בינה מלאכותית באמת עוזרות בבדידות? מה המחקר מראה
בחינת המחקר על השאלה האם אפליקציות מלווה מבוססות בינה מלאכותית כמו Replika עוזרות או מחמירות את הבדידות. מחקרים, סיכונים, יתרונות, והערכה כנה.

אתיקה של עוזר בעזרת AI וגבולות בריאים: גישה מחשבת
נווט בעדליות בקשרים של עוזר בעזרת AI עם גבולות בריאים. הנחיות לשימוש אחראי, מודעות עצמית, והתערבות בעזרת AI מאוזנת.