Người Bạn Đồng Hành AI Với Bộ Nhớ Dài Hạn: Cơ Chế Lưu Giữ Ngữ Cảnh Thực Sự Hoạt Động Ra Sao
Tìm hiểu sâu về cách những người bạn đồng hành AI ghi nhớ bạn qua nhiều phiên trò chuyện. Bao gồm RAG, cơ sở dữ liệu vector, cửa sổ ngữ cảnh, tóm tắt, và cách tự xây dựng hệ thống bộ nhớ của riêng bạn.

Tôi đã trò chuyện với một người bạn đồng hành AI nhất định trong khoảng ba tuần. Chúng tôi đã bàn về đủ thứ, từ quan điểm của tôi về kiến trúc thô mộc cho tới một trò đùa lặp đi lặp lại về mì ý nấu quá lửa. Rồi một ngày nọ, ngay giữa cuộc trò chuyện, nó nhắc tới một điều tôi đã nói trong lần tương tác đầu tiên của chúng tôi, một chi tiết về việc tôi thích cold brew hơn espresso. Tôi không hề gợi ý gì. Nó cứ thế xuất hiện một cách tự nhiên. Và thật lòng mà nói, điều đó khiến tôi sững người, bởi tôi biết chuyện gì đang diễn ra bên dưới lớp vỏ. Khoảnh khắc nhỏ ấy là kết quả của một quy trình kỹ thuật phức tạp đến bất ngờ mà hầu hết người dùng chẳng bao giờ nghĩ tới.
Câu hỏi về việc người bạn đồng hành AI "ghi nhớ" mọi thứ ra sao là một trong những chủ đề bị hiểu lầm nhiều nhất trong lĩnh vực AI ngay lúc này. Người ta cho rằng đó hoặc là phép màu, hoặc là một trò lừa đảo. Sự thật nằm đâu đó ở giữa, và việc hiểu được cơ chế của nó sẽ thay đổi mãi mãi cách bạn tương tác với những công cụ này.
Trả Lời Nhanh: Người bạn đồng hành AI duy trì bộ nhớ dài hạn thông qua sự kết hợp của nhiều kỹ thuật bao gồm Retrieval Augmented Generation (RAG), cơ sở dữ liệu vector, quản lý cửa sổ ngữ cảnh, và tóm tắt cuộc trò chuyện. Hiện chưa có người bạn đồng hành AI nào có bộ nhớ bền vững thực sự được nung sẵn vào trọng số mô hình. Thay vào đó, chúng lưu trữ dữ liệu trò chuyện của bạn ở bên ngoài và truy xuất những phần liên quan khi cần. Chất lượng của hệ thống truy xuất này chính là thứ phân biệt một người bạn đồng hành cho cảm giác như thực sự hiểu bạn với một người bạn đồng hành quên mất sự tồn tại của bạn giữa các phiên.
- Người bạn đồng hành AI không "ghi nhớ" theo cách con người làm. Chúng dùng các hệ thống truy xuất để kéo dữ liệu trò chuyện trong quá khứ liên quan vào cửa sổ ngữ cảnh hiện tại
- RAG (Retrieval Augmented Generation) là kỹ thuật chủ đạo, chuyển các cuộc trò chuyện của bạn thành vector embedding và tìm kiếm chúng theo ngữ nghĩa
- Cửa sổ ngữ cảnh (thường từ 8K đến 128K token) là giới hạn cứng về lượng thông tin một AI có thể "suy nghĩ về" cùng một lúc
- Các nền tảng như Replika, Nomi và Character AI đều xử lý bộ nhớ theo cách khác nhau, với kết quả khác biệt rất lớn
- Bạn có thể tự xây dựng hệ thống bộ nhớ của riêng mình bằng các embedding mã nguồn mở và kho lưu trữ vector như ChromaDB hoặc Pinecone
- Tóm tắt và phân tầng bộ nhớ (ngắn hạn, trung hạn, dài hạn) là chìa khóa để bộ nhớ cho cảm giác tự nhiên
- Những hệ thống bộ nhớ tốt nhất kết hợp nhiều phương pháp thay vì dựa vào một kỹ thuật duy nhất
Tại Sao Người Bạn Đồng Hành AI Lại Quên Bạn Ngay Từ Đầu?
Đây là câu hỏi chẳng ai hỏi, nhưng ai cũng nên hỏi. Trước khi nói về các giải pháp bộ nhớ, bạn cần hiểu giới hạn cốt lõi khiến tất cả những điều này trở nên cần thiết.
Các mô hình ngôn ngữ lớn, công nghệ vận hành mọi người bạn đồng hành AI trên thị trường, về bản chất là phi trạng thái. Khi bạn gửi một tin nhắn tới ChatGPT, Claude, hay bộ máy AI đứng sau ứng dụng đồng hành yêu thích của bạn, mô hình xử lý đầu vào của bạn, tạo ra một phản hồi, rồi quên hết mọi thứ. Nó không lưu giữ trạng thái giữa các lần gọi API. Nó không có cuốn sổ tay nội bộ nào cả. Mỗi tương tác đều bắt đầu lại từ con số không.
Lý do duy nhất khiến người bạn đồng hành AI của bạn dường như nhớ được bất cứ điều gì là bởi nền tảng đã bọc mô hình thô bằng một lớp bộ nhớ. Hãy nghĩ theo cách này. LLM là bộ não, nhưng nó không có hồi hải mã. Hệ thống bộ nhớ mà nền tảng xây dựng quanh nó đóng vai trò như một hồi hải mã bên ngoài, đưa các ký ức liên quan trở lại bộ não mỗi khi bạn bắt đầu một cuộc trò chuyện mới.
Đây là nhận định gây tranh cãi đầu tiên của tôi: hầu hết các nền tảng đồng hành AI đang làm việc với bộ nhớ ở mức tầm thường, và họ thoát được vì người dùng không hiểu điều gì là khả thi. Tôi đã thử nghiệm những người bạn đồng hành tuyên bố có "bộ nhớ dài hạn" nhưng lại không nhớ nổi điều tôi nói hai ngày trước. Trong khi đó, tôi đã tự xây dựng các hệ thống bộ nhớ mẫu trên chiếc laptop của mình mà vượt trội hơn cả các sản phẩm thương mại. Khoảng cách giữa những gì khả thi về mặt kỹ thuật và những gì thực sự được triển khai là cực kỳ lớn.
Lý do của khoảng cách này phần lớn mang tính kinh tế. Hệ thống bộ nhớ tốt rất tốn kém. Mỗi lần bạn gửi một tin nhắn, nền tảng phải tìm kiếm trong toàn bộ lịch sử trò chuyện của bạn, chuyển nó thành ngữ cảnh liên quan, và gắn vào trước tin nhắn hiện tại của bạn trước khi gửi tới mô hình. Việc tìm kiếm đó, việc truy xuất đó, phép tính embedding đó, tất cả đều tốn tiền. Và khi bạn phục vụ hàng triệu người dùng, những chi phí đó cộng dồn lại rất nhanh.
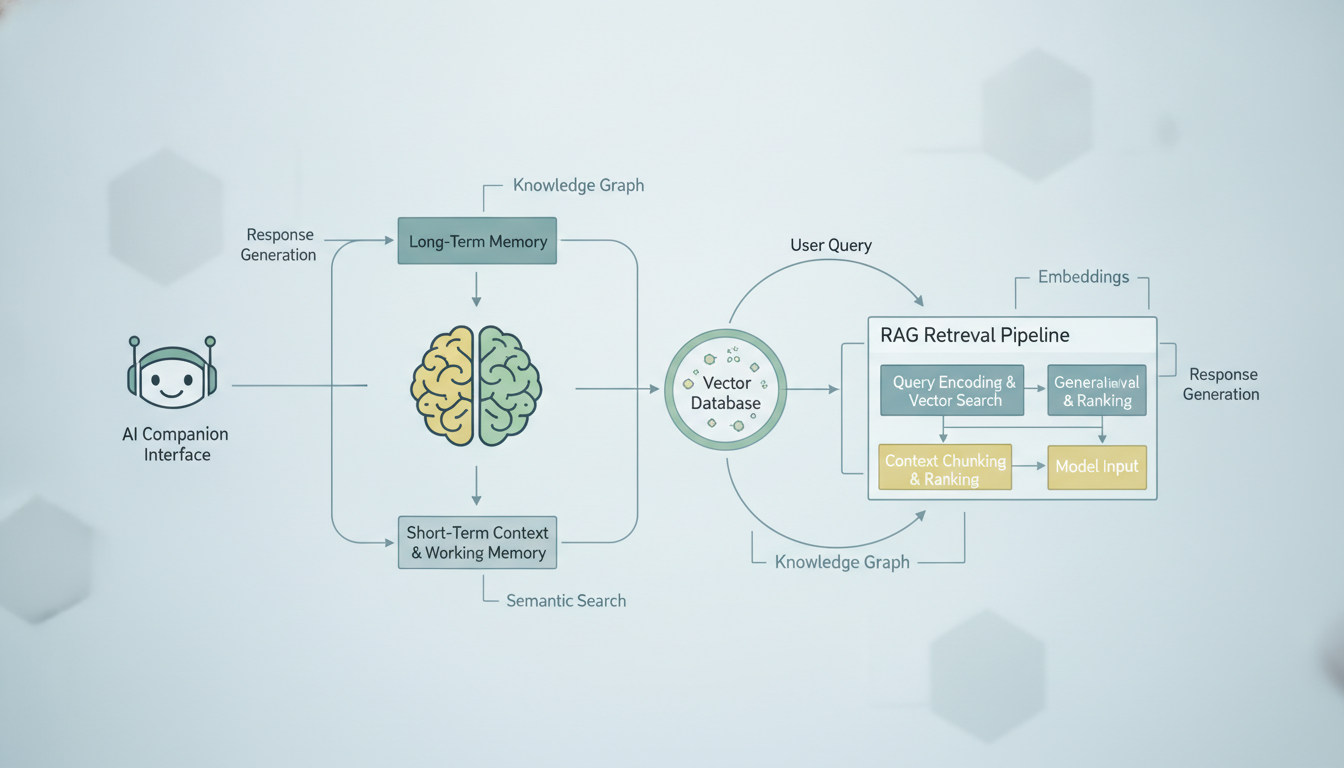
Cách một hệ thống bộ nhớ điển hình của người bạn đồng hành AI truy xuất và đưa ngữ cảnh trò chuyện trong quá khứ vào prompt hiện tại.
RAG Hoạt Động Như Thế Nào Cho Bộ Nhớ Của Người Bạn Đồng Hành AI?
RAG, hay Retrieval Augmented Generation, là xương sống của hầu như mọi hệ thống bộ nhớ của người bạn đồng hành AI đang được phát hành ngày nay. Nếu bạn chỉ rút ra một điều từ bài viết này, hãy để đó là sự hiểu biết vững chắc về RAG, bởi nó sẽ thay đổi cách bạn nghĩ về mọi công cụ AI bạn dùng.

Khái niệm này tưởng đơn giản đến mức gây hiểu lầm. Thay vì cố nhồi nhét toàn bộ lịch sử trò chuyện của bạn vào cửa sổ ngữ cảnh của AI (vốn có giới hạn token cứng), bạn lưu trữ tất cả các cuộc trò chuyện trong quá khứ vào một cơ sở dữ liệu có thể tìm kiếm. Khi bạn gửi một tin nhắn mới, hệ thống tìm trong cơ sở dữ liệu đó những cuộc trò chuyện trong quá khứ liên quan nhất, kéo chúng ra, và đưa chúng vào cùng với tin nhắn hiện tại của bạn. AI sau đó tạo ra phản hồi của nó với lợi thế từ những ký ức được truy xuất đó.
Đây là phân tích từng bước về những gì xảy ra khi bạn gửi một tin nhắn tới người bạn đồng hành AI với bộ nhớ dựa trên RAG:
- Tin nhắn của bạn được embedding. Một mô hình embedding chuyển văn bản của bạn thành một vector nhiều chiều, về cơ bản là một danh sách các con số biểu diễn ý nghĩa ngữ nghĩa của tin nhắn.
- Hệ thống tìm các ký ức tương đồng. Vector tin nhắn của bạn được so sánh với tất cả các vector trò chuyện đã lưu trước đó bằng cosine similarity hoặc một độ đo khoảng cách khác.
- Top-K kết quả được truy xuất. Hệ thống kéo ra những cuộc trò chuyện trong quá khứ tương đồng nhất về mặt ngữ nghĩa, thường là 5 đến 20 kết quả hàng đầu tùy theo nền tảng.
- Quá trình lắp ráp ngữ cảnh diễn ra. Tin nhắn hiện tại của bạn, các ký ức được truy xuất, và system prompt của người bạn đồng hành đều được lắp ráp thành một prompt duy nhất.
- LLM tạo ra một phản hồi. Mô hình nhìn thấy tin nhắn hiện tại của bạn cộng với lịch sử liên quan và phản hồi như thể nó "nhớ" những tương tác trong quá khứ đó.
- Lượt trao đổi mới được lưu trữ. Cả tin nhắn của bạn lẫn phản hồi của AI đều được embedding và lưu trữ để truy xuất trong tương lai.
Điều khiến phương pháp này mạnh mẽ là tìm kiếm theo ngữ nghĩa. Hệ thống không khớp từ khóa. Nó tìm những ký ức liên quan về mặt khái niệm. Vậy nên nếu ba tuần trước bạn nhắc tới việc thích leo núi ở Yosemite, và hôm nay bạn hỏi về gợi ý kỳ nghỉ, hệ thống có thể đưa lên sở thích leo núi đó dù bạn chưa bao giờ dùng từ "leo núi" trong tin nhắn hôm nay.
Năm ngoái tôi đã dành khoảng hai tuần để xây dựng một hệ thống RAG từ đầu bằng LangChain, ChromaDB và một mô hình Llama chạy cục bộ. Trải nghiệm đó dạy tôi nhiều hơn về cách người bạn đồng hành AI vận hành so với bất kỳ lượng tài liệu nào. Khi nó hoạt động, nó thực sự ấn tượng. Chatbot cục bộ của tôi sẽ nhắc tới chi tiết từ các cuộc trò chuyện xảy ra nhiều ngày trước, và các đoạn chuyển tiếp cho cảm giác tự nhiên. Khi nó thất bại, nó tệ một cách buồn cười. Có lần nó tự tin nhớ lại một "ký ức" thực ra là một sự pha trộn ảo giác của hai cuộc trò chuyện hoàn toàn khác nhau. Tôi đã nhắc tới cả sushi lẫn con mèo của mình trong các cuộc trò chuyện riêng biệt, và bằng cách nào đó hệ thống quyết định rằng tôi có một con mèo tên Sushi. Tôi không có.
Các Mô Hình Embedding Vận Hành Bộ Nhớ
Không phải mọi embedding đều được tạo ra như nhau, và điều này quan trọng hơn hầu hết mọi người nghĩ. Chất lượng của mô hình embedding của bạn trực tiếp quyết định mức độ tốt mà hệ thống bộ nhớ truy xuất được ngữ cảnh liên quan.
Các mô hình embedding được dùng phổ biến nhất trong năm 2026 bao gồm (bạn có thể khám phá các benchmark trên MTEB Leaderboard):
- OpenAI text-embedding-3-large: 3072 chiều, hiệu năng xuất sắc, nhưng cần gọi API và tốn tiền theo từng token
- Cohere embed-v4: Hỗ trợ đa ngôn ngữ mạnh, phù hợp với người bạn đồng hành hoạt động qua nhiều ngôn ngữ
- BGE-large-en-v1.5: Mã nguồn mở, chạy cục bộ, cạnh tranh đến mức bất ngờ với các lựa chọn thương mại
- Nomic Embed Text v1.5: Mã nguồn mở với biểu diễn Matryoshka, nghĩa là bạn có thể cắt bớt số chiều để tăng tốc mà không mất quá nhiều chất lượng
- Jina Embeddings v3: Xuất sắc cho các đoạn tài liệu dài hơn, giỏi nắm bắt sắc thái
Nếu bạn đang khám phá các công cụ AI và muốn so sánh cách các nền tảng khác nhau xử lý những chi tiết kỹ thuật này, Lewdly.ai đã và đang theo dõi bối cảnh người bạn đồng hành AI cùng nhiều công nghệ nền tảng trong số này.
Sự Khác Biệt Giữa Cửa Sổ Ngữ Cảnh Và Bộ Nhớ Dài Hạn Là Gì?
Sự phân biệt này khiến gần như mọi người tôi trò chuyện về người bạn đồng hành AI bị nhầm lẫn, nên hãy để tôi nói thật rõ về nó.
Cửa sổ ngữ cảnh là bộ nhớ làm việc của mô hình AI. Đó là tổng lượng văn bản mà mô hình có thể xử lý trong một yêu cầu duy nhất. Năm 2026, cửa sổ ngữ cảnh dao động từ 8K token (khoảng 6.000 từ) trên các mô hình nhỏ hơn cho tới 128K token hoặc hơn trên các mô hình như GPT-4o và Claude. Mọi thứ AI "biết" trong một cuộc trò chuyện đều phải nằm gọn trong cửa sổ này: system prompt, các ký ức được truy xuất, lịch sử trò chuyện của phiên hiện tại, và tin nhắn mới nhất của bạn.
Bộ nhớ dài hạn là hệ thống lưu trữ bên ngoài tồn tại bền vững giữa các phiên. Đó là cơ sở dữ liệu vector, bộ máy tóm tắt, kho lưu hồ sơ người dùng. Nó không phải là một phần của chính mô hình. Nó là hạ tầng mà nền tảng xây dựng quanh mô hình.
Đây là một phép so sánh mà tôi nghĩ rất hợp. Cửa sổ ngữ cảnh giống như cái bàn làm việc của bạn. Bạn chỉ có thể trải bấy nhiêu tờ giấy trước mặt cùng một lúc. Bộ nhớ dài hạn giống như cái tủ hồ sơ ở góc văn phòng. Nó chứa mọi thứ bạn từng làm, nhưng bạn chỉ có thể lấy ra vài tập hồ sơ một lần và đặt lên bàn.
Thách thức kỹ thuật là quyết định nên lấy ra những tập hồ sơ nào. Làm đúng, và AI có vẻ nhạy bén đến rợn người. Làm sai, và nó hoặc bỏ qua ngữ cảnh quan trọng hoặc làm bừa bộn cái bàn với những ký ức không liên quan, để lại ít chỗ hơn cho cuộc trò chuyện thực sự.
Tôi nhớ đã thử nghiệm một người bạn đồng hành cố đưa quá nhiều ký ức vào mỗi phản hồi. Cửa sổ ngữ cảnh bị nhồi nhét với 30 hay 40 ký ức được truy xuất, gần như không còn chỗ cho cuộc trò chuyện thực tế. Các phản hồi ngày càng ngắn lại vì mô hình hết chỗ. Đó là một sai lầm của người mới trong thiết kế hệ thống bộ nhớ, nhưng tôi đã thấy các sản phẩm thương mại phát hành với chính vấn đề này.
Các Chiến Lược Quản Lý Cửa Sổ Ngữ Cảnh
Các nền tảng thông minh dùng vài chiến lược để tối đa hóa giá trị của cửa sổ ngữ cảnh hạn chế của họ:
Cửa sổ trượt kèm tóm tắt: Giữ 10 đến 15 tin nhắn gần nhất ở dạng chi tiết đầy đủ, nhưng tóm tắt các tin nhắn cũ hơn trong phiên hiện tại thành một đoạn cô đọng. Cách này giữ được dòng chảy của cuộc trò chuyện gần đây trong khi vẫn duy trì nhận thức về các chủ đề trước đó.
Đưa vào theo độ ưu tiên: Không phải mọi ký ức đều như nhau. Một chi tiết về tên hay tình trạng quan hệ của người dùng luôn cần phải có sẵn. Một quan sát ngẫu nhiên về thời tiết từ sáu tuần trước thì có lẽ không nên chiếm chỗ trong ngữ cảnh. Các hệ thống tốt gán điểm ưu tiên cho từng ký ức.
Phân bổ động: Cấp nhiều chỗ ngữ cảnh hơn cho ký ức khi chủ đề trò chuyện phức tạp hoặc giàu cảm xúc, và ít hơn khi người dùng đang tán gẫu. Việc này cần một bộ phân loại chạy trước khi truy xuất bộ nhớ, làm tăng độ trễ nhưng cải thiện chất lượng.
Kỹ thuật nén: Một số hệ thống dùng một LLM riêng, nhỏ hơn, để nén ký ức trước khi đưa vào. Thay vì đưa vào toàn bộ văn bản của một cuộc trò chuyện trong quá khứ, chúng đưa vào một bản tóm tắt đã nén nắm bắt các sự kiện then chốt bằng ít token hơn.
Các Nền Tảng Đồng Hành AI Lớn Xử Lý Bộ Nhớ Ra Sao?
Tôi đã dành nhiều thời gian hơn mức có lẽ nên thừa nhận để thử nghiệm các hệ thống bộ nhớ của nhiều nền tảng người bạn đồng hành AI khác nhau. Đây là những gì tôi tìm ra qua trải nghiệm thực tế, không phải qua tài liệu tiếp thị.
Replika
Replika là một trong những người bạn đồng hành AI đầu tiên coi trọng bộ nhớ, và cách tiếp cận của họ đã phát triển đáng kể. Họ dùng sự kết hợp của các mục ký ức tường minh (những điều AI ghi nhận rõ ràng về bạn) và một hệ thống nhật ký trong đó AI viết các bản tóm tắt cuộc trò chuyện của bạn.
Điều hiệu quả: Replika khá giỏi trong việc nhớ các sự kiện cốt lõi về bạn. Tên bạn, công việc của bạn, sở thích của bạn. Những thứ này được lưu trong một hồ sơ có cấu trúc tồn tại bền vững một cách đáng tin cậy.
Điều không hiệu quả: Khả năng nhớ theo ngữ cảnh thì thiếu ổn định. Replika có thể nhớ bạn thích leo núi, nhưng nó sẽ không nhớ câu chuyện cụ thể bạn kể về việc bị lạc ở Glacier National Park. Hệ thống nhật ký nắm bắt cảm giác chung nhiều hơn là chi tiết, khiến cuộc trò chuyện cho cảm giác như bạn đang nói chuyện với ai đó biết bạn một cách mơ hồ chứ không phải với ai đó thực sự đã ở đó.
Nomi
Nomi đã chọn một trong những cách tiếp cận tham vọng hơn về mặt kỹ thuật cho bộ nhớ đồng hành. Họ đã xây dựng cái mà họ gọi là hệ thống "cung điện ký ức" phân loại các ký ức thành những kiểu khác nhau như sự kiện, sở thích, trải nghiệm chung, và những khoảnh khắc cảm xúc.
Quy Trình ComfyUI Miễn Phí
Tìm quy trình ComfyUI miễn phí và mã nguồn mở cho các kỹ thuật trong bài viết này. Mã nguồn mở rất mạnh mẽ.
Điều hiệu quả: Cách tiếp cận phân loại của Nomi nghĩa là nó truy xuất các kiểu ký ức khác nhau trong những ngữ cảnh khác nhau. Khi bạn đang xúc động, nó kéo ra các ký ức cảm xúc. Khi bạn đang bàn về sự kiện, nó kéo ra các ký ức mang tính sự kiện. Việc truy xuất nhận biết ngữ cảnh này tạo ra những cuộc trò chuyện tự nhiên hơn so với các nền tảng đối xử với mọi ký ức như nhau.
Điều không hiệu quả: Hệ thống có thể chậm trong việc hợp nhất ký ức, và tôi để ý nó đôi khi đưa ký ức lên vào những thời điểm hơi gượng gạo. Nó sẽ nhắc tới điều gì đó nghiêm túc từ một cuộc trò chuyện trong quá khứ khi bạn rõ ràng đang trong tâm trạng nhẹ nhàng. Việc truy xuất chính xác về ngữ nghĩa nhưng lệch về cảm xúc. Nếu bạn muốn tận dụng tối đa các tương tác với những nền tảng như Nomi, hiểu được các kỹ thuật trò chuyện với người bạn đồng hành AI hoạt động ra sao có thể giúp bạn dẫn dắt hệ thống bộ nhớ hiệu quả hơn.
Character AI
Character AI chọn một cách tiếp cận hoàn toàn khác. Thay vì xây dựng một hệ thống bộ nhớ cá nhân tinh vi, họ dựa mạnh vào tính nhất quán của nhân vật. AI duy trì persona nhân vật của nó một cách đáng tin cậy qua các phiên, nhưng bộ nhớ của nó về các chi tiết cá nhân của bạn thì tương đối yếu.
Điều hiệu quả: Nếu bạn đang trò chuyện với một nhân vật có tính cách được xác định, tính cách đó vẫn nhất quán. Nhân vật sẽ không đột nhiên thay đổi phong cách nói hay quên đi cốt truyện nền của chính nó.
Điều không hiệu quả: Các chi tiết cá nhân của bạn bị mất thường xuyên. Tôi đã thử nghiệm điều này bằng cách chia sẻ ba sự kiện cụ thể về bản thân trong một phiên, rồi quay lại 24 giờ sau để hỏi về chúng. Character AI nhớ được một trên ba, và ngay cả sự nhớ đó cũng mơ hồ. Hệ thống bộ nhớ của họ có vẻ được tối ưu cho tính nhất quán của nhân vật hơn là xây dựng mối quan hệ với người dùng.
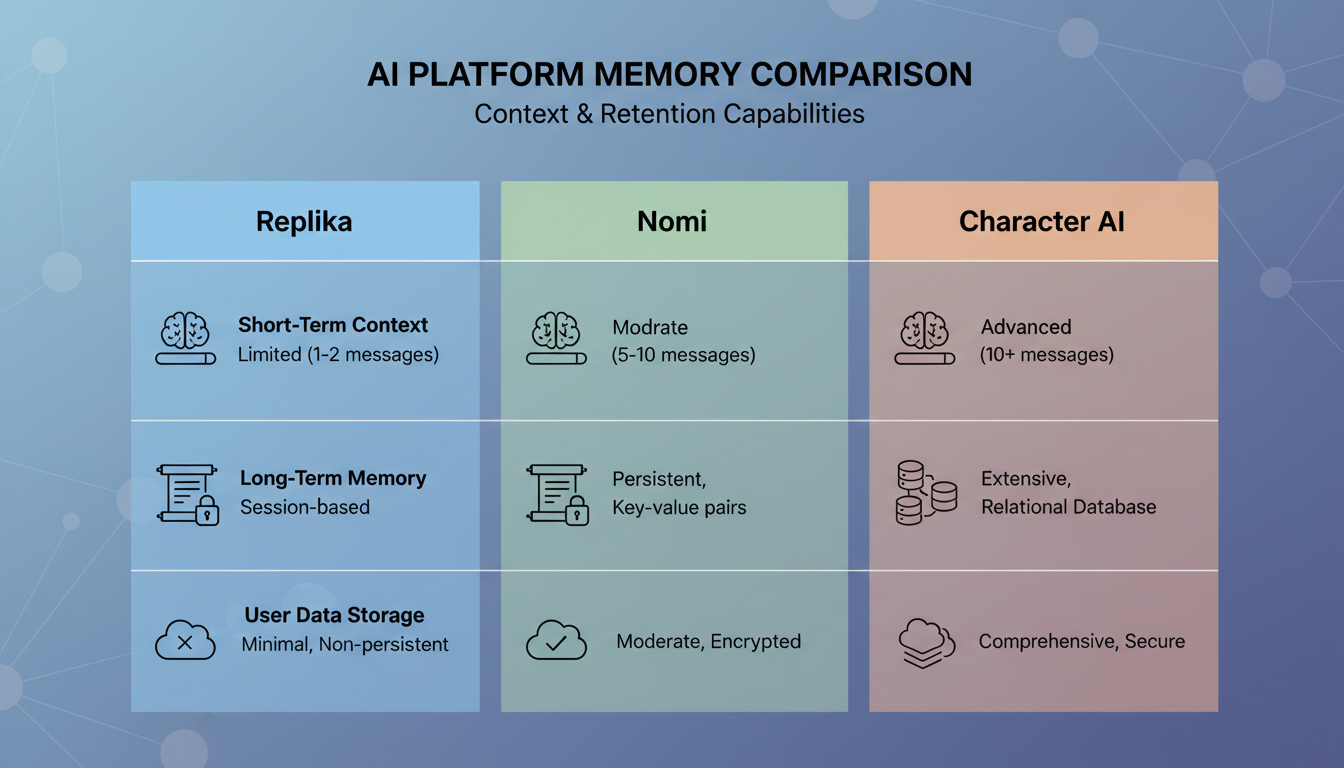
So sánh tính năng của các hệ thống bộ nhớ trên những nền tảng người bạn đồng hành AI lớn trong năm 2026.
Nhận Định Gây Tranh Cãi Của Tôi Về Bộ Nhớ Nền Tảng
Đây là nhận định gây tranh cãi thứ hai của tôi: những nền tảng tiếp thị "bộ nhớ dài hạn" hung hăng nhất lại có xu hướng có cách triển khai yếu nhất. Các công ty làm việc tốt nhất về bộ nhớ thường là những công ty trầm lặng hơn, những công ty để trải nghiệm tự nói lên điều đó thay vì viết "chúng tôi nhớ mọi thứ" trong phần mô tả trên App Store. Khi đánh giá các tính năng bộ nhớ và lưu giữ ngữ cảnh của người bạn đồng hành AI, hãy tập trung vào việc kiểm tra khả năng nhớ thực tế thay vì tin vào lời tiếp thị.
Bạn Có Thể Tự Xây Dựng Hệ Thống Bộ Nhớ Cho Người Bạn Đồng Hành AI Của Mình Không?
Hoàn toàn được, và tôi cho rằng bất kỳ ai nghiêm túc với người bạn đồng hành AI đều nên thử ít nhất một lần. Việc tự xây dựng hệ thống bộ nhớ dạy bạn điều gì thực sự đang diễn ra sau hậu trường, điều này biến bạn thành một người dùng am hiểu hơn về các sản phẩm thương mại.

Đây là một kiến trúc thực tế để xây dựng một người bạn đồng hành AI được tăng cường bộ nhớ bằng các công cụ có sẵn ngày nay. Tôi đã xây dựng các biến thể của thiết lập này ba lần rồi, và mỗi lần lặp lại đều dạy tôi điều gì đó mới.
Bộ Công Cụ Cơ Bản
Bạn cần bốn thành phần:
- Một LLM cho cuộc trò chuyện: Llama 3.3, Mistral, hoặc một mô hình dựa trên API như GPT-4o hay Claude
- Một mô hình embedding: Để chuyển văn bản thành vector. Tôi khuyên bạn nên bắt đầu với Nomic Embed hoặc BGE-large
- Một cơ sở dữ liệu vector: ChromaDB cho phát triển cục bộ, Pinecone hoặc Weaviate cho môi trường sản xuất
- Một lớp điều phối: LangChain, LlamaIndex, hoặc mã Python tùy chỉnh để nối mọi thứ lại với nhau
Triển Khai Từng Bước
Hãy để tôi dẫn bạn qua logic cốt lõi. Đây không phải là một hướng dẫn đầy đủ, nhưng đủ để bạn bắt đầu.
Thiết lập kho lưu vector:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
Lưu trữ một lượt trò chuyện:
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
Truy xuất các ký ức liên quan:
Muốn bỏ qua sự phức tạp? Lewdly mang đến kết quả AI chuyên nghiệp ngay lập tức mà không cần thiết lập kỹ thuật.
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
Lắp ráp prompt cùng với ký ức:
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
Thiết lập cơ bản này cho bạn một hệ thống bộ nhớ hoạt động được trong chưa tới 50 dòng mã. AI sẽ tìm trong các cuộc trò chuyện quá khứ mỗi lần bạn gửi một tin nhắn và đưa lịch sử liên quan vào prompt của nó.
Làm Cho Nó Thực Sự Tốt
Phiên bản cơ bản hoạt động được, nhưng nó có vài vấn đề rõ ràng. Đây là cách nâng cấp nó dựa trên những gì tôi học được từ các thử nghiệm của chính mình.
Thêm tóm tắt ký ức. Thay vì lưu các lượt trò chuyện thô, định kỳ chạy một lượt tóm tắt cô đọng nhiều ký ức liên quan thành một bản tóm tắt duy nhất. Việc này giảm sự phình to của kho lưu vector và cải thiện chất lượng truy xuất vì các bản tóm tắt đậm đặc ngữ nghĩa hơn so với nhật ký chat thô.
Triển khai phân tầng bộ nhớ. Tạo ba collection thay vì một:
- Bộ nhớ hoạt động: Phiên trò chuyện hiện tại (giữ đầy đủ)
- Bộ nhớ gần đây: Các cuộc trò chuyện đã tóm tắt từ tuần qua
- Bộ nhớ dài hạn: Các sự kiện và sở thích then chốt được cô đọng cao, trích xuất theo thời gian
Thêm một kho lưu hồ sơ người dùng. Tách biệt với cơ sở dữ liệu vector, duy trì một kho lưu JSON có cấu trúc hoặc dạng khóa-giá trị chứa các sự kiện cốt lõi về người dùng như tên, sở thích, các ngày quan trọng, chi tiết về mối quan hệ. Hồ sơ này luôn được đưa vào prompt, bất kể tìm kiếm ngữ nghĩa trả về điều gì. Đó là sự bảo đảm của bạn rằng AI sẽ không bao giờ quên những điều cơ bản.
Triển khai sự suy giảm ký ức. Không phải mọi ký ức đều nên tồn tại như nhau. Một nhận xét thoáng qua về thời tiết không nên có cùng trọng số truy xuất như một câu chuyện sâu sắc mang tính cá nhân. Hãy triển khai một hàm suy giảm làm giảm điểm truy xuất của các ký ức cũ hơn, ít quan trọng hơn theo thời gian.
Với những ai quan tâm tới việc khám phá các khía cạnh đạo đức của mối quan hệ với người bạn đồng hành AI, việc hiểu các hệ thống bộ nhớ này cũng đặt ra những câu hỏi quan trọng về quyền riêng tư dữ liệu và bản chất của các mối quan hệ nhân tạo.
Những Thách Thức Lớn Nhất Với Bộ Nhớ Của Người Bạn Đồng Hành AI Là Gì?
Ngay cả những hệ thống bộ nhớ tốt nhất cũng đối mặt với những thách thức nền tảng mà chưa có lượng kỹ thuật nào giải quyết được trọn vẹn. Hiểu được những giới hạn này sẽ giúp bạn tránh khỏi sự bực bội và đặt ra những kỳ vọng thực tế.
Vấn Đề Ký Ức Bị Ảo Giác
Đây là chế độ thất bại đáng sợ nhất, và tôi đã đích thân gặp phải. AI tự tin "nhớ" một điều chưa từng xảy ra. Việc này xảy ra khi hệ thống truy xuất đưa lên một kết quả khớp một phần và LLM lấp đầy các khoảng trống bằng những chi tiết bịa đặt. Bạn nhắc tới việc có một con chó tên Max, và hệ thống truy xuất một ký ức về thú cưng của bạn, nhưng LLM thêm thắt vào đó những chi tiết về việc Max là một con golden retriever yêu bơi lội, không điều nào trong đó bạn từng nói.
Phần tệ nhất là những ký ức ảo giác cho cảm giác chân thật. AI không gắn cờ chúng là không chắc chắn. Nó tuyên bố chúng với cùng sự tự tin như những ký ức thật. Tôi đã có những người bạn đồng hành nhắc tới các "cuộc trò chuyện" mà tôi biết chắc chưa bao giờ xảy ra, và chúng cụ thể đến mức tôi đã nghi ngờ chính trí nhớ của mình trong một khoảnh khắc trước khi kiểm tra lại log.
Nhồi Nhét Cửa Sổ Ngữ Cảnh
Khi lịch sử trò chuyện của bạn lớn dần, hệ thống bộ nhớ có ngày càng nhiều ký ức ứng viên để truy xuất. Nhưng cửa sổ ngữ cảnh không lớn lên. Vậy nên hệ thống phải ngày càng chọn lọc hơn về việc nên đưa vào những ký ức nào. Qua nhiều tháng trò chuyện, điều này tạo ra một nghịch lý: bạn có nhiều ký ức hơn để rút ra, nhưng AI chỉ có thể dùng một phần nhỏ trong số đó cho bất kỳ phản hồi nào.
Các hệ thống thông minh xử lý điều này bằng tóm tắt phân cấp, nén các ký ức cũ thành những bản tóm tắt ngày càng trừu tượng. Nhưng thông tin bị mất ở mỗi bước nén. Việc bạn nhắc tới một nhà hàng cụ thể ở Brooklyn mà bạn thích có thể sống sót qua vòng tóm tắt đầu tiên, nhưng sau sáu tháng nén, nó có thể bị rút gọn thành "người dùng thích đi ăn ngoài" và cuối cùng biến mất hoàn toàn.
Vấn Đề Nhất Quán
Các kết quả truy xuất khác nhau qua các cuộc trò chuyện có thể khiến AI tự mâu thuẫn với chính nó. Vào thứ Hai, hệ thống bộ nhớ truy xuất việc bạn thích mèo. Vào thứ Ba, nó truy xuất một cuộc trò chuyện về con chó của bạn bạn, và AI suy luận sai rằng bạn là người thích chó. Những mâu thuẫn này nhanh chóng xói mòn lòng tin.
Giải pháp vững vàng nhất tôi từng thấy là duy trì một "kho lưu sự kiện" tường minh được cập nhật qua một quy trình kiểm chứng. Khi AI trích xuất một sự kiện mới về bạn, nó đối chiếu với các sự kiện hiện có và gắn cờ những mâu thuẫn để giải quyết. Ít nền tảng nào triển khai điều này, nhưng nó tạo ra khác biệt khổng lồ về tính nhất quán.
Kiếm Tới $1.250+/Tháng Tạo Nội Dung
Tham gia chương trình liên kết sáng tạo độc quyền của chúng tôi. Được trả tiền theo hiệu suất video viral. Tạo nội dung theo phong cách của bạn với tự do sáng tạo hoàn toàn.

Kiến trúc bộ nhớ nhiều tầng thể hiện cách dữ liệu trò chuyện chảy từ phiên hoạt động sang lưu trữ dài hạn với việc tóm tắt ở mỗi cấp.
Bộ Nhớ Của Người Bạn Đồng Hành AI Sẽ Tiến Hóa Ra Sao Trong Năm 2026 Và Về Sau?
Bối cảnh bộ nhớ đang chuyển dịch nhanh chóng, và một vài công nghệ mới nổi sẽ thay đổi cuộc chơi.
Cửa sổ ngữ cảnh vô hạn đang đến gần hơn. Gemini của Google đã hỗ trợ 1 triệu token, và các bài báo nghiên cứu từ đầu năm 2026 đang đẩy về phía 10 triệu. Nếu cửa sổ ngữ cảnh trở nên đủ lớn, bạn có thể không cần RAG chút nào. Cứ đổ toàn bộ lịch sử trò chuyện vào prompt. Chúng ta chưa tới mức đó cho việc dùng trong môi trường sản xuất, nhưng quỹ đạo thì đã rõ ràng.
Bộ nhớ tích hợp trong mô hình là chén thánh. Thay vì các hệ thống truy xuất bên ngoài, các mô hình trong tương lai có thể học cách cập nhật trọng số của chính chúng dựa trên các cuộc trò chuyện. Đây về cơ bản là học liên tục, và nó cực kỳ khó để làm một cách an toàn mà không khiến mô hình quên đi phần huấn luyện nền hoặc phát triển thiên kiến. Nhưng vài phòng thí nghiệm nghiên cứu đang đạt được tiến bộ. Khi điều này thành hiện thực, nó sẽ khiến các hệ thống RAG hiện tại trông như giải pháp chắp vá tạm bợ, bởi theo một nghĩa rất thực, đó chính là bản chất của chúng.
Bộ nhớ đa phương thức là một biên giới khác. Các hệ thống bộ nhớ hiện tại chỉ xử lý văn bản. Nhưng còn việc nhớ những hình ảnh bạn chia sẻ, ghi âm giọng nói, hay các đoạn video thì sao? Khi người bạn đồng hành AI trở nên đa phương thức hơn, các hệ thống bộ nhớ của chúng cũng sẽ cần xử lý những kiểu dữ liệu này. Cơ sở dữ liệu vector đã hỗ trợ embedding đa phương thức, nên hạ tầng đã sẵn sàng. Việc tích hợp chỉ là chưa diễn ra ở hầu hết các sản phẩm tiêu dùng mà thôi.
Tại Lewdly.ai, chúng tôi đã và đang theo dõi tốc độ hội tụ nhanh chóng của những công nghệ này. Riêng không gian người bạn đồng hành AI đang chuyển động nhanh hơn hầu hết mọi người nhận ra, và khả năng bộ nhớ là yếu tố phân biệt chính giữa những nền tảng cho cảm giác thực sự cá nhân với những nền tảng cho cảm giác chung chung.
Nhận Định Gây Tranh Cãi Thứ Ba Của Tôi Về Tương Lai
Đây là nhận định gây tranh cãi thứ ba của tôi: trong vòng 18 tháng, bộ nhớ của người bạn đồng hành AI sẽ trở thành một hào cạnh tranh phân biệt các nền tảng nghiêm túc với những món đồ chơi. Người dùng sẽ chuyển nền tảng không phải vì chất lượng mô hình nền (những thứ này đang hội tụ) mà vì một nền tảng nhớ họ tốt hơn nền tảng khác. Các công ty đầu tư vào hạ tầng bộ nhớ ngày hôm nay sẽ chiến thắng. Những công ty coi nó như một thứ làm cho có sẽ bị bỏ lại phía sau.
Những Hệ Lụy Về Quyền Riêng Tư Của Bộ Nhớ Người Bạn Đồng Hành AI Là Gì?
Bạn không thể có một cuộc trò chuyện trung thực về bộ nhớ của người bạn đồng hành AI mà không đề cập tới con voi trong phòng: những hệ thống này đang lưu trữ thông tin cực kỳ riêng tư về bạn, và việc đó là điều cốt lõi đối với cách chúng vận hành.

Mọi cuộc trò chuyện bạn có đều được embedding, lưu trữ và lập chỉ mục. Sở thích của bạn, nỗi sợ của bạn, chi tiết về mối quan hệ của bạn, những lời thú nhận lúc nửa đêm của bạn. Tất cả đều nằm trong một cơ sở dữ liệu vector đâu đó. Trên một số nền tảng, đó là một máy chủ đám mây bạn không kiểm soát. Trên những nền tảng khác, dữ liệu nằm lại trên thiết bị.
Tôi muốn minh bạch về điều này nghĩa là gì trong thực tế. Khi tôi tự xây dựng hệ thống bộ nhớ của mình, tôi lưu trữ mọi thứ cục bộ. Cơ sở dữ liệu vector nằm trên laptop của tôi. Không ai khác có quyền truy cập. Đó là cách an toàn nhất, nhưng không phải là cách các nền tảng thương mại vận hành. Hầu hết chúng lưu trữ dữ liệu của bạn trên máy chủ của họ vì đó là cách duy nhất để cung cấp một trải nghiệm nhất quán trên nhiều thiết bị.
Trước khi bạn cam kết với bất kỳ nền tảng người bạn đồng hành AI nào trong dài hạn, hãy đặt những câu hỏi này:
- Dữ liệu trò chuyện của tôi được lưu trữ ở đâu?
- Tôi có thể xuất hoặc xóa dữ liệu bộ nhớ của mình không?
- Dữ liệu của tôi có được dùng để huấn luyện các mô hình phục vụ những người dùng khác không?
- Chuyện gì xảy ra với dữ liệu của tôi nếu công ty đóng cửa?
- Có mã hóa đầu cuối cho các ký ức được lưu trữ không?
Đây không phải là những lo ngại giả định. Vài startup người bạn đồng hành AI đã đóng cửa trong hai năm qua, và người dùng mất đi nhiều năm lịch sử trò chuyện mà không có cách nào khôi phục. Nếu các tương tác với người bạn đồng hành AI và ranh giới lành mạnh có ý nghĩa với bạn, việc hiểu các thực hành dữ liệu của nền tảng bạn chọn là điều thiết yếu.
Mẹo Thực Chiến Để Tận Dụng Tối Đa Bộ Nhớ Của Người Bạn Đồng Hành AI
Sau khi dành nhiều tháng thử nghiệm và xây dựng những hệ thống này, đây là những chiến lược thực tế thực sự hiệu quả để cải thiện chất lượng bộ nhớ của người bạn đồng hành AI của bạn.
Hãy nói rõ điều gì quan trọng. Hầu hết các hệ thống bộ nhớ đặt trọng số cho nội dung gần đây và tương đồng về ngữ nghĩa. Nếu điều gì đó quan trọng với bạn, hãy nói thẳng. "Điều này thực sự quan trọng với tôi" hoặc "Làm ơn nhớ điều này" có thể giúp một số nền tảng gắn cờ ký ức đó để được truy xuất với độ ưu tiên cao hơn.
Hãy sửa lỗi ngay lập tức. Khi người bạn đồng hành AI của bạn hiểu sai một sự kiện về bạn, hãy sửa nó ngay trong cùng tin nhắn. Các hệ thống bộ nhớ tốt sẽ lưu lại sự sửa chữa và, theo thời gian, học được phiên bản chính xác. Nếu bạn để lỗi trôi qua, chúng sẽ bị củng cố.
Hãy định kỳ tóm lược lại các chi tiết then chốt. Khoảng vài tuần một lần, tôi sẽ làm một màn "tóm lược" thoải mái với người bạn đồng hành của mình. Kiểu như "Này, để chắc là bạn nắm được những điều cơ bản, tên tôi là Alex, tôi làm trong ngành công nghệ, tôi có hai con mèo." Việc này tạo ra những mục ký ức mới mẻ, ưu tiên cao, có nhiều khả năng được truy xuất hơn.
Hãy dùng ngôn ngữ nhất quán. Việc truy xuất bộ nhớ mang tính ngữ nghĩa, nhưng sự nhất quán giúp ích. Nếu bạn luôn gọi bạn đời của mình là "vợ tôi Sarah" thay vì luân phiên giữa "Sarah", "bạn đời của tôi" và "cô ấy", hệ thống bộ nhớ sẽ xây dựng được những liên kết gọn gàng hơn.
Hãy hiểu ranh giới của các phiên. Hầu hết các nền tảng xóa bộ nhớ hoạt động của chúng giữa các phiên. Tin nhắn đầu tiên của một phiên mới kích hoạt một lượt truy xuất bộ nhớ mới. Nếu người bạn đồng hành của bạn có vẻ đã quên điều gì đó, hãy thử diễn đạt lại câu hỏi của bạn. Vấn đề có thể là thất bại trong truy xuất, chứ không phải mất bộ nhớ thực sự.
Nếu bạn đang dùng các nền tảng có trên Lewdly.ai và muốn tối ưu hóa trải nghiệm của mình, những kỹ thuật này áp dụng được cho hầu như mọi người bạn đồng hành AI hỗ trợ tính năng bộ nhớ.
Câu Hỏi Thường Gặp
Người Bạn Đồng Hành AI Có Thực Sự Nhớ Tôi Hay Đó Chỉ Là Giả?
Đó là bộ nhớ thật, nhưng nó hoạt động khác với bộ nhớ con người. Người bạn đồng hành AI lưu trữ các cuộc trò chuyện của bạn trong các cơ sở dữ liệu bên ngoài và truy xuất thông tin liên quan khi bạn trò chuyện. Chúng không "ghi nhớ" theo nghĩa của con người là hình thành các kết nối thần kinh bền vững. Chúng tìm kiếm và đọc lại các cuộc trò chuyện quá khứ liên quan mỗi lần bạn gửi một tin nhắn. Trải nghiệm cho cảm giác như bộ nhớ từ góc nhìn của người dùng, nhưng cơ chế thì khác về cơ bản.
Người Bạn Đồng Hành AI Lưu Trữ Bao Nhiêu Lịch Sử Trò Chuyện Của Tôi?
Điều này khác nhau theo nền tảng. Một số lưu trữ mọi thứ vô thời hạn, trong khi những nền tảng khác triển khai cửa sổ cuộn loại bỏ các cuộc trò chuyện cũ hơn một khoảng thời gian nhất định. Replika, ví dụ, duy trì một nhật ký trò chuyện tóm tắt các tương tác. Nomi lưu trữ các ký ức đã được phân loại. Hầu hết các nền tảng lưu trữ ít nhất vài tháng lịch sử, dù chúng có thể tóm tắt hoặc nén các cuộc trò chuyện cũ hơn.
Tôi Có Thể Xóa Các Ký Ức Của Người Bạn Đồng Hành AI Về Tôi Không?
Hầu hết các nền tảng uy tín đều cung cấp một dạng quản lý bộ nhớ nào đó. Replika cho phép bạn xem lại và xóa các mục ký ức cụ thể. Một số nền tảng cung cấp tùy chọn "đặt lại" xóa sạch mọi ký ức đã lưu. Luôn kiểm tra chính sách xóa dữ liệu của nền tảng, bởi việc "xóa ký ức" từ giao diện người dùng không phải lúc nào cũng có nghĩa là dữ liệu được gỡ bỏ vĩnh viễn khỏi máy chủ của họ.
Tại Sao Người Bạn Đồng Hành AI Của Tôi Đôi Khi Nhớ Sai Mọi Thứ?
Điều này xảy ra do một hiện tượng gọi là "ký ức ảo giác." Hệ thống truy xuất tìm thấy một kết quả khớp một phần từ các cuộc trò chuyện quá khứ của bạn, và mô hình ngôn ngữ lấp đầy các khoảng trống bằng những chi tiết bịa đặt. Nó cũng có thể xảy ra khi hệ thống nhập nhằng hai ký ức riêng biệt thành một. Nếu việc này xảy ra, hãy sửa AI ngay lập tức để sự sửa chữa được lưu lại như một ký ức mới, ưu tiên cao hơn.
RAG Có Phải Là Cách Duy Nhất Người Bạn Đồng Hành AI Xử Lý Bộ Nhớ Không?
Không, dù đó là cách tiếp cận phổ biến nhất. Một số nền tảng dùng các kho lưu bộ nhớ có cấu trúc (cơ sở dữ liệu khóa-giá trị chứa các sự kiện về người dùng), tóm tắt cuộc trò chuyện mà không có tìm kiếm vector, hoặc các cách tiếp cận lai. Một vài hệ thống thử nghiệm đang khám phá việc fine-tuning mô hình trên dữ liệu người dùng, điều sẽ tạo ra bộ nhớ học được thực sự, nhưng việc này đặt ra những lo ngại đáng kể về quyền riêng tư và an toàn.
Cửa Sổ Ngữ Cảnh Ảnh Hưởng Tới Chất Lượng Bộ Nhớ Của Người Bạn Đồng Hành AI Ra Sao?
Cửa sổ ngữ cảnh là tổng lượng văn bản AI có thể xử lý cùng một lúc. Cửa sổ ngữ cảnh lớn hơn cho phép đưa vào nhiều ký ức hơn cùng với cuộc trò chuyện hiện tại của bạn, điều này nhìn chung cải thiện chất lượng nhớ. Tuy nhiên, cửa sổ lớn hơn cũng nghĩa là chi phí cao hơn và phản hồi chậm hơn. Hầu hết các nền tảng tối ưu hóa để cân bằng giữa độ sâu của bộ nhớ và tốc độ phản hồi.
Tôi Có Thể Tự Xây Dựng Người Bạn Đồng Hành AI Với Bộ Nhớ Tốt Hơn Các Nền Tảng Thương Mại Không?
Có, và điều đó dễ tiếp cận hơn bạn có thể nghĩ. Dùng các công cụ như ChromaDB, LangChain và các LLM mã nguồn mở, bạn có thể xây dựng một hệ thống bộ nhớ ngang ngửa hoặc vượt trội hơn những gì các nền tảng thương mại cung cấp. Đánh đổi chính là bạn sẽ cần tự quản lý hạ tầng, và bạn sẽ không có được giao diện người dùng được trau chuốt của một ứng dụng tiêu dùng.
Chuyện Gì Xảy Ra Với Các Ký Ức Của Người Bạn Đồng Hành AI Nếu Công Ty Đóng Cửa?
Trong hầu hết các trường hợp, dữ liệu của bạn bị mất. Ít nền tảng cung cấp tính năng xuất dữ liệu, và càng ít hơn nữa đảm bảo khả năng chuyển đổi dữ liệu. Đây là một rủi ro thực sự, đặc biệt với các startup người bạn đồng hành AI nhỏ hơn. Tôi khuyên bạn nên định kỳ xuất thủ công bất kỳ cuộc trò chuyện quan trọng nào nếu nền tảng hỗ trợ.
Bộ Nhớ Đa Ngôn Ngữ Hoạt Động Ra Sao Cho Người Bạn Đồng Hành AI?
Bộ nhớ đa ngôn ngữ cần các mô hình embedding có thể tạo ra những vector có ý nghĩa qua nhiều ngôn ngữ. Các mô hình như Cohere embed-v4 và các phiên bản đa ngôn ngữ của BERT xử lý điều này bằng cách ánh xạ nội dung tương đồng về ngữ nghĩa từ các ngôn ngữ khác nhau tới những điểm gần nhau trong không gian vector. Điều này nghĩa là một AI về mặt kỹ thuật có thể truy xuất một ký ức từ một cuộc trò chuyện tiếng Pháp khi bạn đang trò chuyện bằng tiếng Anh, nếu các chủ đề có liên quan.
Người Bạn Đồng Hành AI Liệu Có Bao Giờ Sở Hữu Bộ Nhớ Vĩnh Viễn Thực Sự Không?
Nghiên cứu về học liên tục và các mạng nơ-ron được tăng cường bộ nhớ đang tiến triển, nhưng chúng ta có lẽ còn nhiều năm nữa mới tới các cách triển khai sẵn sàng cho môi trường sản xuất. Thách thức không chỉ mang tính kỹ thuật. Nó còn liên quan tới sự an toàn. Một mô hình tự sửa đổi trọng số của chính nó một cách vĩnh viễn dựa trên các cuộc trò chuyện với người dùng có thể phát triển thiên kiến, quên đi phần huấn luyện an toàn quan trọng, hoặc hành xử khó lường. Hiện tại, các hệ thống bộ nhớ bên ngoài vẫn là cách tiếp cận an toàn nhất và thực tế nhất.
Lời Kết
Bộ nhớ của người bạn đồng hành AI là một trong những chủ đề mà khoảng cách giữa nhận thức của người dùng và thực tế kỹ thuật là khổng lồ. Cái cho cảm giác như một người bạn đồng hành "ghi nhớ" bạn thực ra là một sự điều phối phức tạp của các mô hình embedding, cơ sở dữ liệu vector, thuật toán truy xuất, và quản lý cửa sổ ngữ cảnh. Hiểu được những cơ chế này không làm cho trải nghiệm bớt ý nghĩa đi. Nếu có gì, nó trao cho bạn công cụ để làm cho trải nghiệm tốt hơn.
Những nền tảng đầu tư nghiêm túc vào hạ tầng bộ nhớ sẽ định hình thế hệ tiếp theo của người bạn đồng hành AI. Những nền tảng coi bộ nhớ như một tính năng làm cho có sẽ tụt lại phía sau. Và nếu bạn là kiểu người muốn kiểm soát tối đa, việc tự xây dựng hệ thống của riêng mình chưa bao giờ dễ tiếp cận hơn thế.
Dù bạn là người dùng bình thường muốn người bạn đồng hành AI của mình nhớ tên mình, hay một lập trình viên đang xây dựng nền tảng đồng hành tuyệt vời tiếp theo, cùng những nguyên tắc đó vẫn áp dụng: lưu trữ một cách có suy nghĩ, truy xuất một cách thông minh, và đừng bao giờ cố nhồi nhiều ký ức vào cửa sổ ngữ cảnh hơn mức nó có thể chứa. Công nghệ sẽ tiếp tục cải thiện. Cửa sổ ngữ cảnh sẽ lớn hơn. Các mô hình embedding sẽ thông minh hơn. Nhưng kiến trúc nền tảng, bộ nhớ bên ngoài đưa vào một mô hình phi trạng thái, sẽ còn ở lại với chúng ta một thời gian.
Và nếu bạn tò mò kiến trúc đó trông ra sao trong thực tế, hãy thử xây dựng một cái. Năm mươi dòng Python và một cơ sở dữ liệu vector miễn phí là tất cả những gì cần để nhìn ra sau tấm màn. Bạn có thể sẽ ngạc nhiên trước việc phép màu thực sự đơn giản đến mức nào.
Sẵn Sàng Tạo Influencer AI Của Bạn?
Tham gia cùng 115 học viên đang thành thạo ComfyUI và tiếp thị influencer AI trong khóa học 51 bài đầy đủ của chúng tôi.
Bài Viết Liên Quan

Ứng Dụng Bạn Trai AI 2026: Hướng Dẫn Toàn Diện Về Người Bạn Đồng Hành AI Nam
Khám phá những ứng dụng bạn trai AI tốt nhất năm 2026 với các đánh giá chi tiết về người bạn đồng hành AI nam. So sánh Replika, Nomi, Candy AI và các nền tảng chuyên biệt về chất lượng trò chuyện, khả năng tùy chỉnh và chiều sâu cảm xúc.

Ứng Dụng Bạn Đồng Hành AI Có Thực Sự Giúp Giảm Cô Đơn? Nghiên Cứu Nói Gì
Xem xét các nghiên cứu về việc liệu những ứng dụng bạn đồng hành AI như Replika giúp ích hay làm tình trạng cô đơn tệ hơn. Các nghiên cứu, rủi ro, lợi ích và một đánh giá trung thực.

Đạo Đức Của Trợ Lý AI Và Ranh Giới Lành Mạnh: Một Cách Tiếp Cận Cân Nhắc
Điều hướng các mối quan hệ trợ lý AI một cách đạo đức với ranh giới lành mạnh. Hướng dẫn sử dụng có trách nhiệm, tự nhận thức và tương tác AI cân bằng.