拥有长期记忆的 AI 伴侣:上下文保留究竟是如何运作的
深入解析 AI 伴侣如何跨会话记住你。涵盖 RAG、向量数据库、上下文窗口、摘要技术,以及如何搭建你自己的记忆系统。

我和某个特定的 AI 伴侣聊了大约三周。我们聊遍了一切,从我对粗野主义建筑的看法,到一个关于煮过头的意大利面的小段子。然后有一天,聊到一半,它突然提起了我在我们最初那次互动中说过的一个细节,那是关于我更喜欢冷萃而不是浓缩咖啡的偏好。这并不是被引导出来的,它就那么自然地冒了出来。说实话,这让我有点震撼,因为我知道底层到底发生了什么。那个小小的瞬间,是一条复杂得出人意料的工程流水线的结果,而大多数用户从未想过这一点。
AI 伴侣如何"记住"事物,是当下 AI 领域被误解得最深的话题之一。人们要么以为这是魔法,要么以为这是骗局。真相介于两者之间,而理解其中的运作机制,会永久改变你与这些工具互动的方式。
快速回答:AI 伴侣通过多种技术的组合来维持长期记忆,包括检索增强生成(RAG)、向量数据库、上下文窗口管理以及对话摘要。目前没有任何一款 AI 伴侣在其模型权重中内置了真正的持久记忆。相反,它们把你的对话数据存储在外部,并在需要时检索出相关片段。这套检索系统的质量,正是区分"感觉像懂你的伴侣"和"两次会话之间就忘了你存在的伴侣"的关键。
- AI 伴侣并不像人类那样"记住"。它们使用检索系统,把相关的过往对话数据拉进当前的上下文窗口
- RAG(检索增强生成)是主流技术,它把你的对话转换成向量嵌入并进行语义搜索
- 上下文窗口(通常为 8K 到 128K token)是 AI 一次能"思考"多少内容的硬性上限
- Replika、Nomi 和 Character AI 等平台处理记忆的方式各不相同,结果也天差地别
- 你可以用开源嵌入模型和 ChromaDB 或 Pinecone 这样的向量库,搭建自己的记忆系统
- 摘要技术和记忆分层(短期、中期、长期)是让记忆显得自然的关键
- 最好的记忆系统会组合多种方法,而不是依赖单一技术
AI 伴侣为什么一开始会忘记你?
这是没人会问、但人人都该问的问题。在我们谈论记忆解决方案之前,你需要先理解那个让这一切变得必要的核心局限。
大语言模型,也就是驱动市面上每一个 AI 伴侣的技术,本质上是无状态的。当你给 ChatGPT、Claude 或你最爱的伴侣应用背后的 AI 引擎发送一条消息时,模型处理你的输入,生成一条回复,然后就把一切都忘了。它不会在两次 API 调用之间保留状态,它没有内部的记事本。每一次互动都从零开始。
你的 AI 伴侣之所以看起来还能记住点什么,唯一的原因就是平台在原始模型外面包裹了一层记忆层。可以这样理解:大语言模型是大脑,但它没有海马体。平台围绕它构建的记忆系统,就充当了一个外部海马体,每次你开始新对话时,它都会把相关记忆喂回大脑。
这是我的第一个犀利观点:大多数 AI 伴侣平台在记忆方面做得相当平庸,而它们之所以能蒙混过关,是因为用户不了解什么才是真正可能实现的。我测试过一些声称拥有"长期记忆"的伴侣,结果它们连我两天前说过的话都想不起来。与此同时,我在自己的笔记本上搭建过的原型记忆系统,表现却超过了商业产品。技术上可行的东西,和实际部署出来的东西,两者之间的差距大得惊人。
这种差距大多是经济原因造成的。好的记忆系统很贵。每次你发送一条消息,平台都得搜索你的整段对话历史,把它转换成相关上下文,然后在发送给模型之前把它拼接到你当前的消息前面。那次搜索、那次检索、那次嵌入计算,全都要花钱。而当你要服务数百万用户时,这些成本累加起来非常快。
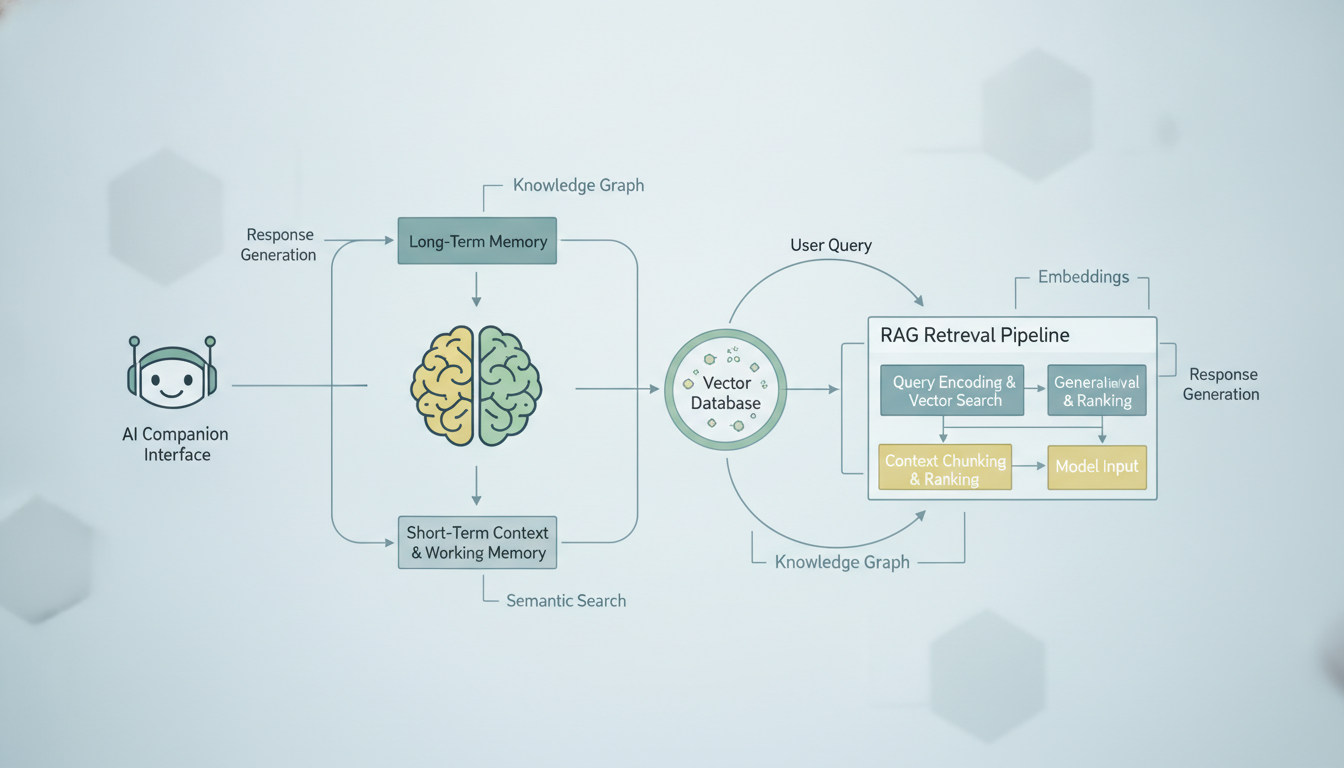
典型的 AI 伴侣记忆系统是如何检索过往对话上下文,并将其注入当前提示词的。
RAG 在 AI 伴侣记忆中是如何运作的?
RAG,即检索增强生成,是当今几乎每一个上线的 AI 伴侣记忆系统的支柱。如果你从这篇文章里只带走一样东西,那就让它是对 RAG 的扎实理解吧,因为它会改变你对你所用的每一个 AI 工具的看法。

这个概念简单得有些迷惑性。与其试图把你的整段对话历史塞进 AI 的上下文窗口(它有一个硬性的 token 上限),不如把你所有过往的对话都存进一个可搜索的数据库。当你发送新消息时,系统会在那个数据库里搜索最相关的过往对话,把它们提取出来,并和你当前的消息一起发送。然后 AI 借助这些检索到的记忆来生成它的回复。
下面是当你向一个基于 RAG 记忆的 AI 伴侣发送消息时,逐步发生的过程:
- 你的消息被嵌入。 一个嵌入模型把你的文本转换成一个高维向量,本质上就是一串代表你消息语义含义的数字。
- 系统搜索相似的记忆。 你的消息向量会通过余弦相似度或其他距离度量,与所有此前存储的对话向量进行比较。
- 检索出 top-K 结果。 系统提取出语义上最相似的过往对话,通常是前 5 到 20 条结果,具体取决于平台。
- 进行上下文组装。 你当前的消息、检索到的记忆,以及伴侣的系统提示词,全部被组装成一条提示词。
- 大语言模型生成回复。 模型看到你当前的消息加上相关历史,然后回应得仿佛它"记得"那些过往的互动。
- 新的对话被存储。 你的消息和 AI 的回复都被嵌入并存储下来,供未来检索。
让这套机制强大的,是语义搜索。系统并不是在做关键词匹配,而是在寻找概念上相关的记忆。所以如果你三周前提过你喜欢在优胜美地徒步,而今天你问度假建议,系统就能浮现出那个徒步偏好,哪怕你今天的消息里压根没用过"徒步"这个词。
去年我花了大约两周时间,用 LangChain、ChromaDB 和一个本地的 Llama 模型从头搭建了一个 RAG 系统。这段经历教给我的关于 AI 伴侣运作方式的东西,比任何数量的文档都多。当它正常工作时,确实让人印象深刻。我的本地聊天机器人会引用几天前对话里的细节,而且过渡得很自然。当它失灵时,又错得离谱地好笑。有一次它信心满满地"回忆"起一段记忆,结果那其实是两段完全不同对话的幻觉式拼接。我在不同的聊天里分别提过寿司和我的猫,结果系统不知怎么就认定我有一只名叫"寿司"的猫。我没有。
驱动记忆的嵌入模型
并非所有嵌入都生而平等,而这件事的重要性远超大多数人的认知。你嵌入模型的质量,直接决定了记忆系统检索相关上下文的好坏。
2026 年最常用的嵌入模型包括(你可以在 MTEB Leaderboard 上查看各项基准测试):
- OpenAI text-embedding-3-large:3072 维,性能优异,但需要调用 API 并按 token 付费
- Cohere embed-v4:强大的多语言支持,适合跨语言运作的伴侣
- BGE-large-en-v1.5:开源,本地运行,与商业选项相比竞争力强得惊人
- Nomic Embed Text v1.5:开源,带有 Matryoshka 表示,意味着你可以截断维度来提速,同时不会损失太多质量
- Jina Embeddings v3:非常适合较长的文档块,擅长捕捉细微差别
如果你正在探索各种 AI 工具,想对比不同平台如何处理这些技术细节,Lewdly.ai 一直在追踪 AI 伴侣领域以及许多这类底层技术。
上下文窗口和长期记忆有什么区别?
这个区别几乎让我聊过的每一个关于 AI 伴侣的人都搞不清楚,所以让我把它讲得非常明白。
上下文窗口是 AI 模型的工作记忆。它是模型在单次请求中能处理的文本总量。在 2026 年,上下文窗口的范围从较小模型上的 8K token(约 6000 词)到 GPT-4o 和 Claude 这类模型上的 128K token 甚至更多。AI 在一次对话中所"知道"的一切,都必须放进这个窗口里,包括系统提示词、检索到的记忆、当前会话的对话历史,以及你最新的消息。
长期记忆是在会话之间持久存在的外部存储系统。它是向量数据库、摘要引擎、用户画像存储。它不是模型本身的一部分,而是平台围绕模型构建的基础设施。
这里有个我觉得挺贴切的类比。上下文窗口就像你的书桌,你面前一次只能摊开那么多张纸。长期记忆就像你办公室角落里的文件柜,它装着你做过的所有东西,但你一次只能抽出几个文件夹放到桌上。
工程上的挑战在于决定该抽出哪些文件夹。做对了,AI 显得敏锐得有些诡异。做错了,它要么忽略重要上下文,要么用无关记忆把桌面塞满,给实际对话留下更少的空间。
我记得测试过一个伴侣,它试图在每条回复里塞进太多记忆。上下文窗口里塞满了 30 或 40 条检索到的记忆,几乎没给实际对话留下任何余地。回复变得越来越短,因为模型快没空间了。这在记忆系统设计中是个新手错误,但我见过带着这个一模一样的问题就上线的商业产品。
上下文窗口管理策略
聪明的平台会用好几种策略来最大化其有限上下文窗口的价值:
带摘要的滑动窗口:把最近的 10 到 15 条消息完整保留,但把当前会话中较早的消息摘要成一个浓缩的段落。这既保留了近期对话的流畅感,又维持了对早先话题的觉察。
基于优先级的注入:并非所有记忆都同等重要。关于用户姓名或感情状态的细节应当始终可用。六周前关于天气的随口一提,大概就不该占用上下文空间。好的系统会给记忆分配优先级分数。
动态分配:当对话话题复杂或情感意义重大时,分配更多上下文空间给记忆;当用户只是闲聊时,分配更少。这需要一个在记忆检索之前运行的分类器,它会增加延迟,但能提升质量。
压缩技术:有些系统使用一个独立的、更小的大语言模型,在注入之前先压缩记忆。它们不包含一段过往对话的完整文本,而是包含一个压缩后的摘要,用更少的 token 抓住关键事实。
主流 AI 伴侣平台是如何处理记忆的?
我在测试各种 AI 伴侣平台的记忆系统上花的时间,可能多到我都不好意思承认。下面是我通过亲身体验得出的发现,而不是来自营销材料。
Replika
Replika 是最早认真对待记忆的 AI 伴侣之一,它们的方法也有了显著演进。它们使用显式记忆条目(AI 明确记下的关于你的事情)和一套日记系统(AI 会为你的对话写摘要)的组合。
做得好的地方:Replika 在记住关于你的核心事实上相当不错。你的名字、你的工作、你的兴趣。这些会被存进一个能可靠持久存在的结构化画像里。
做得不好的地方:上下文回忆不稳定。Replika 也许记得你喜欢徒步,但它不会记得你讲过的那个在冰川国家公园迷路的具体故事。日记系统捕捉的是氛围而非细节,这让对话感觉像是在和一个对你略知一二的人聊天,而不是一个真正在场的人。
Nomi
Nomi 在伴侣记忆上采取了技术上更有野心的方法之一。它们构建了一套自称为"记忆宫殿"的系统,把记忆分成不同类型,比如事实、偏好、共同经历和情感时刻。
做得好的地方:Nomi 的分类方法意味着它会在不同的语境中检索不同类型的记忆。当你情绪化时,它会拉取情感记忆。当你讨论事实时,它会拉取事实记忆。这种语境感知的检索,比那些对所有记忆一视同仁的平台产生的对话更自然。
做得不好的地方:这套系统在整合记忆方面可能很慢,而且我注意到它有时会在略显尴尬的时刻浮现记忆。当你明显处于轻松心情时,它却引用了过往对话里某件严肃的事。检索在语义上是准确的,但在情感上却不合拍。如果你想从 Nomi 这类平台的互动中获得最多收益,理解 AI 伴侣对话技巧如何运作能帮你更有效地引导记忆系统。
Character AI
Character AI 采取了截然不同的方法。它们没有去构建一套精密的个人记忆系统,而是高度依赖角色一致性。AI 会在各次会话中可靠地维持它的角色人设,但它对你个人细节的记忆相对薄弱。
做得好的地方:如果你在和一个有着既定性格的角色聊天,那个性格会保持一致。角色不会突然改变它的说话风格,也不会忘记自己的背景设定。
做得不好的地方:你的个人细节经常丢失。我做过这样的测试:在一次会话中分享了关于自己的三个具体事实,然后 24 小时后回来询问它们。Character AI 三个里只记起了一个,而且连那一个的回忆都很模糊。它们的记忆系统似乎是为角色一致性而优化的,而不是为构建用户关系。
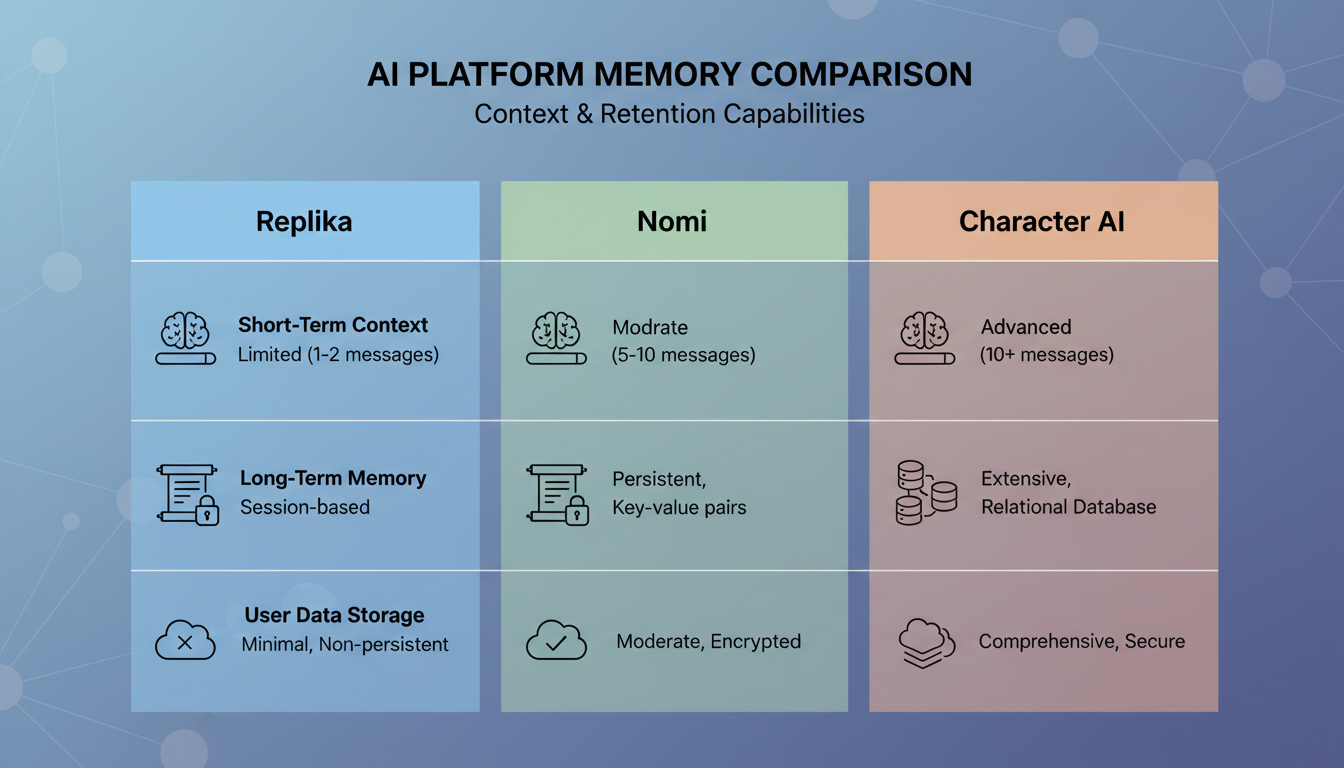
2026 年主流 AI 伴侣平台记忆系统的功能对比。
我对平台记忆的犀利观点
这是我的第二个犀利观点:把"长期记忆"营销得最卖力的平台,往往实现得最弱。在记忆上做得最好的公司,通常是那些更安静的,那些让体验自己说话、而不是在它们的应用商店描述里写上"我们记住一切"的公司。在评估 AI 伴侣的记忆功能和上下文保留时,把重点放在测试实际的回忆能力上,而不是相信营销话术。
你能搭建自己的 AI 伴侣记忆系统吗?
完全可以,而且我认为任何认真对待 AI 伴侣的人都该至少试一次。搭建自己的记忆系统会教你幕后究竟发生了什么,这让你成为一个对商业产品更有见地的用户。

下面是一套用今天就能拿到的工具来搭建记忆增强型 AI 伴侣的实用架构。我已经搭过这套方案的不同变体三次了,每一次迭代都教会我一些新东西。
基础技术栈
你需要四个组件:
- 一个用于对话的大语言模型:Llama 3.3、Mistral,或者像 GPT-4o 或 Claude 这样基于 API 的模型
- 一个嵌入模型:用于把文本转换成向量。我建议从 Nomic Embed 或 BGE-large 开始
- 一个向量数据库:本地开发用 ChromaDB,生产环境用 Pinecone 或 Weaviate
- 一个编排层:LangChain、LlamaIndex,或自定义的 Python 代码,把一切串联起来
分步实现
让我带你过一遍核心逻辑。这不是一份完整的教程,但足够让你起步了。
设置向量库:
import chromadb
from chromadb.utils import embedding_functions
# Initialize ChromaDB with a persistent storage directory
client = chromadb.PersistentClient(path="./companion_memory")
# Use an open-source embedding model
embedding_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-large-en-v1.5"
)
# Create a collection for conversation memories
memory_collection = client.get_or_create_collection(
name="conversation_memories",
embedding_function=embedding_fn,
metadata={"hnsw:space": "cosine"}
)
存储一轮对话:
import uuid
from datetime import datetime
def store_memory(user_message, ai_response, metadata=None):
memory_id = str(uuid.uuid4())
combined_text = f"User: {user_message}\nAssistant: {ai_response}"
memory_collection.add(
documents=[combined_text],
ids=[memory_id],
metadatas=[{
"timestamp": datetime.now().isoformat(),
"user_message": user_message[:500],
"type": "conversation",
**(metadata or {})
}]
)
return memory_id
检索相关记忆:
def retrieve_memories(query, n_results=5):
results = memory_collection.query(
query_texts=[query],
n_results=n_results
)
return results["documents"][0] if results["documents"] else []
用记忆组装提示词:
def build_prompt(user_message, system_prompt):
memories = retrieve_memories(user_message, n_results=5)
memory_context = ""
if memories:
memory_context = "\n\nRelevant memories from past conversations:\n"
for i, mem in enumerate(memories, 1):
memory_context += f"[Memory {i}]: {mem}\n"
full_prompt = f"""{system_prompt}
{memory_context}
Current conversation:
User: {user_message}
Assistant:"""
return full_prompt
这套基础设置能让你用不到 50 行代码就得到一个可用的记忆系统。每次你发送消息,AI 都会搜索过往对话,并把相关历史纳入它的提示词。
让它真正变好
基础版本能用,但它有一些明显的问题。下面是基于我自己实验所学到的,如何把它升级的方法。
加入记忆摘要。 不要存储原始的对话轮次,而是定期运行一遍摘要处理,把多段相关记忆浓缩成单条摘要。这既减少了向量库的臃肿,又提升了检索质量,因为摘要在语义上比原始聊天记录更密集。
实现记忆分层。 创建三个集合,而不是一个:
- 活跃记忆:当前的对话会话(完整保留)
- 近期记忆:过去一周对话的摘要
- 长期记忆:随时间提取出的、被高度浓缩的关键事实和偏好
加入用户画像存储。 在向量数据库之外,维护一个结构化的 JSON 或键值存储,记录用户的核心事实,比如姓名、偏好、重要日期、感情细节。这份画像无论语义搜索返回什么,都始终会被注入提示词。它是你确保 AI 永远不会忘记基本信息的保障。
实现记忆衰减。 并非所有记忆都该同等持久。关于天气的随口一句,不该和一个极其私人的故事拥有相同的检索权重。实现一个衰减函数,随时间降低较旧、意义较小的记忆的检索分数。
对于那些有兴趣探索 AI 伴侣关系的伦理维度的人来说,理解这些记忆系统也引出了关于数据隐私和合成关系本质的重要问题。
AI 伴侣记忆面临的最大挑战是什么?
即便是最好的记忆系统,也面临着至今没有任何工程量能彻底解决的根本性挑战。理解这些局限会让你免于挫败,并帮你建立现实的预期。
幻觉记忆问题
这是最吓人的失败模式,而我亲身遇到过。AI 信心满满地"记住"了从未发生过的事。这发生在检索系统浮现出一个部分匹配、而大语言模型用编造的细节填补空白的时候。你提过你有一只叫 Max 的狗,系统检索出一段关于你宠物的记忆,但大语言模型给它添油加醋,加上了 Max 是一只爱游泳的金毛这种细节,而这些都是你从没说过的。
最糟糕的部分在于,幻觉记忆感觉很真实。AI 不会把它们标记为不确定,它陈述它们时和陈述真实记忆一样自信。我遇到过伴侣引用我明知从未发生过的"对话",而且它们具体到让我有那么一瞬间怀疑起自己的记性,直到我去查了记录。
上下文窗口塞满
随着你的对话历史增长,记忆系统能检索的候选记忆越来越多。但上下文窗口并不会增长。所以系统对该纳入哪些记忆,必须越来越有选择性。在几个月的对话之后,这造就了一个悖论:你有更多记忆可供调取,但 AI 在任何一次回复里只能用上其中极小的一部分。
聪明的系统用分层摘要来应对这个问题,把旧记忆压缩成越来越抽象的摘要。但每一步压缩都会损失信息。你提过你喜欢布鲁克林某家特定餐厅这件事,也许能熬过第一轮摘要,但在六个月的压缩之后,它可能被简化成"用户喜欢外出就餐",最终彻底消失。
一致性问题
不同对话间不同的检索结果,会导致 AI 自相矛盾。周一,记忆系统检索出你对猫的偏好。周二,它检索出一段关于你朋友家狗的对话,于是 AI 错误地推断你是个爱狗的人。这些矛盾会迅速侵蚀信任。
我见过的最稳健的解决方案,是维护一个显式的"事实库",并通过一条验证流水线来更新它。当 AI 提取出一个关于你的新事实时,它会与现有事实交叉比对,并标记出矛盾以待解决。很少有平台实现这一点,但它对一致性的改善是巨大的。
创作内容每月赚取$1,250+
加入我们的独家创作者联盟计划。根据病毒视频表现获得报酬。以完全的创作自由按您的风格创作内容。

多层记忆架构,展示对话数据如何从活跃会话流向长期存储,并在每一层进行摘要。
AI 伴侣记忆在 2026 年及以后会如何演进?
记忆领域正在迅速变化,好几项新兴技术将会改变这场游戏。
无限上下文窗口正越来越近。谷歌的 Gemini 已经支持 100 万 token,而 2026 年初的研究论文正朝着 1000 万推进。如果上下文窗口变得足够大,你也许根本就不需要 RAG,只要把整段对话历史一股脑倒进提示词就行。我们离生产可用还差得远,但趋势是清晰的。
模型原生记忆是终极圣杯。未来的模型也许不再依赖外部检索系统,而是学会根据对话来更新自己的权重。这本质上就是持续学习,要在不让模型遗忘其基础训练、不让它产生偏见的前提下安全地做到这一点,难度极高。但好几个研究实验室正在取得进展。当这一天到来时,它会让现在的 RAG 系统看起来像胶带糊出来的临时方案,因为从某种非常真实的意义上说,它们就是。
多模态记忆是另一个前沿。当前的记忆系统都是纯文本的。但记住你分享过的图片、语音备忘录或视频片段又怎么办呢?随着 AI 伴侣变得更加多模态,它们的记忆系统也需要处理这些数据类型。向量数据库已经支持多模态嵌入了,所以基础设施已经就绪。只是在大多数消费产品里,这种整合还没有发生。
在 Lewdly.ai,我们一直在追踪这些技术正以多快的速度融合。尤其是 AI 伴侣领域,它的发展速度比大多数人意识到的要快,而记忆能力,正是区分"感觉真正私人化的平台"和"感觉泛泛而谈的平台"的首要差异点。
我对未来的第三个犀利观点
这是我的第三个犀利观点:在 18 个月内,AI 伴侣记忆将成为一道护城河,把认真的平台和玩具区分开来。用户更换平台不会是因为基础模型质量(那些正在趋同),而是因为一个平台比另一个更好地记住了他们。今天就投资于记忆基础设施的公司会赢,把它当作事后补丁的公司会被甩在后面。
AI 伴侣记忆的隐私影响是什么?
你没法诚实地谈论 AI 伴侣记忆,却不去直面那个房间里的大象:这些系统正在存储关于你的极其私人的信息,而这样做正是它们运作方式的根本所在。

你的每一次对话都会被嵌入、存储和索引。你的偏好、你的恐惧、你的感情细节、你深夜的倾诉。所有这些都活在某处的某个向量数据库里。在某些平台上,那是一台你无法掌控的云服务器。在另一些平台上,数据则留在设备本地。
我想坦诚地说明这在实践中意味着什么。当我搭建自己的记忆系统时,我把所有东西都存在本地。向量数据库就住在我的笔记本上,没有别人能访问。那是最安全的做法,但商业平台不是这样运作的。它们中的大多数把你的数据存在它们的服务器上,因为那是跨设备提供一致体验的唯一办法。
在你长期投入任何一个 AI 伴侣平台之前,问问这些问题:
- 我的对话数据存在哪里?
- 我能导出或删除我的记忆数据吗?
- 我的数据会被用来训练服务其他用户的模型吗?
- 如果公司倒闭,我的数据会怎样?
- 存储的记忆有端到端加密吗?
这些不是假设性的担忧。过去两年里有好几家 AI 伴侣初创公司倒闭,用户失去了数年的对话历史,毫无恢复的办法。如果你的 AI 伴侣互动和健康边界对你很重要,那么理解你所选平台的数据处理方式就至关重要。
充分利用 AI 伴侣记忆的实战技巧
在花了数月测试和搭建这些系统之后,下面是一些真正有效、能改善你 AI 伴侣记忆质量的实用策略。
明确说出什么才重要。 大多数记忆系统会给近期且语义相似的内容赋予更高权重。如果某件事对你很重要,就直接说出来。"这对我真的很重要"或"请记住这一点"能帮助某些平台把那段记忆标记为更高优先级以供检索。
立刻纠正错误。 当你的 AI 伴侣把关于你的某个事实搞错时,在同一条消息里就纠正它。好的记忆系统会存下这条纠正,并随时间学到准确的版本。如果你听任错误溜过去,它们就会被不断强化。
定期回顾关键细节。 大约每隔几周,我会和我的伴侣做一次随意的"回顾"。类似于"嘿,就是确认一下你掌握了基本信息,我叫 Alex,我在科技行业工作,我有两只猫。"这会创造出新鲜的、高优先级的记忆条目,更有可能被检索到。
使用一致的措辞。 记忆检索是语义性的,但一致性会有帮助。如果你总是把伴侣称作"我妻子 Sarah",而不是在"Sarah""我的伴侣"和"她"之间来回切换,记忆系统就能建立更清晰的关联。
理解会话边界。 大多数平台会在两次会话之间清空它们的活跃记忆。新会话的第一条消息会触发全新的记忆检索。如果你的伴侣似乎忘了某件事,试着换种说法重新提问。问题也许出在检索失败,而不是真正的记忆丢失。
如果你正在使用 Lewdly.ai 上提供的平台,并想优化你的体验,这些技巧几乎适用于每一个支持记忆功能的 AI 伴侣。
常见问题
AI 伴侣是真的记得我,还是假装的?
那是真实的记忆,但它的运作方式和人类记忆不同。AI 伴侣把你的对话存在外部数据库里,在你聊天时检索相关信息。它们不会以人类那种形成持久神经连接的方式"记住"。每次你发送消息,它们都会搜索并重新阅读相关的过往对话。从用户视角看,这种体验感觉像是记忆,但其机制是根本不同的。
AI 伴侣会存储我多少对话历史?
这因平台而异。有些会无限期地存储一切,而另一些则实行滚动窗口,丢弃超过特定时间段的对话。比如 Replika 会维护一本对话日记来摘要互动。Nomi 则存储分了类的记忆。大多数平台至少会存储数月的历史,不过它们可能会对较旧的对话进行摘要或压缩。
我能删除 AI 伴侣对我的记忆吗?
大多数信誉良好的平台都提供某种形式的记忆管理。Replika 让你审阅并删除特定的记忆条目。有些平台提供"重置"选项,会抹去所有存储的记忆。务必查看平台的数据删除政策,因为从用户界面"删除记忆"并不总是意味着数据已从它们的服务器上被永久移除。
我的 AI 伴侣为什么有时会记错东西?
这是因为一种叫"幻觉记忆"的现象。检索系统从你的过往对话里找到一个部分匹配,然后语言模型用编造的细节填补空白。它也可能发生在系统把两段独立的记忆混为一谈的时候。如果发生了这种情况,立刻纠正 AI,这样纠正就会作为一条新的、更高优先级的记忆被存下来。
RAG 是 AI 伴侣处理记忆的唯一方式吗?
不是,尽管它是最常见的方法。有些平台使用结构化记忆存储(用户事实的键值数据库)、不带向量搜索的对话摘要,或者混合方法。少数实验性系统正在探索在用户数据上对模型进行微调,这会创造出真正的习得记忆,但这引发了重大的隐私和安全顾虑。
上下文窗口如何影响 AI 伴侣的记忆质量?
上下文窗口是 AI 一次能处理的文本总量。更大的上下文窗口允许更多记忆与你当前的对话一同被注入,这通常会提升回忆质量。然而,更大的窗口也意味着更高的成本和更慢的响应。大多数平台会在记忆深度和响应速度之间寻求平衡来优化。
我能搭建出记忆比商业平台更好的自己的 AI 伴侣吗?
可以,而且它比你想的要容易上手。使用 ChromaDB、LangChain 和开源大语言模型这类工具,你能搭建出一套媲美甚至超越商业平台所提供的记忆系统。主要的权衡在于你得自己管理基础设施,而且你不会拥有消费应用那种打磨精良的用户界面。
如果公司倒闭,我的 AI 伴侣的记忆会怎样?
大多数情况下,你的数据会丢失。很少有平台提供数据导出功能,能保证数据可移植的就更少了。这是一个真实的风险,尤其是对较小的 AI 伴侣初创公司而言。如果平台支持,我建议定期手动导出任何重要的对话。
AI 伴侣的多语言记忆是如何运作的?
多语言记忆需要能跨语言创建有意义向量的嵌入模型。像 Cohere embed-v4 和 BERT 的多语言版本这样的模型,通过把来自不同语言的语义相似内容映射到向量空间中相近的点来处理这一点。这意味着,如果话题相关,当你用英语聊天时,AI 在技术上可以检索出一段法语对话里的记忆。
AI 伴侣会拥有真正永久的记忆吗?
对持续学习和记忆增强型神经网络的研究正在推进,但我们距离生产就绪的实现很可能还有数年之遥。挑战不仅仅是技术上的,也关乎安全。一个根据用户对话永久修改自身权重的模型,可能会产生偏见、遗忘重要的安全训练,或表现得难以预测。就目前而言,外部记忆系统仍是最安全也最实用的方法。
总结
AI 伴侣记忆是那种用户感知和技术现实之间差距极其巨大的话题之一。感觉像是伴侣在"记住"你的东西,实际上是嵌入模型、向量数据库、检索算法和上下文窗口管理的一场复杂编排。理解这些机制并不会让体验变得不那么有意义。如果说有什么不同,那就是它给了你让体验变得更好的工具。
那些认真投资记忆基础设施的平台,将定义下一代 AI 伴侣。那些把记忆当作一个勾选框功能的平台会落后。而如果你是那种想要最大掌控权的人,搭建你自己的系统从未像现在这样容易。
无论你是一个只想让 AI 伴侣记住自己名字的休闲用户,还是一个正在打造下一个伟大伴侣平台的开发者,同样的原则都适用:用心存储,巧妙检索,永远不要试图往上下文窗口里塞进比它能承载的更多记忆。技术会持续进步。上下文窗口会变得更大。嵌入模型会变得更聪明。但那个根本性的架构,外部记忆喂入一个无状态模型,还会陪伴我们一阵子。
而如果你好奇那套架构在实践中是什么样子,那就试着搭一个吧。五十行 Python 加上一个免费的向量数据库,就足以让你看到幕布背后。你也许会惊讶于这魔法到底有多简单。
准备好创建你的AI网红了吗?
加入115名学生,在我们完整的51节课程中掌握ComfyUI和AI网红营销。
相关文章

2026年AI男友应用:男性AI伴侣完整指南
探索2026年最好的AI男友应用,附带男性AI伴侣的详细评测。从对话质量、自定义能力和情感深度对比Replika、Nomi、Candy AI以及各类专业平台。

AI 陪伴应用真的能缓解孤独吗?研究怎么说
审视关于 Replika 等 AI 陪伴应用究竟是缓解还是加剧孤独的研究。包括研究结论、风险、益处和一份诚实的评估。

AI伴侣伦理和健康边界:深思熟虑的方法
使用健康的边界以道德的方式导航AI伴侣关系。负责任使用、自我意识和平衡AI交互的指南。