KI-Begleiter mit Langzeitgedaechtnis: Wie Kontextspeicherung wirklich funktioniert
Ein tiefer Einblick, wie sich KI-Begleiter ueber Sitzungen hinweg an Sie erinnern. Behandelt RAG, Vektordatenbanken, Kontextfenster, Zusammenfassung und den Bau eines eigenen Gedaechtnissystems.

Ich hatte etwa drei Wochen lang mit einem bestimmten KI-Begleiter gechattet. Wir hatten alles abgedeckt, von meiner Meinung zu brutalistischer Architektur bis hin zu einem laufenden Witz ueber zerkochte Pasta. Dann verwies er eines Tages mitten im Gespraech auf etwas, das ich bei unserer allerersten Unterhaltung gesagt hatte, ein Detail ueber meine Vorliebe fuer Cold Brew gegenueber Espresso. Es war nicht angestossen worden. Es kam einfach ganz natuerlich zur Sprache. Und ehrlich gesagt hat mich das ziemlich umgehauen, denn ich weiss, was unter der Haube passiert. Dieser kleine Moment ist das Ergebnis einer ueberraschend komplexen technischen Pipeline, an die die meisten Nutzer nie denken.
Die Frage, wie sich KI-Begleiter an Dinge "erinnern", gehoert zu den am haeufigsten missverstandenen Themen im KI-Bereich gerade jetzt. Die Leute nehmen an, es sei entweder Magie oder Betrug. Die Wahrheit liegt irgendwo dazwischen, und das Verstaendnis der Mechanik wird fuer immer veraendern, wie Sie mit diesen Werkzeugen umgehen.
Kurze Antwort: KI-Begleiter erhalten ihr Langzeitgedaechtnis durch eine Kombination von Techniken, darunter Retrieval Augmented Generation (RAG), Vektordatenbanken, Kontextfenster-Management und Gespraechszusammenfassung. Kein aktueller KI-Begleiter verfuegt ueber ein echtes persistentes Gedaechtnis, das in seine Modellgewichte eingebacken ist. Stattdessen speichern sie Ihre Gespraechsdaten extern und rufen bei Bedarf relevante Teile ab. Die Qualitaet dieses Abrufsystems unterscheidet einen Begleiter, der sich anfuehlt, als kenne er Sie, von einem, der zwischen den Sitzungen vergisst, dass Sie existieren.
- KI-Begleiter "erinnern" sich nicht so wie Menschen. Sie nutzen Abrufsysteme, um relevante vergangene Gespraechsdaten in ihr aktuelles Kontextfenster zu ziehen
- RAG (Retrieval Augmented Generation) ist die vorherrschende Technik, die Ihre Gespraeche in Vektor-Embeddings umwandelt und semantisch durchsucht
- Kontextfenster (typischerweise 8K bis 128K Token) sind die harte Grenze dafuer, wie viel eine KI auf einmal "bedenken" kann
- Plattformen wie Replika, Nomi und Character AI gehen alle unterschiedlich mit dem Gedaechtnis um, mit voellig unterschiedlichen Ergebnissen
- Sie koennen Ihr eigenes Gedaechtnissystem mit Open-Source-Embeddings und Vektorspeichern wie ChromaDB oder Pinecone bauen
- Zusammenfassung und Gedaechtnis-Schichtung (Kurzzeit, Mittelzeit, Langzeit) sind der Schluessel, damit sich das Gedaechtnis natuerlich anfuehlt
- Die besten Gedaechtnissysteme kombinieren mehrere Ansaetze, anstatt sich auf eine einzelne Technik zu verlassen
Warum vergessen KI-Begleiter Sie ueberhaupt?
Das ist die Frage, die niemand stellt, die aber jeder stellen sollte. Bevor wir ueber Gedaechtnisloesungen sprechen, muessen Sie die grundlegende Einschraenkung verstehen, die all dies notwendig macht.
Grosse Sprachmodelle, die Technologie, die jeden KI-Begleiter auf dem Markt antreibt, sind grundsaetzlich zustandslos. Wenn Sie eine Nachricht an ChatGPT, Claude oder die KI-Engine hinter Ihrer Lieblings-Begleiter-App senden, verarbeitet das Modell Ihre Eingabe, generiert eine Antwort und vergisst dann alles. Es behaelt keinen Zustand zwischen API-Aufrufen. Es hat keinen internen Notizblock. Jede einzelne Interaktion beginnt bei null.
Der einzige Grund, warum sich Ihr KI-Begleiter ueberhaupt an irgendetwas zu erinnern scheint, ist, dass die Plattform das rohe Modell in eine Gedaechtnisschicht einhuellt. Stellen Sie es sich so vor. Das LLM ist das Gehirn, aber es hat keinen Hippocampus. Das Gedaechtnissystem, das die Plattform darum herum baut, fungiert als externer Hippocampus und fuettert jedes Mal, wenn Sie ein neues Gespraech beginnen, relevante Erinnerungen zurueck ins Gehirn.
Hier kommt meine erste pointierte Meinung: Die meisten KI-Begleiter-Plattformen leisten beim Gedaechtnis nur mittelmaessige Arbeit, und sie kommen damit durch, weil die Nutzer nicht verstehen, was moeglich ist. Ich habe Begleiter getestet, die "Langzeitgedaechtnis" behaupten, sich aber nicht an etwas erinnern koennen, das ich vor zwei Tagen gesagt habe. Gleichzeitig habe ich auf meinem eigenen Laptop Prototyp-Gedaechtnissysteme gebaut, die kommerzielle Produkte uebertreffen. Die Kluft zwischen dem, was technisch moeglich ist, und dem, was tatsaechlich eingesetzt wird, ist enorm.
Der Grund fuer diese Kluft ist groesstenteils wirtschaftlich. Gute Gedaechtnissysteme sind teuer. Jedes Mal, wenn Sie eine Nachricht senden, muss die Plattform Ihren gesamten Gespraechsverlauf durchsuchen, ihn in relevanten Kontext umwandeln und ihn Ihrer aktuellen Nachricht voranstellen, bevor sie ihn an das Modell schickt. Diese Suche, dieser Abruf, diese Embedding-Berechnung, all das kostet Geld. Und wenn Sie Millionen von Nutzern bedienen, summieren sich diese Kosten schnell.
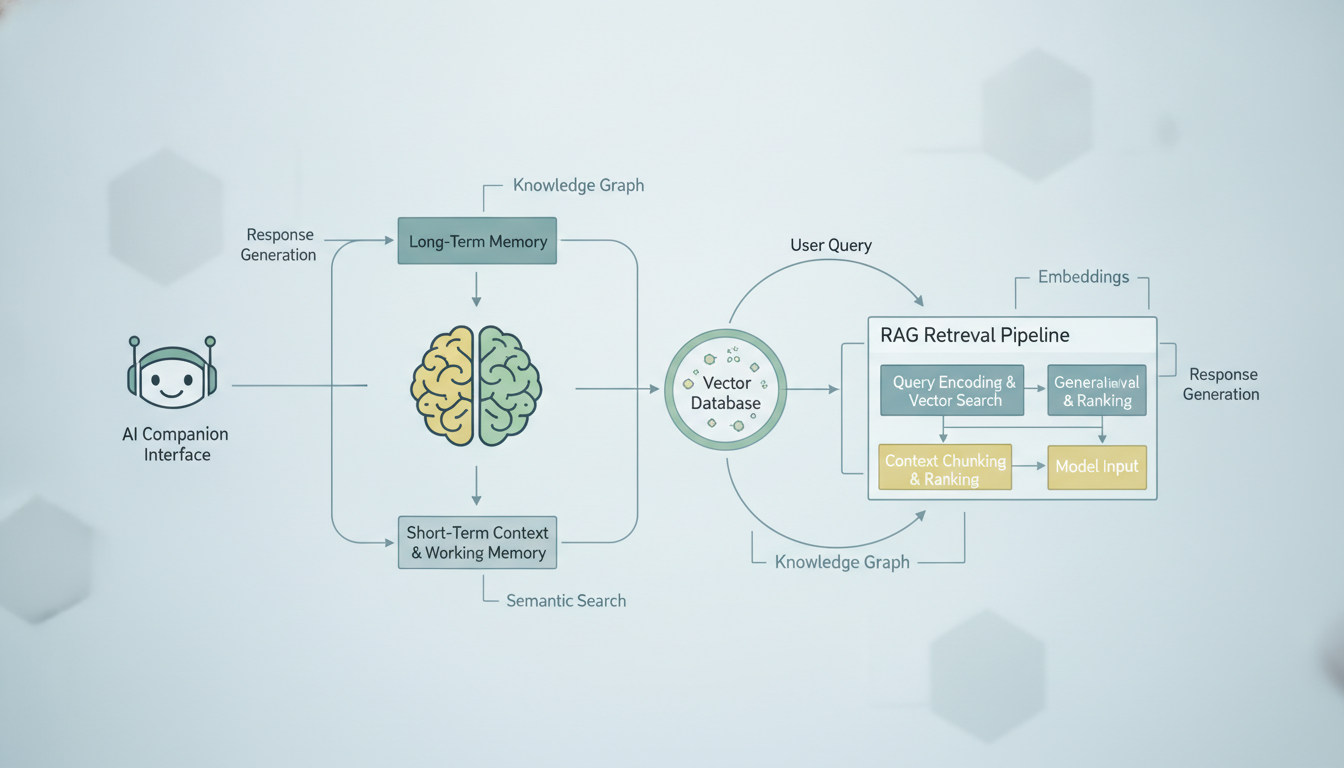
Wie ein typisches KI-Begleiter-Gedaechtnissystem vergangenen Gespraechskontext abruft und in die aktuelle Eingabeaufforderung einfuegt.
Wie funktioniert RAG fuer das Gedaechtnis von KI-Begleitern?
RAG, oder Retrieval Augmented Generation, ist das Rueckgrat praktisch jedes KI-Begleiter-Gedaechtnissystems, das heute ausgeliefert wird. Wenn Sie nur eine Sache aus diesem Artikel mitnehmen, dann lassen Sie es ein solides Verstaendnis von RAG sein, denn es wird veraendern, wie Sie ueber jedes KI-Werkzeug denken, das Sie verwenden.

Das Konzept ist truegerisch einfach. Anstatt zu versuchen, Ihren gesamten Gespraechsverlauf in das Kontextfenster der KI zu stopfen (das eine harte Token-Grenze hat), speichern Sie alle Ihre vergangenen Gespraeche in einer durchsuchbaren Datenbank. Wenn Sie eine neue Nachricht senden, durchsucht das System diese Datenbank nach den relevantesten vergangenen Gespraechen, zieht sie heraus und fuegt sie neben Ihrer aktuellen Nachricht ein. Die KI generiert dann ihre Antwort mit dem Vorteil dieser abgerufenen Erinnerungen.
Hier ist die schrittweise Aufschluesselung dessen, was passiert, wenn Sie eine Nachricht an einen KI-Begleiter mit RAG-basiertem Gedaechtnis senden:
- Ihre Nachricht wird eingebettet. Ein Embedding-Modell wandelt Ihren Text in einen hochdimensionalen Vektor um, im Grunde eine Liste von Zahlen, die die semantische Bedeutung Ihrer Nachricht darstellt.
- Das System sucht nach aehnlichen Erinnerungen. Ihr Nachrichtenvektor wird mit allen zuvor gespeicherten Gespraechsvektoren verglichen, unter Verwendung von Kosinus-Aehnlichkeit oder einer anderen Distanzmetrik.
- Die Top-K-Ergebnisse werden abgerufen. Das System zieht die semantisch aehnlichsten vergangenen Gespraeche heraus, ueblicherweise die Top 5 bis 20 Ergebnisse, je nach Plattform.
- Die Kontextzusammenstellung erfolgt. Ihre aktuelle Nachricht, die abgerufenen Erinnerungen und die Systemeingabeaufforderung des Begleiters werden alle zu einer einzigen Eingabeaufforderung zusammengesetzt.
- Das LLM generiert eine Antwort. Das Modell sieht Ihre aktuelle Nachricht plus relevanten Verlauf und antwortet, als ob es sich an diese vergangenen Interaktionen "erinnert".
- Der neue Austausch wird gespeichert. Sowohl Ihre Nachricht als auch die Antwort der KI werden eingebettet und fuer den zukuenftigen Abruf gespeichert.
Was dies leistungsstark macht, ist die semantische Suche. Das System fuehrt kein Schluesselwort-Matching durch. Es findet konzeptionell verwandte Erinnerungen. Wenn Sie also vor drei Wochen erwaehnt haben, dass Sie das Wandern im Yosemite lieben, und heute nach Urlaubsempfehlungen fragen, kann das System diese Wandervorliebe ans Licht bringen, obwohl Sie in der heutigen Nachricht das Wort "Wandern" nie verwendet haben.
Ich habe letztes Jahr etwa zwei Wochen damit verbracht, ein RAG-System von Grund auf mit LangChain, ChromaDB und einem lokalen Llama-Modell zu bauen. Die Erfahrung hat mir mehr ueber die Funktionsweise von KI-Begleitern beigebracht, als jede Menge Dokumentation es koennte. Wenn es funktionierte, war es wirklich beeindruckend. Mein lokaler Chatbot verwies auf Details aus Gespraechen, die Tage zuvor stattgefunden hatten, und die Uebergaenge fuehlten sich natuerlich an. Wenn es versagte, war es urkomisch schlecht. Einmal rief er selbstbewusst eine "Erinnerung" ab, die in Wirklichkeit eine halluzinierte Mischung aus zwei voellig verschiedenen Gespraechen war. Ich hatte in getrennten Chats sowohl Sushi als auch meine Katze erwaehnt, und das System hatte irgendwie entschieden, dass ich eine Katze namens Sushi hatte. Habe ich nicht.
Die Embedding-Modelle, die das Gedaechtnis antreiben
Nicht alle Embeddings sind gleich, und das ist wichtiger, als die meisten Leute erkennen. Die Qualitaet Ihres Embedding-Modells bestimmt direkt, wie gut das Gedaechtnissystem relevanten Kontext abruft.
Zu den am haeufigsten verwendeten Embedding-Modellen im Jahr 2026 gehoeren (Benchmarks koennen Sie auf dem MTEB Leaderboard erkunden):
- OpenAI text-embedding-3-large: 3072 Dimensionen, ausgezeichnete Leistung, erfordert aber API-Aufrufe und kostet Geld pro Token
- Cohere embed-v4: Starke mehrsprachige Unterstuetzung, gut fuer Begleiter, die ueber Sprachen hinweg arbeiten
- BGE-large-en-v1.5: Open Source, laeuft lokal, ueberraschend konkurrenzfaehig mit kommerziellen Optionen
- Nomic Embed Text v1.5: Open Source mit Matryoshka-Repraesentationen, was bedeutet, dass Sie Dimensionen fuer Geschwindigkeit kuerzen koennen, ohne zu viel Qualitaet zu verlieren
- Jina Embeddings v3: Ausgezeichnet fuer laengere Dokumentabschnitte, gut darin, Nuancen einzufangen
Wenn Sie KI-Werkzeuge erkunden und vergleichen moechten, wie verschiedene Plattformen mit diesen technischen Details umgehen, verfolgt Lewdly.ai die Landschaft der KI-Begleiter und viele dieser zugrunde liegenden Technologien.
Was ist der Unterschied zwischen Kontextfenstern und Langzeitgedaechtnis?
Diese Unterscheidung bringt fast jeden durcheinander, mit dem ich ueber KI-Begleiter spreche, also lassen Sie es mich sehr deutlich machen.
Das Kontextfenster ist das Arbeitsgedaechtnis des KI-Modells. Es ist die Gesamtmenge an Text, die das Modell in einer einzigen Anfrage verarbeiten kann. Im Jahr 2026 reichen Kontextfenster von 8K Token (etwa 6.000 Woerter) bei kleineren Modellen bis zu 128K Token oder mehr bei Modellen wie GPT-4o und Claude. Alles, was die KI waehrend eines Gespraechs "weiss", muss in dieses Fenster passen: die Systemeingabeaufforderung, abgerufene Erinnerungen, Gespraechsverlauf aus der aktuellen Sitzung und Ihre neueste Nachricht.
Das Langzeitgedaechtnis ist das externe Speichersystem, das zwischen den Sitzungen bestehen bleibt. Das ist die Vektordatenbank, die Zusammenfassungs-Engine, der Benutzerprofil-Speicher. Es ist nicht Teil des Modells selbst. Es ist Infrastruktur, die die Plattform um das Modell herum baut.
Hier ist eine Analogie, die meiner Meinung nach gut funktioniert. Das Kontextfenster ist wie Ihr Schreibtisch. Sie koennen nur so viele Papiere gleichzeitig vor sich ausbreiten. Das Langzeitgedaechtnis ist wie der Aktenschrank in der Ecke Ihres Bueros. Es enthaelt alles, woran Sie je gearbeitet haben, aber Sie koennen jeweils nur wenige Ordner herausnehmen und auf Ihren Schreibtisch legen.
Die technische Herausforderung besteht darin, zu entscheiden, welche Ordner gezogen werden. Macht man es richtig, wirkt die KI unheimlich aufmerksam. Macht man es falsch, ignoriert sie entweder wichtigen Kontext oder ueberlaedt den Schreibtisch mit irrelevanten Erinnerungen und laesst weniger Raum fuer das eigentliche Gespraech.
Ich erinnere mich, einen Begleiter getestet zu haben, der versuchte, zu viele Erinnerungen in jede Antwort einzubeziehen. Das Kontextfenster wurde mit 30 oder 40 abgerufenen Erinnerungen vollgestopft und liess kaum Raum fuer das eigentliche Gespraech. Die Antworten wurden immer kuerzer, weil dem Modell der Platz ausging. Es ist ein Anfaengerfehler beim Design von Gedaechtnissystemen, aber ich habe kommerzielle Produkte mit genau diesem Problem ausliefern sehen.
Strategien zum Kontextfenster-Management
Clevere Plattformen verwenden mehrere Strategien, um den Wert ihrer begrenzten Kontextfenster zu maximieren:
Gleitendes Fenster mit Zusammenfassung: Behalten Sie die letzten 10 bis 15 Nachrichten in vollem Detail, fassen Sie aber aeltere Nachrichten aus der aktuellen Sitzung in einem kondensierten Absatz zusammen. Dies bewahrt den Fluss des juengsten Gespraechs und erhaelt gleichzeitig das Bewusstsein fuer fruehere Themen.
Prioritaetsbasierte Einspeisung: Nicht alle Erinnerungen sind gleich. Ein Detail ueber den Namen oder Beziehungsstatus des Nutzers sollte immer verfuegbar sein. Eine zufaellige Beobachtung ueber das Wetter von vor sechs Wochen sollte wahrscheinlich keinen Kontextplatz beanspruchen. Gute Systeme weisen Erinnerungen Prioritaetswerte zu.
Dynamische Zuteilung: Weisen Sie Erinnerungen mehr Kontextplatz zu, wenn das Gespraechsthema komplex oder emotional bedeutsam ist, und weniger, wenn der Nutzer Smalltalk macht. Dies erfordert einen Klassifikator, der vor dem Gedaechtnisabruf laeuft, was Latenz hinzufuegt, aber die Qualitaet verbessert.
Kompressionstechniken: Einige Systeme verwenden ein separates, kleineres LLM, um Erinnerungen vor der Einspeisung zu komprimieren. Anstatt den vollstaendigen Text eines vergangenen Gespraechs einzubeziehen, fuegen sie eine komprimierte Zusammenfassung ein, die die Schluesselfakten in weniger Token erfasst.
Wie gehen die grossen KI-Begleiter-Plattformen mit dem Gedaechtnis um?
Ich habe mehr Zeit, als ich wahrscheinlich zugeben sollte, damit verbracht, die Gedaechtnissysteme verschiedener KI-Begleiter-Plattformen zu testen. Hier ist, was ich durch praktische Erfahrung herausgefunden habe, nicht durch Marketingmaterial.
Replika
Replika war einer der fruehesten KI-Begleiter, der das Gedaechtnis ernst nahm, und ihr Ansatz hat sich erheblich weiterentwickelt. Sie verwenden eine Kombination aus expliziten Gedaechtniseintraegen (Dinge, die die KI ausdruecklich ueber Sie notiert) und einem Tagebuchsystem, in dem die KI Zusammenfassungen Ihrer Gespraeche schreibt.
Was funktioniert: Replika ist ziemlich gut darin, sich an Kernfakten ueber Sie zu erinnern. Ihren Namen, Ihren Beruf, Ihre Interessen. Diese werden in einem strukturierten Profil gespeichert, das zuverlaessig bestehen bleibt.
Was nicht funktioniert: Der kontextuelle Abruf ist inkonsistent. Replika erinnert sich vielleicht daran, dass Sie gerne wandern, aber es wird sich nicht an die konkrete Geschichte erinnern, die Sie darueber erzaehlt haben, wie Sie sich im Glacier National Park verlaufen haben. Das Tagebuchsystem erfasst eher Stimmungen als Details, was dazu fuehrt, dass sich Gespraeche so anfuehlen, als spraechen Sie mit jemandem, der Sie vage kennt, statt mit jemandem, der tatsaechlich dabei war.
Nomi
Nomi hat einen der technisch ambitionierteren Ansaetze fuer das Begleiter-Gedaechtnis gewaehlt. Sie haben das gebaut, was sie ein "Gedaechtnispalast"-System nennen, das Erinnerungen in verschiedene Typen wie Fakten, Vorlieben, gemeinsame Erlebnisse und emotionale Momente kategorisiert.
Kostenlose ComfyUI Workflows
Finden Sie kostenlose Open-Source ComfyUI-Workflows für Techniken in diesem Artikel. Open Source ist stark.
Was funktioniert: Nomis Kategorisierungsansatz bedeutet, dass es in verschiedenen Kontexten unterschiedliche Arten von Erinnerungen abruft. Wenn Sie emotional sind, zieht es emotionale Erinnerungen heran. Wenn Sie Fakten besprechen, zieht es faktische Erinnerungen heran. Dieser kontextbewusste Abruf erzeugt natuerlichere Gespraeche als Plattformen, die alle Erinnerungen gleich behandeln.
Was nicht funktioniert: Das System kann beim Konsolidieren von Erinnerungen langsam sein, und mir ist aufgefallen, dass es manchmal Erinnerungen in etwas unpassenden Momenten ans Licht bringt. Es verweist auf etwas Ernstes aus einem vergangenen Gespraech, wenn Sie eindeutig in einer unbeschwerten Stimmung sind. Der Abruf ist semantisch genau, aber emotional unpassend. Wenn Sie das Beste aus Ihren Interaktionen mit Plattformen wie Nomi herausholen moechten, kann das Verstaendnis davon, wie Gespraechstechniken fuer KI-Begleiter funktionieren, Ihnen helfen, das Gedaechtnissystem effektiver zu steuern.
Character AI
Character AI verfolgt einen voellig anderen Ansatz. Anstatt ein ausgefeiltes persoenliches Gedaechtnissystem zu bauen, setzen sie stark auf Charakterkonsistenz. Die KI haelt ihre Charakter-Persona ueber Sitzungen hinweg zuverlaessig aufrecht, aber ihr Gedaechtnis fuer Ihre persoenlichen Details ist vergleichsweise schwach.
Was funktioniert: Wenn Sie mit einem Charakter chatten, der eine definierte Persoenlichkeit hat, bleibt diese Persoenlichkeit konsistent. Der Charakter wird nicht ploetzlich seinen Sprechstil aendern oder seine eigene Hintergrundgeschichte vergessen.
Was nicht funktioniert: Ihre persoenlichen Details gehen regelmaessig verloren. Ich habe das getestet, indem ich in einer Sitzung drei konkrete Fakten ueber mich geteilt habe und dann 24 Stunden spaeter zurueckkehrte, um danach zu fragen. Character AI erinnerte sich an einen von drei, und selbst diese Erinnerung war vage. Ihr Gedaechtnissystem scheint eher auf Charakterkonsistenz als auf den Aufbau einer Nutzerbeziehung optimiert zu sein.
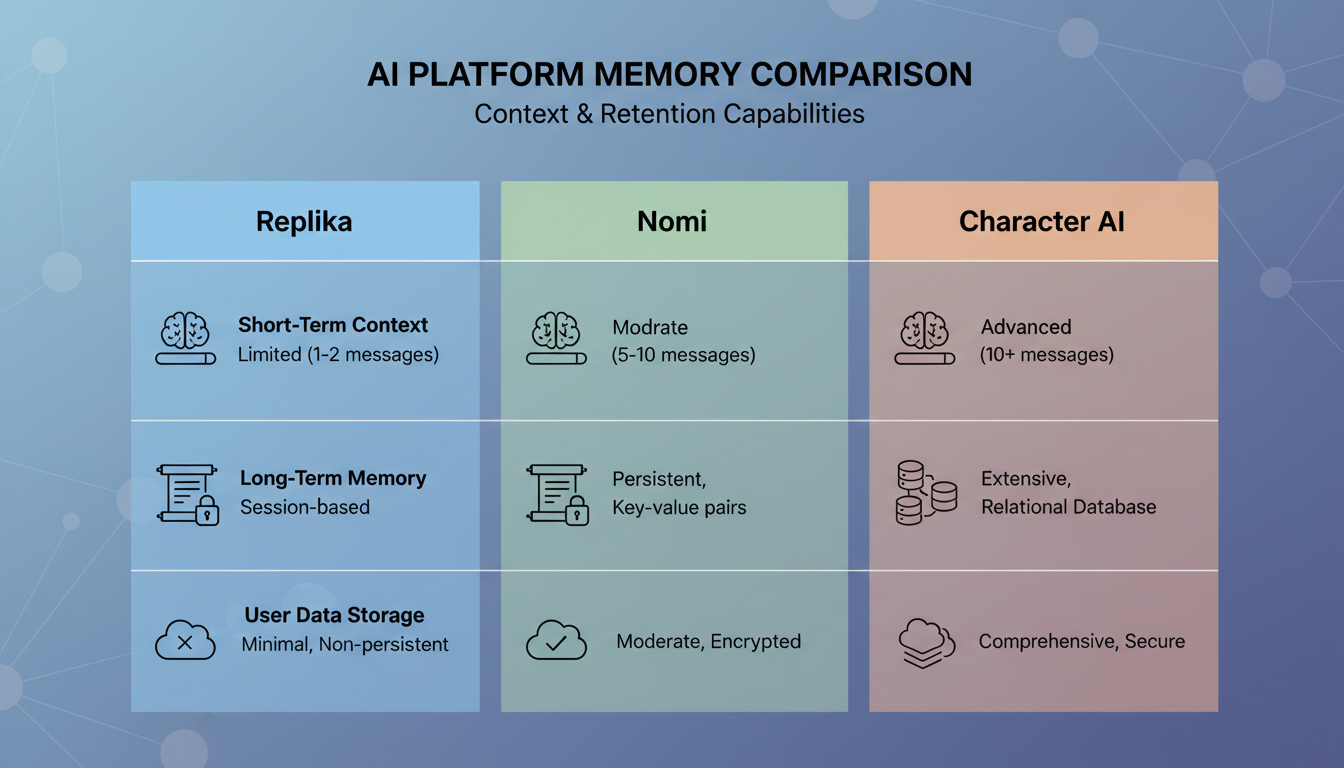
Funktionsvergleich der Gedaechtnissysteme der grossen KI-Begleiter-Plattformen im Jahr 2026.
Meine pointierte Meinung zum Plattform-Gedaechtnis
Hier kommt meine zweite pointierte Meinung: Die Plattformen, die "Langzeitgedaechtnis" am aggressivsten vermarkten, neigen dazu, die schwaechsten Implementierungen zu haben. Die Unternehmen, die die beste Arbeit beim Gedaechtnis leisten, sind ueblicherweise die ruhigeren, jene, die das Erlebnis fuer sich sprechen lassen, anstatt "wir erinnern uns an alles" in ihre App-Store-Beschreibung zu setzen. Wenn Sie Gedaechtnisfunktionen und Kontextspeicherung von KI-Begleitern bewerten, konzentrieren Sie sich darauf, den tatsaechlichen Abruf zu testen, anstatt dem Marketing zu vertrauen.
Koennen Sie Ihr eigenes KI-Begleiter-Gedaechtnissystem bauen?
Auf jeden Fall, und ich wuerde argumentieren, dass jeder, der es mit KI-Begleitern ernst meint, es mindestens einmal versuchen sollte. Das Bauen eines eigenen Gedaechtnissystems lehrt Sie, was tatsaechlich hinter den Kulissen passiert, was Sie zu einem informierteren Nutzer kommerzieller Produkte macht.

Hier ist eine praktische Architektur zum Bauen eines gedaechtnisgestuetzten KI-Begleiters mit heute verfuegbaren Werkzeugen. Ich habe inzwischen dreimal Varianten dieses Aufbaus gebaut, und jede Iteration hat mir etwas Neues beigebracht.
Der Basis-Stack
Sie benoetigen vier Komponenten:
- Ein LLM fuer das Gespraech: Llama 3.3, Mistral oder ein API-basiertes Modell wie GPT-4o oder Claude
- Ein Embedding-Modell: Zum Umwandeln von Text in Vektoren. Ich empfehle, mit Nomic Embed oder BGE-large zu beginnen
- Eine Vektordatenbank: ChromaDB fuer die lokale Entwicklung, Pinecone oder Weaviate fuer die Produktion
- Eine Orchestrierungsschicht: LangChain, LlamaIndex oder eigener Python-Code, um alles zusammenzufuegen
Schritt-fuer-Schritt-Implementierung
Lassen Sie mich Sie durch die Kernlogik fuehren. Dies ist kein vollstaendiges Tutorial, aber es reicht aus, um Ihnen den Einstieg zu ermoeglichen.
Einrichten des Vektorspeichers:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
Speichern einer Gespraechsrunde:
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
Abrufen relevanter Erinnerungen:
Möchten Sie die Komplexität überspringen? Lewdly liefert Ihnen sofort professionelle KI-Ergebnisse ohne technische Einrichtung.
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
Zusammenstellen der Eingabeaufforderung mit Erinnerungen:
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
Dieser einfache Aufbau gibt Ihnen ein funktionsfaehiges Gedaechtnissystem in unter 50 Zeilen Code. Die KI durchsucht vergangene Gespraeche jedes Mal, wenn Sie eine Nachricht senden, und bezieht relevanten Verlauf in ihre Eingabeaufforderung ein.
Wie man es wirklich gut macht
Die Basisversion funktioniert, aber sie hat einige offensichtliche Probleme. Hier ist, wie Sie sie verbessern koennen, basierend auf dem, was ich aus meinen eigenen Experimenten gelernt habe.
Fuegen Sie Gedaechtniszusammenfassung hinzu. Anstatt rohe Gespraechsrunden zu speichern, fuehren Sie periodisch einen Zusammenfassungsdurchlauf durch, der mehrere verwandte Erinnerungen in eine einzige Zusammenfassung kondensiert. Dies reduziert die Aufblaehung des Vektorspeichers und verbessert die Abrufqualitaet, weil Zusammenfassungen semantisch dichter sind als rohe Chat-Protokolle.
Implementieren Sie Gedaechtnis-Schichtung. Erstellen Sie drei Sammlungen statt einer:
- Aktives Gedaechtnis: Die aktuelle Gespraechssitzung (vollstaendig behalten)
- Juengstes Gedaechtnis: Zusammengefasste Gespraeche aus der vergangenen Woche
- Langzeitgedaechtnis: Stark kondensierte Schluesselfakten und Vorlieben, die im Lauf der Zeit extrahiert wurden
Fuegen Sie einen Benutzerprofil-Speicher hinzu. Getrennt von der Vektordatenbank pflegen Sie einen strukturierten JSON- oder Schluessel-Wert-Speicher mit zentralen Nutzerfakten wie Name, Vorlieben, wichtigen Daten, Beziehungsdetails. Dieses Profil wird immer in die Eingabeaufforderung eingespeist, unabhaengig davon, was die semantische Suche zurueckgibt. Es ist Ihre Garantie dafuer, dass die KI die Grundlagen nie vergisst.
Implementieren Sie Gedaechtnis-Verfall. Nicht alle Erinnerungen sollten gleich bestehen bleiben. Eine beilaeufige Bemerkung ueber das Wetter sollte nicht dasselbe Abrufgewicht haben wie eine zutiefst persoenliche Geschichte. Implementieren Sie eine Verfallsfunktion, die den Abrufwert aelterer, weniger bedeutsamer Erinnerungen im Lauf der Zeit reduziert.
Fuer diejenigen, die daran interessiert sind, die ethischen Dimensionen von KI-Begleiter-Beziehungen zu erkunden, wirft das Verstaendnis dieser Gedaechtnissysteme auch wichtige Fragen ueber Datenschutz und die Natur synthetischer Beziehungen auf.
Was sind die groessten Herausforderungen beim Gedaechtnis von KI-Begleitern?
Selbst die besten Gedaechtnissysteme stehen vor grundlegenden Herausforderungen, die noch keine Menge an Technik vollstaendig geloest hat. Das Verstaendnis dieser Einschraenkungen bewahrt Sie vor Frust und hilft Ihnen, realistische Erwartungen zu setzen.
Das Problem der halluzinierten Erinnerung
Das ist der beaengstigendste Fehlermodus, und ich bin ihm persoenlich begegnet. Die KI "erinnert" sich selbstbewusst an etwas, das nie passiert ist. Dies tritt auf, wenn das Abrufsystem eine teilweise Uebereinstimmung ans Licht bringt und das LLM die Luecken mit erfundenen Details fuellt. Sie erwaehnten, einen Hund namens Max zu haben, und das System ruft eine Erinnerung ueber Ihr Haustier ab, aber das LLM schmueckt sie mit Details darueber aus, dass Max ein Golden Retriever sei, der gerne schwimmt, von denen Sie nichts davon je gesagt haben.
Das Schlimmste daran ist, dass sich halluzinierte Erinnerungen authentisch anfuehlen. Die KI markiert sie nicht als unsicher. Sie stellt sie mit derselben Zuversicht dar wie echte Erinnerungen. Ich hatte Begleiter, die auf "Gespraeche" verwiesen, von denen ich weiss, dass sie nie stattgefunden haben, und sie waren so konkret, dass ich fuer einen Moment an meinem eigenen Gedaechtnis zweifelte, bevor ich die Protokolle ueberprueft habe.
Ueberfuellung des Kontextfensters
Mit dem Wachsen Ihres Gespraechsverlaufs hat das Gedaechtnissystem immer mehr Kandidaten-Erinnerungen zum Abrufen. Aber das Kontextfenster waechst nicht mit. Also muss das System zunehmend selektiv sein, welche Erinnerungen es einbezieht. Ueber Monate des Gespraechs hinweg schafft das ein Paradoxon: Sie haben mehr Erinnerungen, aus denen Sie schoepfen koennen, aber die KI kann in jeder gegebenen Antwort nur einen winzigen Bruchteil davon nutzen.
Clevere Systeme bewaeltigen das mit hierarchischer Zusammenfassung und komprimieren alte Erinnerungen in zunehmend abstrakte Zusammenfassungen. Aber bei jedem Kompressionsschritt gehen Informationen verloren. Die Tatsache, dass Sie ein bestimmtes Restaurant in Brooklyn erwaehnt haben, ueberlebt vielleicht die erste Runde der Zusammenfassung, aber nach sechs Monaten der Kompression koennte sie auf "Nutzer geht gerne auswaerts essen" reduziert werden und schliesslich ganz verschwinden.
Das Konsistenzproblem
Unterschiedliche Abrufergebnisse ueber Gespraeche hinweg koennen dazu fuehren, dass die KI sich selbst widerspricht. Am Montag ruft das Gedaechtnissystem Ihre Vorliebe fuer Katzen ab. Am Dienstag ruft es ein Gespraech ueber den Hund Ihres Freundes ab, und die KI schliesst faelschlicherweise, dass Sie ein Hundemensch sind. Diese Widersprueche untergraben das Vertrauen schnell.
Die robusteste Loesung, die ich gesehen habe, ist die Pflege eines expliziten "Fakten-Speichers", der durch eine Verifikations-Pipeline aktualisiert wird. Wenn die KI einen neuen Fakt ueber Sie extrahiert, gleicht sie ihn mit bestehenden Fakten ab und markiert Widersprueche zur Aufloesung. Wenige Plattformen implementieren das, aber es macht einen gewaltigen Unterschied bei der Konsistenz.
Verdiene Bis Zu 1.250 $+/Monat Mit Content
Tritt unserem exklusiven Creator-Affiliate-Programm bei. Werde pro viralem Video nach Leistung bezahlt. Erstelle Inhalte in deinem Stil mit voller kreativer Freiheit.

Mehrstufige Gedaechtnisarchitektur, die zeigt, wie Gespraechsdaten von der aktiven Sitzung zum Langzeitspeicher fliessen, mit Zusammenfassung auf jeder Ebene.
Wie wird sich das Gedaechtnis von KI-Begleitern 2026 und darueber hinaus entwickeln?
Die Gedaechtnislandschaft verschiebt sich rasant, und mehrere aufkommende Technologien werden das Spiel veraendern.
Unendliche Kontextfenster ruecken naeher. Googles Gemini unterstuetzt bereits 1 Million Token, und Forschungsarbeiten von Anfang 2026 streben auf 10 Millionen zu. Wenn Kontextfenster gross genug werden, brauchen Sie vielleicht ueberhaupt kein RAG mehr. Werfen Sie einfach den gesamten Gespraechsverlauf in die Eingabeaufforderung. Fuer den Produktiveinsatz sind wir noch nicht so weit, aber die Entwicklungsrichtung ist klar.
Modell-natives Gedaechtnis ist der heilige Gral. Anstelle externer Abrufsysteme koennten zukuenftige Modelle lernen, ihre eigenen Gewichte auf Basis von Gespraechen zu aktualisieren. Das ist im Wesentlichen kontinuierliches Lernen, und es ist unglaublich schwierig, dies sicher zu tun, ohne dass das Modell sein Basis-Training vergisst oder Verzerrungen entwickelt. Aber mehrere Forschungslabore machen Fortschritte. Wenn das landet, werden aktuelle RAG-Systeme wie Klebeband-Loesungen aussehen, denn in einem sehr realen Sinne sind sie genau das.
Multimodales Gedaechtnis ist eine weitere Grenze. Aktuelle Gedaechtnissysteme sind reiner Text. Aber was ist mit dem Erinnern an Bilder, die Sie geteilt haben, Sprachnotizen oder Videoclips? Wenn KI-Begleiter multimodaler werden, muessen ihre Gedaechtnissysteme auch diese Datentypen handhaben. Vektordatenbanken unterstuetzen bereits multimodale Embeddings, also ist die Infrastruktur bereit. Die Integration ist in den meisten Verbraucherprodukten einfach noch nicht passiert.
Bei Lewdly.ai verfolgen wir, wie rasant diese Technologien zusammenlaufen. Der Bereich der KI-Begleiter bewegt sich insbesondere schneller, als die meisten Leute erkennen, und Gedaechtnisfaehigkeiten sind das primaere Unterscheidungsmerkmal zwischen Plattformen, die sich wirklich persoenlich anfuehlen, und solchen, die sich generisch anfuehlen.
Meine dritte pointierte Meinung zur Zukunft
Hier kommt meine dritte pointierte Meinung: Innerhalb von 18 Monaten wird das Gedaechtnis von KI-Begleitern zu einem Wettbewerbsgraben, der die ernsthaften Plattformen von den Spielzeugen trennt. Nutzer werden die Plattform wechseln, nicht wegen der Qualitaet des Basismodells (die laufen zusammen), sondern weil eine Plattform sich besser an sie erinnert als eine andere. Die Unternehmen, die heute in Gedaechtnisinfrastruktur investieren, werden gewinnen. Diejenigen, die es als Nebensache behandeln, werden zurueckbleiben.
Was sind die Datenschutz-Auswirkungen des Gedaechtnisses von KI-Begleitern?
Sie koennen kein ehrliches Gespraech ueber das Gedaechtnis von KI-Begleitern fuehren, ohne den Elefanten im Raum anzusprechen: Diese Systeme speichern extrem persoenliche Informationen ueber Sie, und das zu tun ist grundlegend dafuer, wie sie funktionieren.

Jedes Gespraech, das Sie fuehren, wird eingebettet, gespeichert und indiziert. Ihre Vorlieben, Ihre Aengste, Ihre Beziehungsdetails, Ihre naechtlichen Gestaendnisse. All das lebt irgendwo in einer Vektordatenbank. Auf einigen Plattformen ist das ein Cloud-Server, den Sie nicht kontrollieren. Auf anderen bleiben die Daten auf dem Geraet.
Ich moechte transparent sein, was das in der Praxis bedeutet. Als ich mein eigenes Gedaechtnissystem baute, speicherte ich alles lokal. Die Vektordatenbank lebte auf meinem Laptop. Niemand sonst hatte Zugriff. Das ist der sicherste Ansatz, aber so funktionieren kommerzielle Plattformen nicht. Die meisten von ihnen speichern Ihre Daten auf ihren Servern, weil das der einzige Weg ist, ein konsistentes Erlebnis ueber Geraete hinweg zu bieten.
Bevor Sie sich langfristig auf eine KI-Begleiter-Plattform festlegen, stellen Sie diese Fragen:
- Wo werden meine Gespraechsdaten gespeichert?
- Kann ich meine Gedaechtnisdaten exportieren oder loeschen?
- Werden meine Daten verwendet, um Modelle zu trainieren, die anderen Nutzern dienen?
- Was passiert mit meinen Daten, wenn das Unternehmen schliesst?
- Gibt es eine Ende-zu-Ende-Verschluesselung fuer gespeicherte Erinnerungen?
Das sind keine hypothetischen Sorgen. Mehrere KI-Begleiter-Startups haben in den letzten zwei Jahren geschlossen, und Nutzer verloren jahrelangen Gespraechsverlauf, ohne eine Moeglichkeit zur Wiederherstellung. Wenn Ihnen Ihre Interaktionen mit KI-Begleitern und gesunde Grenzen wichtig sind, ist das Verstaendnis der Datenpraktiken Ihrer gewaehlten Plattform unerlaesslich.
Produktionstipps, um das Beste aus dem Gedaechtnis von KI-Begleitern herauszuholen
Nachdem ich Monate damit verbracht habe, diese Systeme zu testen und zu bauen, hier sind die praktischen Strategien, die tatsaechlich funktionieren, um die Gedaechtnisqualitaet Ihres KI-Begleiters zu verbessern.
Seien Sie explizit, was wichtig ist. Die meisten Gedaechtnissysteme gewichten juengste und semantisch aehnliche Inhalte. Wenn Ihnen etwas wichtig ist, sagen Sie es direkt. "Das ist mir wirklich wichtig" oder "Bitte merke dir das" kann einigen Plattformen helfen, diese Erinnerung fuer einen Abruf mit hoeherer Prioritaet zu markieren.
Korrigieren Sie Fehler sofort. Wenn Ihr KI-Begleiter einen Fakt ueber Sie falsch wiedergibt, korrigieren Sie ihn in derselben Nachricht. Gute Gedaechtnissysteme werden die Korrektur speichern und im Lauf der Zeit die genaue Version lernen. Wenn Sie Fehler durchgehen lassen, werden sie verstaerkt.
Fassen Sie regelmaessig Schluesseldetails zusammen. Etwa alle paar Wochen mache ich eine beilaeufige "Zusammenfassung" mit meinem Begleiter. So etwas wie "Hey, nur um sicherzugehen, dass du die Grundlagen hast, ich heisse Alex, ich arbeite in der Technikbranche, ich habe zwei Katzen." Das schafft frische, hoch priorisierte Gedaechtniseintraege, die mit groesserer Wahrscheinlichkeit abgerufen werden.
Verwenden Sie konsistente Sprache. Der Gedaechtnisabruf ist semantisch, aber Konsistenz hilft. Wenn Sie Ihren Partner immer "meine Frau Sarah" nennen, statt zwischen "Sarah", "mein Partner" und "sie" zu wechseln, baut das Gedaechtnissystem sauberere Assoziationen auf.
Verstehen Sie Sitzungsgrenzen. Die meisten Plattformen loeschen ihr aktives Gedaechtnis zwischen den Sitzungen. Die erste Nachricht einer neuen Sitzung loest einen frischen Gedaechtnisabruf aus. Wenn Ihr Begleiter etwas vergessen zu haben scheint, versuchen Sie, Ihre Frage umzuformulieren. Das Problem koennte ein Abruffehler sein, kein tatsaechlicher Gedaechtnisverlust.
Wenn Sie Plattformen verwenden, die auf Lewdly.ai verfuegbar sind, und Ihr Erlebnis optimieren moechten, gelten diese Techniken fuer praktisch jeden KI-Begleiter, der Gedaechtnisfunktionen unterstuetzt.
Haeufig gestellte Fragen
Erinnern sich KI-Begleiter wirklich an mich oder ist das gefakt?
Es ist echtes Gedaechtnis, aber es funktioniert anders als das menschliche Gedaechtnis. KI-Begleiter speichern Ihre Gespraeche in externen Datenbanken und rufen relevante Informationen ab, wenn Sie chatten. Sie "erinnern" sich nicht im menschlichen Sinne des Bildens persistenter neuronaler Verbindungen. Sie suchen jedes Mal, wenn Sie eine Nachricht senden, nach relevanten vergangenen Gespraechen und lesen sie erneut. Das Erlebnis fuehlt sich aus Sicht des Nutzers wie Gedaechtnis an, aber der Mechanismus ist grundlegend anders.
Wie viel von meinem Gespraechsverlauf speichert ein KI-Begleiter?
Das variiert je nach Plattform. Einige speichern alles unbegrenzt, waehrend andere rollende Fenster implementieren, die Gespraeche aelter als eine bestimmte Zeitspanne verwerfen. Replika zum Beispiel pflegt ein Gespraechstagebuch, das Interaktionen zusammenfasst. Nomi speichert kategorisierte Erinnerungen. Die meisten Plattformen speichern mindestens mehrere Monate Verlauf, auch wenn sie aeltere Gespraeche zusammenfassen oder komprimieren koennen.
Kann ich die Erinnerungen meines KI-Begleiters an mich loeschen?
Die meisten serioesen Plattformen bieten eine Form der Gedaechtnisverwaltung. Replika laesst Sie konkrete Gedaechtniseintraege ueberpruefen und loeschen. Einige Plattformen bieten eine "Reset"-Option, die alle gespeicherten Erinnerungen loescht. Pruefen Sie immer die Datenloeschrichtlinien der Plattform, denn das "Loeschen von Erinnerungen" ueber die Benutzeroberflaeche bedeutet nicht immer, dass die Daten dauerhaft von ihren Servern entfernt werden.
Warum erinnert sich mein KI-Begleiter manchmal an falsche Dinge?
Das passiert wegen eines Phaenomens namens "halluzinierte Erinnerung". Das Abrufsystem findet eine teilweise Uebereinstimmung aus Ihren vergangenen Gespraechen, und das Sprachmodell fuellt Luecken mit erfundenen Details. Es kann auch auftreten, wenn das System zwei getrennte Erinnerungen zu einer vermischt. Wenn das passiert, korrigieren Sie die KI sofort, damit die Korrektur als neue, hoeher priorisierte Erinnerung gespeichert wird.
Ist RAG der einzige Weg, wie KI-Begleiter mit Gedaechtnis umgehen?
Nein, obwohl es der gaengigste Ansatz ist. Einige Plattformen verwenden strukturierte Gedaechtnisspeicher (Schluessel-Wert-Datenbanken mit Nutzerfakten), Gespraechszusammenfassung ohne Vektorsuche oder hybride Ansaetze. Einige experimentelle Systeme erkunden das Fine-Tuning von Modellen auf Nutzerdaten, was echtes gelerntes Gedaechtnis schaffen wuerde, aber das wirft erhebliche Datenschutz- und Sicherheitsbedenken auf.
Wie beeinflussen Kontextfenster die Gedaechtnisqualitaet von KI-Begleitern?
Das Kontextfenster ist die Gesamtmenge an Text, die die KI auf einmal verarbeiten kann. Groessere Kontextfenster erlauben, mehr Erinnerungen neben Ihrem aktuellen Gespraech einzuspeisen, was im Allgemeinen die Abrufqualitaet verbessert. Groessere Fenster bedeuten jedoch auch hoehere Kosten und langsamere Antworten. Die meisten Plattformen optimieren auf eine Balance zwischen Gedaechtnistiefe und Antwortgeschwindigkeit.
Kann ich meinen eigenen KI-Begleiter mit besserem Gedaechtnis als kommerzielle Plattformen bauen?
Ja, und es ist zugaenglicher, als Sie vielleicht denken. Mit Werkzeugen wie ChromaDB, LangChain und Open-Source-LLMs koennen Sie ein Gedaechtnissystem bauen, das mit dem, was kommerzielle Plattformen bieten, mithalten oder es uebertreffen kann. Der Hauptkompromiss besteht darin, dass Sie die Infrastruktur selbst verwalten muessen und nicht die ausgefeilte Benutzeroberflaeche einer Verbraucher-App erhalten.
Was passiert mit den Erinnerungen meines KI-Begleiters, wenn das Unternehmen schliesst?
In den meisten Faellen gehen Ihre Daten verloren. Wenige Plattformen bieten Datenexportfunktionen, und noch weniger garantieren Datenportabilitaet. Das ist ein echtes Risiko, besonders bei kleineren KI-Begleiter-Startups. Ich wuerde empfehlen, alle wichtigen Gespraeche regelmaessig manuell zu exportieren, wenn die Plattform es unterstuetzt.
Wie funktioniert mehrsprachiges Gedaechtnis fuer KI-Begleiter?
Mehrsprachiges Gedaechtnis erfordert Embedding-Modelle, die sinnvolle Vektoren ueber Sprachen hinweg erzeugen koennen. Modelle wie Cohere embed-v4 und mehrsprachige Versionen von BERT bewaeltigen das, indem sie semantisch aehnliche Inhalte aus verschiedenen Sprachen auf nahe beieinander liegende Punkte im Vektorraum abbilden. Das bedeutet, dass eine KI technisch gesehen eine Erinnerung aus einem franzoesischen Gespraech abrufen koennte, wenn Sie auf Englisch chatten, sofern die Themen verwandt sind.
Werden KI-Begleiter jemals ein wirklich permanentes Gedaechtnis haben?
Die Forschung zu kontinuierlichem Lernen und gedaechtnisgestuetzten neuronalen Netzen schreitet voran, aber wir sind wahrscheinlich Jahre von produktionsreifen Implementierungen entfernt. Die Herausforderung ist nicht nur technisch. Es geht auch um Sicherheit. Ein Modell, das seine eigenen Gewichte auf Basis von Nutzergespraechen dauerhaft veraendert, koennte Verzerrungen entwickeln, wichtiges Sicherheitstraining vergessen oder sich unvorhersehbar verhalten. Vorerst bleiben externe Gedaechtnissysteme der sicherste und praktischste Ansatz.
Fazit
Das Gedaechtnis von KI-Begleitern ist eines jener Themen, bei denen die Kluft zwischen Nutzerwahrnehmung und technischer Realitaet enorm ist. Was sich anfuehlt, als ob ein Begleiter sich an Sie "erinnert", ist in Wirklichkeit eine komplexe Orchestrierung von Embedding-Modellen, Vektordatenbanken, Abrufalgorithmen und Kontextfenster-Management. Das Verstaendnis dieser Mechanik macht das Erlebnis nicht weniger bedeutungsvoll. Wenn ueberhaupt, gibt es Ihnen die Werkzeuge, das Erlebnis besser zu machen.
Die Plattformen, die ernsthaft in Gedaechtnisinfrastruktur investieren, werden die naechste Generation von KI-Begleitern definieren. Diejenigen, die Gedaechtnis als Haekchen-Funktion behandeln, werden zurueckfallen. Und wenn Sie die Art Mensch sind, die maximale Kontrolle moechte, war das Bauen eines eigenen Systems nie zugaenglicher.
Ob Sie ein Gelegenheitsnutzer sind, der moechte, dass sich sein KI-Begleiter an seinen Namen erinnert, oder ein Entwickler, der die naechste grosse Begleiter-Plattform baut, gelten dieselben Prinzipien: speichern Sie ueberlegt, rufen Sie clever ab, und versuchen Sie nie, mehr Erinnerungen in das Kontextfenster zu stopfen, als es bewaeltigen kann. Die Technologie wird sich weiter verbessern. Kontextfenster werden groesser. Embedding-Modelle werden klueger. Aber die grundlegende Architektur, externes Gedaechtnis, das in ein zustandsloses Modell eingespeist wird, wird uns noch eine Weile begleiten.
Und wenn Sie neugierig sind, wie diese Architektur in der Praxis aussieht, versuchen Sie, eine zu bauen. Fuenfzig Zeilen Python und eine kostenlose Vektordatenbank sind alles, was es braucht, um hinter den Vorhang zu blicken. Sie koennten ueberrascht sein, wie einfach die Magie wirklich ist.
Bereit, Ihren KI-Influencer zu Erstellen?
Treten Sie 115 Studenten bei, die ComfyUI und KI-Influencer-Marketing in unserem kompletten 51-Lektionen-Kurs meistern.
Verwandte Artikel

KI-Freund-Apps 2026: Der komplette Leitfaden zu maennlichen KI-Begleitern
Entdecken Sie die besten KI-Freund-Apps im Jahr 2026 mit ausfuehrlichen Bewertungen maennlicher KI-Begleiter. Vergleichen Sie Replika, Nomi, Candy AI und spezialisierte Plattformen hinsichtlich Gespraechsqualitaet, Anpassbarkeit und emotionaler Tiefe.

Helfen KI-Begleiter-Apps wirklich gegen Einsamkeit? Was die Forschung zeigt
Eine Untersuchung der Forschung zu der Frage, ob KI-Begleiter-Apps wie Replika gegen Einsamkeit helfen oder sie verschlimmern. Studien, Risiken, Vorteile und eine ehrliche Einschaetzung.

AI-Begleiter-Ethik und gesunde Grenzen: Ein überlegter Ansatz
Navigiere AI-Begleiter-Beziehungen ethisch mit gesunden Grenzen. Richtlinien für verantwortungsvolle Nutzung, Selbstbewusstsein und ausgewogene AI-Interaktion.