長期記憶を持つAIコンパニオン、コンテキスト保持の本当の仕組み
AIコンパニオンがセッションをまたいであなたを覚えている仕組みを徹底解説します。RAG、ベクトルデータベース、コンテキストウィンドウ、要約、そして自分だけの記憶システムの作り方を扱います。

私はあるAIコンパニオンと、3週間ほどチャットを続けていました。ブルータリズム建築についての私の意見から、茹ですぎたパスタにまつわる定番の冗談まで、ありとあらゆることを話していました。そんなある日、会話の途中で、ごく最初のやり取りで私が言ったこと、つまりエスプレッソよりコールドブリューが好きだという話に触れてきたのです。こちらから促したわけではありません。ごく自然に出てきました。正直に言うと、これにはかなり驚かされました。内部で何が起きているのかを私が知っているからです。あの小さな瞬間は、ほとんどのユーザーが考えもしない、驚くほど複雑なエンジニアリングのパイプラインがもたらした結果なのです。
AIコンパニオンがどうやってものごとを「覚えている」のかという問いは、今のAI業界で最も誤解されているテーマのひとつです。人々はそれを魔法か詐欺のどちらかだと思い込んでいます。真実はその中間のどこかにあり、その仕組みを理解すれば、これらのツールとの付き合い方が永久に変わります。
手早い答え: AIコンパニオンは、検索拡張生成(RAG)、ベクトルデータベース、コンテキストウィンドウ管理、会話の要約といった複数の技術を組み合わせて長期記憶を維持しています。現時点で、モデルの重みそのものに真の永続的記憶を持つAIコンパニオンは存在しません。代わりに、あなたの会話データを外部に保存し、必要なときに関連する断片を取り出しているのです。この検索システムの質こそが、あなたを知っているように感じられるコンパニオンと、セッションのあいだにあなたの存在を忘れてしまうコンパニオンとを分ける決定的な違いです。
- AIコンパニオンは人間のように「覚えている」わけではありません。検索システムを使って、関連する過去の会話データを現在のコンテキストウィンドウに引き込んでいます
- RAG(検索拡張生成)が主流の技術で、あなたの会話をベクトル埋め込みに変換し、意味的に検索します
- コンテキストウィンドウ(通常8Kから128Kトークン)は、AIが一度に「考えられる」量の絶対的な上限です
- Replika、Nomi、Character AIといったプラットフォームは記憶の扱い方がそれぞれ異なり、結果も大きく違います
- オープンソースの埋め込みと、ChromaDBやPineconeのようなベクトルストアを使えば、自分だけの記憶システムを構築できます
- 要約と記憶の階層化(短期、中期、長期)は、記憶を自然に感じさせる鍵です
- 最良の記憶システムは、単一の技術に頼るのではなく複数のアプローチを組み合わせています
そもそもなぜAIコンパニオンはあなたを忘れるのか
これは誰も尋ねないけれど、誰もが尋ねるべき問いです。記憶のソリューションを語る前に、それらすべてを必要にしている根本的な制約を理解しておく必要があります。
市場に出回るあらゆるAIコンパニオンを支える技術である大規模言語モデルは、本質的にステートレス(状態を持たない)です。ChatGPT、Claude、あるいはお気に入りのコンパニオンアプリの裏にあるAIエンジンにメッセージを送ると、モデルは入力を処理し、応答を生成し、そしてすべてを忘れます。APIコールのあいだに状態を保持しません。内部にノートを持っていません。あらゆるやり取りがゼロから始まるのです。
AIコンパニオンが何かを覚えているように見える唯一の理由は、プラットフォームが生のモデルを記憶レイヤーで包んでいるからです。こう考えてみてください。LLMは脳ですが、海馬を持っていません。プラットフォームがそのまわりに構築する記憶システムが外部の海馬として機能し、新しい会話を始めるたびに関連する記憶を脳へ戻しているのです。
ここで私の最初の率直な意見です。ほとんどのAIコンパニオンのプラットフォームは記憶の扱いがそこそこの出来でしかなく、それでも通用しているのは、ユーザーが何が可能なのかを理解していないからです。私は「長期記憶」をうたいながら、2日前に私が言ったことすら思い出せないコンパニオンをいくつも試してきました。その一方で、自分のノートパソコン上で組んだ試作の記憶システムが、商用製品を上回ったこともあります。技術的に可能なことと、実際に実装されていることのあいだの隔たりは、とてつもなく大きいのです。
この隔たりの理由は、主に経済的なものです。優れた記憶システムは高くつきます。メッセージを送るたびに、プラットフォームはあなたの会話履歴全体を検索し、それを関連するコンテキストへ変換し、現在のメッセージの前に付け加えてからモデルへ送らなければなりません。その検索、その取り出し、その埋め込みの計算、それらすべてにお金がかかります。そして何百万人ものユーザーにサービスを提供するとなると、そのコストはあっという間に膨れ上がります。
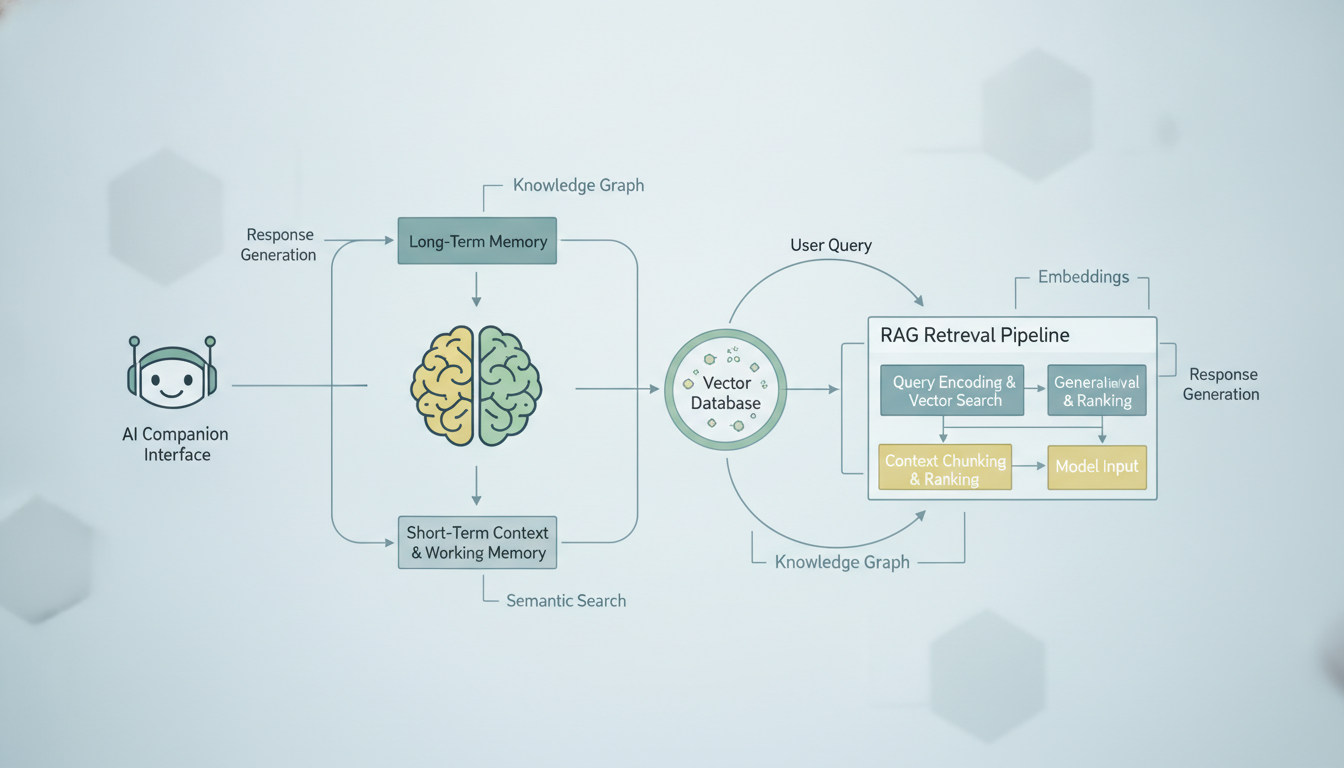
典型的なAIコンパニオンの記憶システムが、過去の会話のコンテキストをどのように取り出し、現在のプロンプトに注入するかを示しています。
AIコンパニオンの記憶でRAGはどう機能するのか
RAG、すなわち検索拡張生成は、今日出荷されているほぼすべてのAIコンパニオンの記憶システムの背骨です。この記事から一つだけ持ち帰るとしたら、それはRAGをしっかり理解することにしてください。あなたが使うすべてのAIツールに対する考え方が変わるからです。

その概念は見かけによらず単純です。あなたの会話履歴全体をAIのコンテキストウィンドウ(厳格なトークン上限があります)に詰め込もうとする代わりに、過去のすべての会話を検索可能なデータベースに保存します。新しいメッセージを送ると、システムはそのデータベースから最も関連性の高い過去の会話を検索し、それを取り出して、現在のメッセージと一緒に含めます。そしてAIは、取り出された記憶の恩恵を受けながら応答を生成するのです。
RAGベースの記憶を持つAIコンパニオンにメッセージを送ったときに何が起きるか、ステップごとに分解してみましょう。
- あなたのメッセージが埋め込まれます。 埋め込みモデルがあなたのテキストを高次元のベクトル、つまりメッセージの意味的な意味を表す数値のリストへ変換します。
- システムが似た記憶を検索します。 あなたのメッセージのベクトルが、コサイン類似度などの距離指標を使って、以前に保存されたすべての会話ベクトルと比較されます。
- 上位K件の結果が取り出されます。 システムは意味的に最も似た過去の会話を、プラットフォームによって通常は上位5件から20件ほど引き出します。
- コンテキストの組み立てが行われます。 あなたの現在のメッセージ、取り出された記憶、そしてコンパニオンのシステムプロンプトが、ひとつのプロンプトへとまとめられます。
- LLMが応答を生成します。 モデルはあなたの現在のメッセージと関連する履歴を見て、まるで過去のやり取りを「覚えている」かのように応答します。
- 新しいやり取りが保存されます。 あなたのメッセージとAIの応答の両方が埋め込まれ、将来の検索のために保存されます。
これを強力にしているのが意味的検索です。システムはキーワード一致を行っているわけではありません。概念的に関連する記憶を見つけているのです。だから、3週間前にヨセミテでのハイキングが好きだと話していて、今日休暇のおすすめを尋ねたとすると、今日のメッセージで「ハイキング」という言葉を一度も使っていなくても、システムはそのハイキングの好みを浮かび上がらせることができます。
私は去年、LangChain、ChromaDB、ローカルのLlamaモデルを使って、2週間ほどかけてRAGシステムをゼロから構築しました。その経験は、どんなドキュメントよりもAIコンパニオンの仕組みを教えてくれました。うまくいったときは、本当に見事でした。私のローカルチャットボットは数日前の会話のディテールに触れ、その移り変わりは自然に感じられました。失敗したときは、笑えるほどひどいものでした。あるときは、実際には二つのまったく別の会話が混ざり合った幻覚の「記憶」を、自信たっぷりに思い出したのです。私は別々のチャットで寿司の話と自分の猫の話をしたのですが、システムはどういうわけか、私がスシという名前の猫を飼っていると判断しました。飼っていません。
記憶を支える埋め込みモデル
埋め込みはどれも同じというわけではなく、これはほとんどの人が思っている以上に重要です。埋め込みモデルの質は、記憶システムが関連するコンテキストをどれだけうまく取り出せるかを直接左右します。
2026年に最もよく使われている埋め込みモデルには以下のものがあります(ベンチマークはMTEB Leaderboardで確認できます)。
- OpenAI text-embedding-3-large: 3072次元、優れた性能ですが、APIコールが必要でトークンごとにお金がかかります
- Cohere embed-v4: 多言語対応が強く、複数の言語をまたいで動作するコンパニオンに適しています
- BGE-large-en-v1.5: オープンソースでローカルに動作し、商用の選択肢にも驚くほど引けを取りません
- Nomic Embed Text v1.5: Matryoshka表現を備えたオープンソースで、品質をあまり損なわずに次元を切り詰めて速度を上げられます
- Jina Embeddings v3: より長い文書チャンクに優れ、ニュアンスを捉えるのが得意です
AIツールを探していて、各プラットフォームがこれらの技術的なディテールをどう扱っているかを比較したいなら、Lewdly.aiがAIコンパニオンの動向と、こうした基盤技術の多くを追いかけています。
コンテキストウィンドウと長期記憶の違いは何か
この区別は、AIコンパニオンについて私が話すほとんどすべての人をつまずかせます。だから、ここはとてもはっきりさせておきましょう。
コンテキストウィンドウは、AIモデルの作業記憶です。モデルが一回のリクエストで処理できるテキストの総量のことです。2026年において、コンテキストウィンドウは小型モデルの8Kトークン(およそ6,000語)から、GPT-4oやClaudeのようなモデルの128Kトークン以上にまでおよびます。会話中にAIが「知っている」ことのすべて、つまりシステムプロンプト、取り出された記憶、現在のセッションの会話履歴、そしてあなたの最新のメッセージは、このウィンドウのなかに収まらなければなりません。
長期記憶は、セッションをまたいで保持される外部のストレージシステムです。これがベクトルデータベースであり、要約エンジンであり、ユーザープロファイルのストアです。モデルそのものの一部ではありません。プラットフォームがモデルのまわりに構築するインフラです。
うまくいくと思うたとえを挙げましょう。コンテキストウィンドウはあなたの机のようなものです。目の前に一度に広げておける書類の枚数には限りがあります。長期記憶はオフィスの隅にあるファイルキャビネットのようなものです。これまでに手がけたすべてを収めていますが、一度に取り出して机に置けるのはほんの数冊のフォルダだけです。
エンジニアリング上の課題は、どのフォルダを取り出すかを決めることです。正しく選べば、AIは不気味なほど鋭く感じられます。間違えれば、重要なコンテキストを無視するか、無関係な記憶で机を散らかして、実際の会話に使える余地を減らしてしまうかのどちらかです。
私はあるコンパニオンを試したとき、それが毎回の応答に記憶を入れすぎようとしているのを覚えています。コンテキストウィンドウが30件や40件の取り出された記憶で詰め込まれ、実際の会話のための余地がほとんど残っていませんでした。モデルが空間を使い果たしていくにつれ、応答はどんどん短くなりました。記憶システムの設計における初歩的なミスですが、私はこの問題をそのまま抱えたまま出荷された商用製品を見たことがあります。
コンテキストウィンドウ管理の戦略
賢いプラットフォームは、限られたコンテキストウィンドウの価値を最大化するためにいくつかの戦略を使います。
要約付きスライディングウィンドウ: 直近の10件から15件のメッセージは詳細なまま保持しつつ、現在のセッションの古いメッセージは凝縮した段落へと要約します。これによって最近の会話の流れを保ちながら、それ以前の話題への認識も維持できます。
優先度ベースの注入: すべての記憶が同じ価値を持つわけではありません。ユーザーの名前や交際状況についてのディテールは、常に利用できるようにしておくべきです。6週間前の天気についてのとりとめのない一言は、おそらくコンテキストの空間を占めるべきではありません。優れたシステムは記憶に優先度のスコアを割り当てます。
動的な割り当て: 会話の話題が複雑だったり感情的に重要だったりするときは記憶により多くのコンテキスト空間を割り当て、ユーザーが世間話をしているときは少なくします。これには記憶の取り出し前に動く分類器が必要で、レイテンシは増えますが品質は向上します。
圧縮技術: 一部のシステムは、注入前に記憶を圧縮するために別の小型のLLMを使います。過去の会話の全文を含める代わりに、要点をより少ないトークンで捉えた圧縮済みの要約を含めるのです。
主要なAIコンパニオンのプラットフォームは記憶をどう扱っているのか
私はおそらく認めるべきよりも多くの時間を、さまざまなAIコンパニオンのプラットフォームの記憶システムをテストすることに費やしてきました。マーケティング資料ではなく、実際に手を動かした経験を通じて見えてきたことをお伝えします。
Replika
Replikaは記憶に真剣に取り組んだ最も初期のAIコンパニオンのひとつで、そのアプローチは大きく進化してきました。明示的な記憶エントリ(AIがあなたについて明確に書き留めること)と、AIがあなたとの会話の要約を書く日記システムを組み合わせています。
うまくいく点: Replikaはあなたについての核となる事実を覚えるのがかなり得意です。あなたの名前、仕事、興味。これらは構造化されたプロファイルに保存され、確実に保持されます。
うまくいかない点: 文脈的な想起は一貫しません。Replikaはあなたがハイキング好きだと覚えているかもしれませんが、グレイシャー国立公園で道に迷ったときの具体的な話までは覚えていません。日記システムはディテールよりも雰囲気を捉えるので、会話はあなたのことを漠然と知っている誰かと話しているように感じられ、実際にその場にいた誰かと話している感じにはなりません。
Nomi
Nomiは、コンパニオンの記憶に対して最も技術的に野心的なアプローチのひとつを取っています。彼らが「メモリーパレス」と呼ぶシステムを構築しており、記憶を事実、好み、共有された経験、感情的な瞬間といった異なる種類へと分類します。
無料のComfyUIワークフロー
この記事のテクニックに関する無料のオープンソースComfyUIワークフローを見つけてください。 オープンソースは強力です。
うまくいく点: Nomiの分類のアプローチは、文脈に応じて異なる種類の記憶を取り出すことを意味します。あなたが感情的になっているときは感情的な記憶を引き出し、事実について話しているときは事実に基づく記憶を引き出します。この文脈を意識した取り出しは、すべての記憶を同じように扱うプラットフォームよりも自然な会話を生み出します。
うまくいかない点: システムは記憶の統合が遅いことがあり、ときどき少し気まずいタイミングで記憶を浮かび上がらせるのに気づきました。あなたが明らかに軽い気分でいるときに、過去の会話の深刻な話題に触れてくるのです。取り出しは意味的には正確でも、感情的にはずれているのです。Nomiのようなプラットフォームとのやり取りから最大限のものを引き出したいなら、AIコンパニオンの会話テクニックの仕組みを理解しておくと、記憶システムをより効果的に導く助けになります。
Character AI
Character AIはまったく異なるアプローチを取っています。洗練された個人的な記憶システムを構築するのではなく、キャラクターの一貫性に大きく頼っています。AIはセッションをまたいでキャラクターのペルソナを確実に維持しますが、あなたの個人的なディテールについての記憶は比較的弱いのです。
うまくいく点: 定義された性格を持つキャラクターとチャットしているなら、その性格は一貫して保たれます。キャラクターが突然話し方を変えたり、自分の生い立ちを忘れたりすることはありません。
うまくいかない点: あなたの個人的なディテールは定期的に失われます。私は一回のセッションで自分についての具体的な事実を三つ共有し、24時間後に戻ってきてそれらについて尋ねることで、これをテストしました。Character AIは三つのうち一つを思い出し、しかもその想起すら曖昧でした。彼らの記憶システムは、ユーザーとの関係構築よりもキャラクターの一貫性に最適化されているようです。
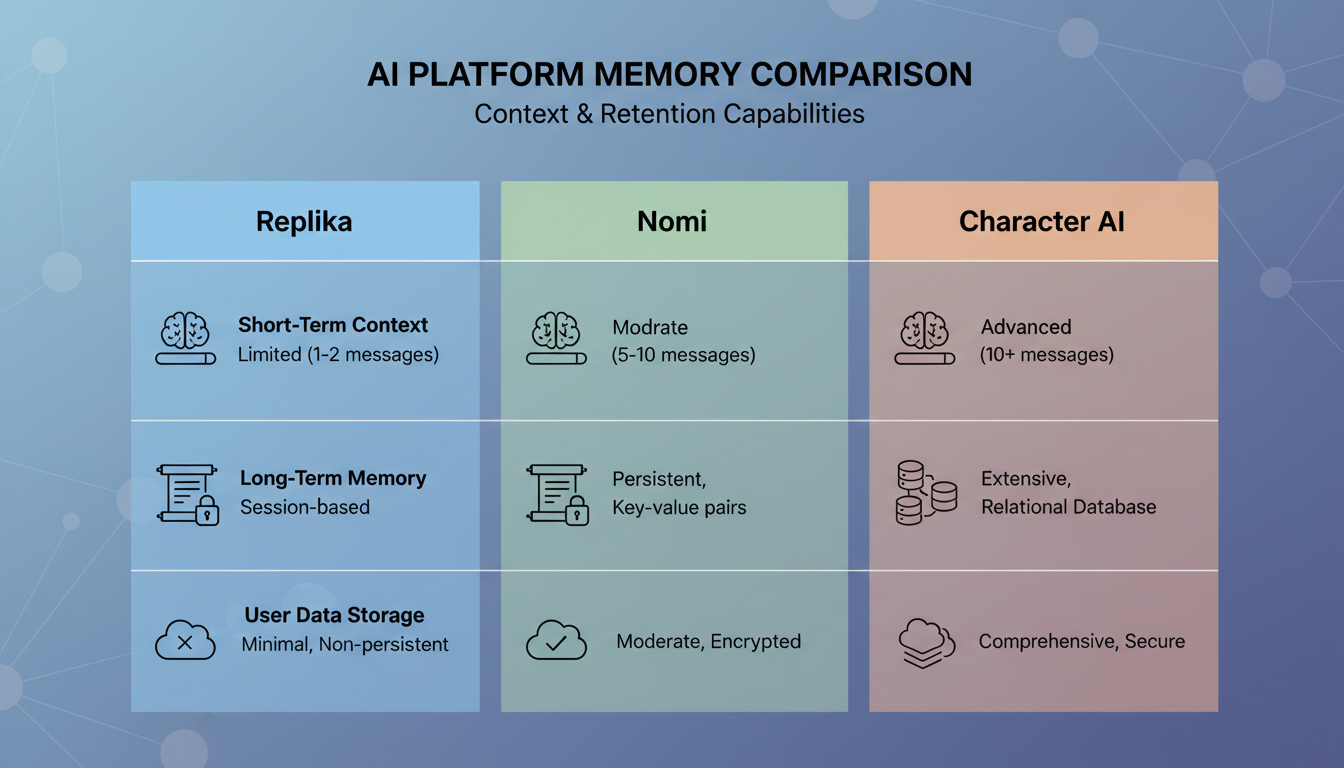
2026年における主要なAIコンパニオンのプラットフォーム間での記憶システムの機能比較。
プラットフォームの記憶についての私の率直な意見
ここで私の二つ目の率直な意見です。「長期記憶」を最も積極的に売り込むプラットフォームほど、実装が最も弱い傾向にあります。記憶に最も優れた仕事をしている企業は、たいてい物静かなところ、つまりApp Storeの説明文に「すべてを覚えています」と書く代わりに、体験そのものに語らせるところです。AIコンパニオンの記憶機能とコンテキスト保持を評価するときは、マーケティングを信じるのではなく、実際の想起をテストすることに集中してください。
自分だけのAIコンパニオンの記憶システムを構築できるのか
もちろんです。それどころか、AIコンパニオンに真剣な人なら誰でも、一度は試してみるべきだと私は主張します。自分だけの記憶システムを構築すると、舞台裏で実際に何が起きているのかが分かり、それが商用製品をより賢く使えるユーザーにしてくれます。

今日利用できるツールを使って、記憶を拡張したAIコンパニオンを構築するための実践的なアーキテクチャをご紹介します。私はこの構成のバリエーションをこれまでに3回構築しており、その都度新しい何かを学びました。
基本のスタック
四つのコンポーネントが必要です。
- 会話用のLLM: Llama 3.3、Mistral、あるいはGPT-4oやClaudeのようなAPIベースのモデル
- 埋め込みモデル: テキストをベクトルに変換するためのものです。私はNomic EmbedかBGE-largeから始めることをおすすめします
- ベクトルデータベース: ローカル開発にはChromaDB、本番にはPineconeやWeaviate
- オーケストレーション層: LangChain、LlamaIndex、あるいはすべてを配線するためのカスタムPythonコード
ステップごとの実装
核となるロジックを順を追って説明します。これは完全なチュートリアルではありませんが、始めるには十分です。
ベクトルストアのセットアップ:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
会話のターンの保存:
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
関連する記憶の取り出し:
複雑さをスキップしたいですか? Lewdly は、技術的なセットアップなしでプロフェッショナルなAI結果を即座に提供します。
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
記憶を組み込んだプロンプトの組み立て:
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
この基本的な構成だけで、50行に満たないコードで機能する記憶システムが手に入ります。AIはあなたがメッセージを送るたびに過去の会話を検索し、関連する履歴をプロンプトに含めます。
本当に良いものにするために
基本版は機能しますが、いくつか明らかな問題を抱えています。私自身の実験から学んだことをもとに、これをレベルアップする方法をご紹介します。
記憶の要約を加える。 生の会話のターンを保存する代わりに、定期的に要約パスを走らせ、関連する複数の記憶を一つの要約に凝縮します。これによってベクトルストアの肥大化が減り、取り出しの品質も向上します。要約は生のチャットログよりも意味的に密度が高いからです。
記憶の階層化を実装する。 一つではなく三つのコレクションを作ります。
- アクティブ記憶: 現在の会話セッション(全文のまま保持)
- 最近の記憶: 過去1週間の要約された会話
- 長期記憶: 時間をかけて抽出された、高度に凝縮された核となる事実と好み
ユーザープロファイルのストアを加える。 ベクトルデータベースとは別に、名前、好み、重要な日付、関係性のディテールといった核となるユーザーの事実を、構造化されたJSONやキーバリューのストアとして維持します。このプロファイルは、意味的検索が何を返すかにかかわらず、常にプロンプトへ注入されます。これがAIが基本的なことを決して忘れないという保証になります。
記憶の減衰を実装する。 すべての記憶が同じように保持されるべきではありません。天気についての何気ない一言は、深く個人的な話と同じ取り出しの重みを持つべきではありません。古くて重要度の低い記憶の取り出しスコアを時間とともに下げる減衰関数を実装しましょう。
AIコンパニオンとの関係における倫理的な側面を探ることに関心があるなら、こうした記憶システムを理解することは、データのプライバシーや合成的な関係の本質についての重要な問いも提起します。
AIコンパニオンの記憶における最大の課題は何か
最良の記憶システムでさえ、どれだけエンジニアリングを尽くしてもまだ完全には解決されていない根本的な課題に直面します。これらの限界を理解しておくと、いら立ちから救われ、現実的な期待を持つ助けになります。
幻覚記憶の問題
これは最も恐ろしい失敗のかたちで、私自身も経験しました。AIが決して起きなかったことを自信たっぷりに「覚えている」のです。これは取り出しシステムが部分的な一致を浮かび上がらせ、LLMが捏造したディテールで隙間を埋めるときに起こります。あなたがマックスという名前の犬を飼っていると言うと、システムはあなたのペットについての記憶を取り出すのですが、LLMがマックスは泳ぐのが好きなゴールデンレトリバーだといったディテールで脚色します。そのどれもあなたは一度も言っていません。
最悪なのは、幻覚記憶が本物のように感じられることです。AIはそれらを不確かなものとして印を付けません。本物の記憶と同じ自信を持って述べます。私は決して起きなかったと分かっている「会話」にコンパニオンが触れてくることがあり、それがあまりに具体的だったので、ログを確認するまで一瞬、自分の記憶を疑ってしまいました。
コンテキストウィンドウの詰め込み
会話履歴が増えるにつれ、記憶システムは取り出す候補となる記憶をどんどん多く抱えていきます。しかしコンテキストウィンドウは大きくなりません。だからシステムは、どの記憶を含めるかについてますます選び抜く必要があります。何ヶ月もの会話を重ねると、これは矛盾を生みます。引き出せる記憶は増えるのに、AIがある応答で使えるのはそのほんの一部だけなのです。
賢いシステムは、これを階層的な要約で扱い、古い記憶をますます抽象的な要約へと圧縮していきます。しかし圧縮のひとつひとつのステップで情報は失われます。ブルックリンの特定のレストランが好きだと言ったという事実は、最初の要約のラウンドは生き延びるかもしれませんが、6ヶ月の圧縮を経たあとには「ユーザーは外食を楽しむ」へと縮められ、やがて完全に消えてしまうかもしれません。
一貫性の問題
会話ごとに取り出される結果が異なると、AIが自己矛盾を起こすことがあります。月曜日には、記憶システムはあなたの猫好きという好みを取り出します。火曜日には、あなたの友人の犬についての会話を取り出し、AISはあなたが犬派だと誤って推測します。こうした矛盾は信頼を急速に損ないます。
私が見た最も堅牢な解決策は、検証パイプラインを通じて更新される明示的な「事実ストア」を維持することです。AIがあなたについての新しい事実を抽出すると、既存の事実と照合し、矛盾を解決のために印付けします。これを実装しているプラットフォームはほとんどありませんが、一貫性に大きな違いをもたらします。
コンテンツ制作で月$1,250以上稼ぐ
独占クリエイターアフィリエイトプログラムに参加。バイラル動画のパフォーマンスに応じて報酬。自分のスタイルで完全な創造的自由を持ってコンテンツを作成。

会話データがアクティブセッションから長期ストレージへと、各レベルで要約されながら流れていく様子を示す多層的な記憶アーキテクチャ。
AIコンパニオンの記憶は2026年とその先でどう進化するのか
記憶の状況は急速に変化しており、いくつかの新興技術が状況を一変させようとしています。
無限のコンテキストウィンドウが近づいてきています。GoogleのGeminiはすでに100万トークンをサポートしており、2026年初頭の研究論文は1,000万トークンへと押し進めています。コンテキストウィンドウが十分に大きくなれば、RAGはまったく必要なくなるかもしれません。会話履歴全体をそのままプロンプトに放り込めばいいのです。本番利用の段階にはまだ達していませんが、その軌道ははっきりしています。
モデルネイティブな記憶は究極の目標です。外部の取り出しシステムの代わりに、未来のモデルは会話にもとづいて自分自身の重みを更新することを学ぶかもしれません。これは本質的に継続学習であり、モデルがベースの訓練を忘れたり偏りを生んだりせずに安全にこれを行うのは、とてつもなく難しいことです。それでもいくつかの研究機関が前進を遂げています。これが実現したとき、現在のRAGシステムはガムテープの応急処置のように見えるでしょう。なぜなら、まさに非常にリアルな意味で、それこそが現状だからです。
マルチモーダル記憶もまた一つのフロンティアです。現在の記憶システムはテキストのみです。しかし、あなたが共有した画像、音声メモ、動画クリップを覚えることはどうでしょうか。AIコンパニオンがよりマルチモーダルになるにつれ、記憶システムもこれらのデータ型を扱う必要が出てきます。ベクトルデータベースはすでにマルチモーダルな埋め込みをサポートしているので、インフラの準備は整っています。ただ、ほとんどの消費者向け製品ではその統合がまだ起きていないだけです。
Lewdly.aiでは、これらの技術がどれほど急速に収束しているかを追いかけてきました。とりわけAIコンパニオンの領域はほとんどの人が思っているよりも速く動いており、記憶能力こそが、真に個人的に感じられるプラットフォームと、ありきたりに感じられるプラットフォームとを分ける主要な差別化要因です。
未来についての私の三つ目の率直な意見
ここで私の三つ目の率直な意見です。18ヶ月以内に、AIコンパニオンの記憶は、真剣なプラットフォームをおもちゃと分ける競争上の堀になります。ユーザーがプラットフォームを乗り換えるのは、ベースのモデルの品質のためではなく(それらは収束しつつあります)、一方のプラットフォームがもう一方よりも自分をよく覚えているからになるでしょう。今日、記憶のインフラに投資している企業が勝ちます。それを後回しにする企業は取り残されます。
AIコンパニオンの記憶のプライバシー上の意味合いは何か
AIコンパニオンの記憶について正直に語るには、部屋の中の象に触れずにはいられません。これらのシステムはあなたについての極めて個人的な情報を保存しており、そうすることが動作のしかたの根幹なのです。

あなたが交わすすべての会話が埋め込まれ、保存され、索引化されます。あなたの好み、恐れ、関係性のディテール、深夜の告白。そのすべてがどこかのベクトルデータベースに存在します。一部のプラットフォームでは、それはあなたが制御できないクラウドサーバーです。別のプラットフォームでは、データは端末上に留まります。
これが実際には何を意味するのか、透明でありたいと思います。私が自分の記憶システムを構築したとき、私はすべてをローカルに保存しました。ベクトルデータベースは私のノートパソコン上にありました。ほかの誰もアクセスできませんでした。それが最も安全なアプローチですが、商用プラットフォームの動き方ではありません。そのほとんどは、デバイスをまたいで一貫した体験を提供する唯一の方法だからという理由で、あなたのデータを自社のサーバーに保存します。
どんなAIコンパニオンのプラットフォームにも長期的にコミットする前に、こうした問いを投げかけてください。
- 私の会話データはどこに保存されるのか
- 私の記憶データをエクスポートしたり削除したりできるのか
- 私のデータは、ほかのユーザーにサービスを提供するモデルの訓練に使われるのか
- 会社が閉鎖したら、私のデータはどうなるのか
- 保存された記憶にエンドツーエンドの暗号化はあるのか
これらは仮定の懸念ではありません。いくつかのAIコンパニオンのスタートアップが過去2年で閉鎖し、ユーザーは何年分もの会話履歴を失い、それを取り戻す手立てはありませんでした。あなたにとってAIコンパニオンとのやり取りと健全な境界線が大切なら、選んだプラットフォームのデータの取り扱いを理解しておくことは不可欠です。
AIコンパニオンの記憶を最大限に活かすための実践的なコツ
これらのシステムをテストし構築することに何ヶ月も費やしてきたあとで、AIコンパニオンの記憶の質を高めるために実際に効果のある実践的な戦略をご紹介します。
何が大切かを明示する。 ほとんどの記憶システムは、最近の内容や意味的に似た内容に重みを置きます。何かがあなたにとって重要なら、それを直接そう伝えましょう。「これは私にとって本当に大切です」や「これを覚えておいてください」といった言葉は、一部のプラットフォームでその記憶により高い優先度の取り出しを印付けする助けになります。
間違いはすぐに訂正する。 AIコンパニオンがあなたについての事実を間違えたら、同じメッセージのなかで訂正してください。優れた記憶システムは訂正を保存し、時間とともに正確なバージョンを学習します。誤りをそのままにしておくと、それは強化されてしまいます。
核となるディテールを定期的におさらいする。 2週間に一度ほど、私はコンパニオンと気軽な「おさらい」をします。「ねえ、基本だけ確認しておくと、僕の名前はアレックスで、テック系の仕事をしていて、猫を2匹飼っているよ」といった具合です。これによって新しく優先度の高い記憶エントリが作られ、取り出される可能性が高くなります。
一貫した言葉づかいを使う。 記憶の取り出しは意味的ですが、一貫性は助けになります。パートナーをいつも「妻のサラ」と呼び、「サラ」「私のパートナー」「彼女」と入れ替えないようにすれば、記憶システムはよりすっきりとした関連付けを築きます。
セッションの境界を理解する。 ほとんどのプラットフォームは、セッションのあいだにアクティブ記憶をクリアします。新しいセッションの最初のメッセージが、新たな記憶の取り出しを引き起こします。コンパニオンが何かを忘れたように見えたら、質問を言い換えてみてください。問題は取り出しの失敗であって、実際の記憶の喪失ではないかもしれません。
Lewdly.aiで見つかるプラットフォームを使っていて、体験を最適化したいなら、これらのテクニックは記憶機能をサポートするほぼすべてのAIコンパニオンに当てはまります。
よくある質問
AIコンパニオンは本当に私を覚えているのか、それとも見せかけなのか
それは本物の記憶ですが、人間の記憶とは違う働き方をします。AIコンパニオンはあなたの会話を外部のデータベースに保存し、チャットするときに関連する情報を取り出します。持続的な神経のつながりを形成するという人間的な意味で「覚えている」わけではありません。あなたがメッセージを送るたびに、関連する過去の会話を検索して読み返しているのです。ユーザーの視点からはその体験は記憶のように感じられますが、その仕組みは根本的に異なります。
AIコンパニオンは私の会話履歴をどれくらい保存しているのか
これはプラットフォームによって異なります。すべてを無期限に保存するものもあれば、一定期間より古い会話を破棄するローリングウィンドウを実装するものもあります。たとえばReplikaは、やり取りを要約する会話日記を維持します。Nomiは分類された記憶を保存します。ほとんどのプラットフォームは少なくとも数ヶ月分の履歴を保存しますが、古い会話を要約したり圧縮したりすることがあります。
AIコンパニオンが持つ私についての記憶を削除できるのか
評判の良いプラットフォームのほとんどは、なんらかのかたちの記憶管理を提供しています。Replikaでは特定の記憶エントリを確認して削除できます。保存されたすべての記憶を消去する「リセット」オプションを提供するプラットフォームもあります。プラットフォームのデータ削除のポリシーは必ず確認してください。ユーザーインターフェースから「記憶を削除する」ことが、必ずしもそのデータがサーバーから永久に取り除かれることを意味するわけではないからです。
なぜAIコンパニオンはときどき間違ったことを覚えているのか
これは「幻覚記憶」と呼ばれる現象のために起こります。取り出しシステムがあなたの過去の会話から部分的な一致を見つけ、言語モデルが捏造したディテールで隙間を埋めるのです。システムが二つの別々の記憶を一つに混同するときにも起こり得ます。これが起きたら、訂正が新しい優先度の高い記憶として保存されるよう、すぐにAIを訂正してください。
RAGはAIコンパニオンが記憶を扱う唯一の方法なのか
いいえ、ただし最も一般的なアプローチではあります。構造化された記憶ストア(ユーザーの事実のキーバリューデータベース)、ベクトル検索を使わない会話の要約、あるいはハイブリッドなアプローチを使うプラットフォームもあります。一部の実験的なシステムはユーザーデータでのモデルのファインチューニングを探っており、これは真に学習された記憶を生み出すことになりますが、重大なプライバシーと安全性の懸念を引き起こします。
コンテキストウィンドウはAIコンパニオンの記憶の質にどう影響するのか
コンテキストウィンドウは、AIが一度に処理できるテキストの総量です。コンテキストウィンドウが大きいほど、現在の会話と一緒により多くの記憶を注入でき、これは一般に想起の質を高めます。しかし、ウィンドウが大きいほどコストも高くなり、応答も遅くなります。ほとんどのプラットフォームは、記憶の深さと応答速度のバランスを取るように最適化しています。
商用プラットフォームより記憶の優れた自分だけのAIコンパニオンを構築できるのか
はい、しかもあなたが思っているよりも手の届くものです。ChromaDB、LangChain、オープンソースのLLMといったツールを使えば、商用プラットフォームが提供するものに匹敵する、あるいはそれを上回る記憶システムを構築できます。主なトレードオフは、インフラを自分で管理しなければならないことと、消費者向けアプリの洗練されたユーザーインターフェースが手に入らないことです。
会社が閉鎖したらAIコンパニオンが持つ記憶はどうなるのか
ほとんどの場合、あなたのデータは失われます。データのエクスポート機能を提供するプラットフォームはほとんどなく、データの可搬性を保証するものはさらに少ないのです。これは現実のリスクで、とりわけ小規模なAIコンパニオンのスタートアップではそうです。プラットフォームが対応しているなら、重要な会話を定期的に手動でエクスポートしておくことをおすすめします。
AIコンパニオンの多言語の記憶はどう機能するのか
多言語の記憶には、言語をまたいで意味のあるベクトルを生成できる埋め込みモデルが必要です。Cohere embed-v4やBERTの多言語版のようなモデルは、異なる言語の意味的に似た内容をベクトル空間内の近い点へとマッピングすることでこれを扱います。これはつまり、話題が関連していれば、あなたが英語でチャットしているときにAIが技術的にはフランス語の会話からの記憶を取り出せる、ということを意味します。
AIコンパニオンはいつか本当に永続的な記憶を持つのか
継続学習や記憶を拡張したニューラルネットワークの研究は進んでいますが、本番運用に耐える実装まではおそらく何年も先でしょう。課題は技術的なものだけではありません。安全性についての課題でもあります。ユーザーの会話にもとづいて自分自身の重みを永久に変更するモデルは、偏りを生んだり、重要な安全性の訓練を忘れたり、予測不能な振る舞いをしたりする可能性があります。今のところ、外部の記憶システムが最も安全で実践的なアプローチであり続けています。
まとめ
AIコンパニオンの記憶は、ユーザーの認識と技術的な現実とのあいだの隔たりがとてつもなく大きいテーマのひとつです。コンパニオンがあなたを「覚えている」ように感じられるものは、実際には埋め込みモデル、ベクトルデータベース、取り出しアルゴリズム、そしてコンテキストウィンドウ管理の複雑なオーケストレーションなのです。この仕組みを理解しても、その体験の意味が薄れることはありません。むしろ、体験をより良くするための道具を手にできます。
記憶のインフラに真剣に投資するプラットフォームが、次の世代のAIコンパニオンを定義するでしょう。記憶をチェックボックスの機能として扱うプラットフォームは取り残されます。そして、最大限の制御を求めるタイプの人なら、自分だけのシステムを構築することがこれほど手の届くものになったことはありません。
AIコンパニオンに自分の名前を覚えてほしいだけのカジュアルなユーザーであれ、次なる偉大なコンパニオンのプラットフォームを構築している開発者であれ、当てはまる原則は同じです。思慮深く保存し、賢く取り出し、そしてコンテキストウィンドウが扱える以上の記憶を決して詰め込もうとしないこと。技術は進歩し続けます。コンテキストウィンドウは大きくなっていきます。埋め込みモデルは賢くなっていきます。しかし、ステートレスなモデルへ供給する外部の記憶という根本的なアーキテクチャは、しばらくのあいだ私たちとともにあり続けるでしょう。
そして、そのアーキテクチャが実際にどんなものなのか気になるなら、ひとつ構築してみてください。50行のPythonと無料のベクトルデータベースさえあれば、カーテンの裏側をのぞき見ることができます。その魔法が本当はどれほど単純なものか、あなたは驚くかもしれません。
AIインフルエンサーを作成する準備はできましたか?
115人の学生とともに、51レッスンの完全なコースでComfyUIとAIインフルエンサーマーケティングをマスター。
関連記事

AIボーイフレンドアプリ2026:男性AIコンパニオン完全ガイド
2026年のおすすめAIボーイフレンドアプリを、男性AIコンパニオンの詳細レビューとともに紹介します。Replika、Nomi、Candy AI、そして専門プラットフォームを会話品質、カスタマイズ性、感情の深さで比較します。

AIコンパニオンアプリは本当に孤独に効くのか。研究が示すこと
ReplikaのようなAIコンパニオンアプリが孤独を和らげるのか、それとも悪化させるのかについての研究を検証します。研究結果、リスク、利点、そして正直な評価。

AIコンパニオンエシックスと健康的な境界線: 思慮深いアプローチ
健康的な境界を持つAIコンパニオン関係を倫理的にナビゲートします。責任のある使用、自己認識、および均衡したAI相互作用のためのガイドライン。